目录
How far are we from solving the 2D & 3D Face Alignment problem?
6. Large Scale 3D Faces in-the-Wild dataset
How far are we from solving the 2D & 3D Face Alignment problem?
Adrian Bulat and Georgios Tzimiropoulos Computer Vision Laboratory, The University of Nottingham Nottingham, United Kingdom
官网:https://www.adrianbulat.com/face-alignment
原文地址:https://arxiv.org/pdf/1703.07332.pdf
Abstract
This paper investigates how far a very deep neural network is from attaining close to saturating performance on existing 2D and 3D face alignment datasets. To this end, we make the following 5 contributions:
Training and testing code as well as the dataset can be downloaded from https: //www.adrianbulat.com/face-alignment/ |
本文研究了在现有的二维和三维人脸定位数据集上,一个非常深入的神经网络离达到接近饱和的性能还有多远。为此,我们做出了以下5项贡献:
训练和测试代码以及数据集可从/https: //www.adrianbulat.com/face-alignment/ 下载 |
1. Introduction
| With the advent of Deep Learning and the development of large annotated datasets, recent work has shown results of unprecedented accuracy even on the most challenging computer vision tasks. In this work, we focus on landmark localization, in particular, on facial landmark localization, also known asface alignment, arguably one of the most heavily researched topics in computer vision over the last decades. Very recent work on landmark localization using Convolutional Neural Networks (CNNs) has pushed the boundaries in other domains like human pose estimation [39, 38, 24, 17, 27, 42, 23, 5], yet it remains unclear what has been achieved so far for the case of face alignment. The aim of this work is to address this gap in literature. Historically, different techniques have been used for landmark localization depending on the task in hand. For example, work in human pose estimation, prior to the advent of neural networks, was primarily based on pictorial structures [12] and sophisticated extensions [44, 25, 36, 32, 26] due to their ability to model large appearance changes and accommodate a wide spectrum of human poses. Such methods though have not been shown capable of achieving the high degree of accuracy exhibited by cascaded regression methods for the task of face alignment [11, 8, 43, 50, 41]. On the other hand, the performance of cascaded regression methods is known to deteriorate for cases of inaccurate initialisation, and large (and unfamiliar) facial poses when there is a significant number of selfoccluded landmarks or large in-plane rotations. | 随着深度学习的到来和大型注释数据集的发展,最近的工作已经显示出前所未有的准确性,甚至在最具挑战性的计算机视觉任务的结果。在这项工作中,我们重点关注landmark 定位,特别是面部landmark 定位,也被称为面部对齐,可以说是过去几十年计算机视觉中研究最多的主题之一。最近使用卷积神经网络(CNNs)进行地标定位的工作已经在其他领域如人体姿态估计[39,38,24,17,27,42,23,5]中突破了界限,但目前还不清楚在人脸对齐方面取得了什么进展。这项工作的目的是解决这个差距在文学。历史上,根据手头的任务不同,使用了不同的技术来进行landmark 定位。例如,在神经网络出现之前,人类姿态估计的工作主要基于图像结构[12]和复杂的扩展[44、25、36、32、26],因为它们能够模拟大的外观变化并适应广泛的人类姿态。然而,这种方法还没有被证明能够达到用于面部对准任务的级联回归方法所显示的高度准确性[11,8,43,50,41]。另一方面,在初始化不准确的情况下,级联回归方法的性能会下降,当有大量自聚焦landmark 或大的面内旋转时,会出现较大的(和不熟悉的)面部姿势。 |
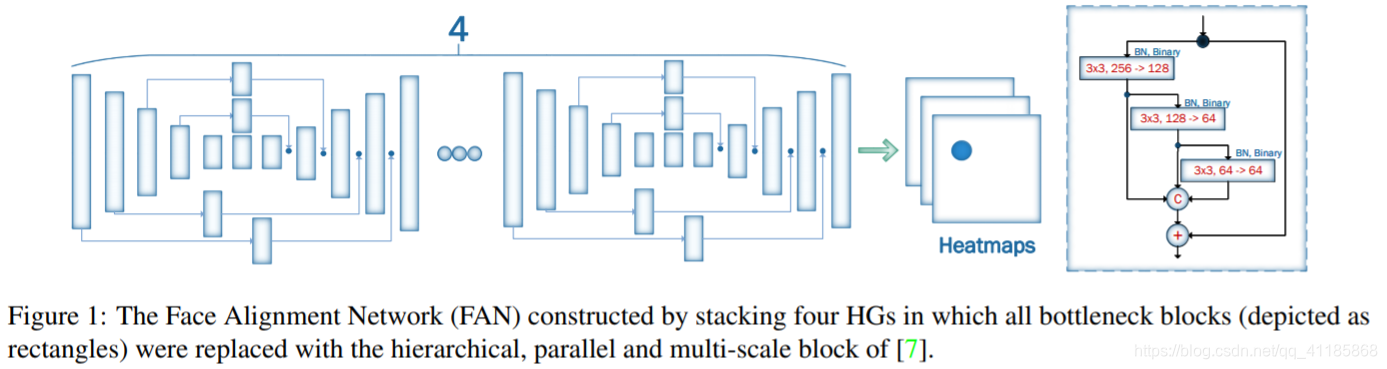
图1:由4个HGs叠加而成的人脸比对网络(FAN),其中所有的瓶颈块(以矩形表示)都被替换为[7]的分层、平行和多尺度块。 |
|
More recently, fully Convolutional Neural Network architectures based on heatmap regression have revolutionized human pose estimation [39, 38, 24, 17, 27, 42, 23, 5] producing results of remarkable accuracy even for the most challenging datasets [1]. Thanks to their end-to-end training and little need for hand engineering, such methods can be readily applied to the problem of face alignment. Following this path, our main contribution is to construct and train such a powerful network for face alignment and investigate for the first time how far it is from attaining close to saturating performance on all existing 2D face alignment datasets and a newly introduced large scale 3D dataset. More specifically, our contributions are:
|
最近,基于热图回归的全卷积神经网络架构已经彻底改变了人体姿态估计[39,38,24,17,27,42,23,5],即使对于最具挑战性的数据集[1]也能产生非常精确的结果。由于他们的端到端训练和很少需要手工程,这种方法可以很容易地应用于面部对准的问题。沿着这条道路,我们的主要贡献是构建和训练这样一个强大的人脸比对网络,并首次研究如何在现有的所有2D人脸比对数据集和新引入的大规模3D数据集上实现接近饱和的性能。更具体地说,我们的贡献是:
|
2. Closely related work
This Section reviews related work on face alignment and landmark localization. Datasets are described in detail in the next Section. 2D face alignment. Prior to the advent of Deep Learning, methods based on cascaded regression had emerged as the state-of-the-art in 2D face alignment, see for example [8, 43, 50, 41]. Such methods are now considered to have largely “solved” the 2D face alignment problem for faces with controlled pose variation like the ones of LFPW [2], Helen [22] and 300-W [30]. We will keep the main result from these works, namely their performance on the frontal dataset of LFPW [2]. This performance will be used as a measure of comparison of how well the methods described in this paper perform assuming that a method achieving a similar error curve on a different dataset is close to saturating that dataset. |
本节回顾了人脸定位和地标定位的相关工作。数据集将在下一节中详细描述。在深度学习出现之前,基于级联回归的方法已经成为二维人脸对准的最新技术,参见[8,43,50,41]。这种方法现在被认为在很大程度上“解决”了具有受控位姿变化的人脸的2D人脸对准问题,比如LFPW[2]、Helen[22]和300-W[30]。 我们将保留这些工作的主要结果,即它们在LFPW[2]的正面数据集上的性能。如果在不同的数据集上实现类似的错误曲线的方法接近于该数据集的饱和状态,那么本文中描述的方法的性能将被用来比较它们的执行情况。 |
CNNs for face alignment. By no means we are the first to use CNNs for face alignment. The method of [35] uses a CNN cascade to regress the facial landmark locations. The work in [47] proposes multi-task learning for joint facial landmark localization and attribute classification. More recently, the method of [40] extends [43] within recurrent neural networks. All these methods have been mainly shown effective for the near-frontal faces of 300-W [30]. Recent works on large pose and 3D face alignment includes [20, 50] which perform face alignment by fitting a 3D Morphable Model (3DMM) to a 2D facial image. The work in [20] proposes to fit a dense 3DMM using a cascade of CNNs. The approach of [50] fits a 3DMM in an iterative manner through a single CNN which is augmented by additional input channels (besides RGB) representing shape features at each iteration. More recent works that are closer to the methods presented in this paper are [4] and [6]. Nevertheless, [4] is evaluated on [20] which is a relatively small dataset (3900 images for training and 1200 for testing) and [6] on [19] which is of moderate size (16,2000 images for training and 4,900 for testing), includes mainly images collected in the lab and does not cover the full spectrum of facial poses. Hence, the results of [4] and [6] are not conclusive in regards to the main questions posed in our paper. Landmark localization. A detailed review of state-ofthe-art methods on landmark localization for human pose estimation is beyond the scope of this work, please see [39, 38, 24, 17, 27, 42, 23, 5]. For the needs of this work, we built a powerful CNN for 2D and 3D face alignment based on two components: (a) the state-of-the-art HourGlass (HG) network of [23], and (b) the hierarchical, parallel & multi-scale block recently proposed in [7]. In particular, we replaced the bottleneck block [15] used in [23] with the block proposed in [7]. |
用于面对齐的CNNs。我们绝不是第一个使用CNNs进行人脸校准的公司。[35]方法利用CNN级联反演面部地标位置。在[47]的工作中,提出了多任务学习联合面部landmark 定位和属性分类。最近,[40]方法在循环神经网络中扩展了[43]。这些方法主要用于300-W[30]的近正面。 最近在大姿态和3D人脸对齐方面的工作包括[20,50],这些工作通过将3D Morphable Model (3DMM)拟合到2D面部图像来进行人脸对齐。在[20]的工作建议适应一个稠密的3DMM使用级联的CNNs。[50]的方法通过一个单独的CNN以迭代的方式对3DMM进行了拟合,在每次迭代中,CNN被表示形状特征的额外输入通道(除了RGB)所增强。更接近本文方法的是[4]和[6]。然而,评估[4]在[20]这是一个相对较小的数据集(培训3900张图片和1200年测试)和[6][19]这是温和的大小(2000图片4900培训和测试),包括在实验室主要是图像采集和不包括面部造成的全谱。因此,对于本文提出的主要问题,[4]和[6]的结果并不是决定性的。 具有里程碑意义的本地化。对用于人体姿态估计的地标定位方法的详细回顾超出了本工作的范围,请参见[39,38,24,17,27,42,23,5]。为了满足这项工作的需要,我们构建了一个强大的基于两个组件的二维和三维人脸校准CNN: (a)[23]的最先进的沙漏(HG)网络,和(b)最近在[7]中提出的分层、并行和多尺度块。特别是,我们用[7]中提出的块替换了[23]中使用的瓶颈块[15]。 |
Transferring landmark annotations. There are a few works that have attempted to unify facial alignment datasets by transferring landmark annotations, typically through exploiting common landmarks across datasets [49, 34, 46]. Such methods have been primarily shown to be successful when landmarks are transferred from more challenging to less challenging images, for example in [49] the target dataset is LFW [16] or [34] provides annotations only for the relatively easy images of AFLW [21]. Hence, the community primarily relies on the unification performed manually by the 300-W challenge [29] which contains less than 5,000 near frontal images annotated from a 2D perspective. Using 300-W-LP [50] as a basis, this paper presents the first attempt to provide 3D annotations for all other datasets, namely AFLW-2000 [50] (2,000 images), 300-W test set [28] (600 images), 300-VW [33] (218,595 frames), and Menpo training set (9,000 images). To this end, we propose a guided-by-2D landmarks CNN which converts 2D annotations to 3D and unifies all aforementioned datasets. |
传输具有里程碑意义的注释。有一些研究试图通过传输地标注释来统一面部定位数据集,通常是通过跨数据集利用共同的地标[49,34,46]。这些方法已经被初步证明是成功的,当地标从更具挑战性的图像转移到不太具有挑战性的图像时,例如在[49]中,目标数据集是LFW[16]或[34]仅为AFLW[21]的相对简单的图像提供注释。因此,社区主要依赖于由300-W挑战[29]手动执行的统一,该挑战包含少于5000张从2D角度注释的近正面图像。 本文以300-W- lp[50]为基础,首次尝试为所有其他数据集提供3D标注,即AFLW-2000[50](2000张图像)、300-W测试集[28](600张图像)、300-VW[33](218595帧)和Menpo训练集(9000张图像)。为此,我们提出了一个二维路标CNN,它可以将二维注解转换为三维,并统一所有上述数据集。 |
3. Datasets
| In this Section, we provide a description of how existing 2D and 3D datasets were used for training and testing for the purposes of our experiments. We note that the 3D annotations preserve correspondence across pose as opposed to the 2D ones and, in general, they should be preferred. We emphasize that the 3D annotations are actually the 2D projections of the 3D facial landmark coordinates but for simplicity we will just call them 3D. In the supplementary material, we present a method for extending these annotations to full 3D. Finally, we emphasize that we performed cross-database experiments only. | 在本节中,我们将描述如何使用现有的2D和3D数据集进行实验目的的培训和测试。我们注意到,与2D注释相比,3D注释保留了各个姿势之间的对应关系,一般来说,它们应该是首选。我们强调,3D标注实际上是3D面部地标坐标的2D投影,但为了简单起见,我们将其称为3D。在补充材料中,我们提出了一种将这些注释扩展到完整3D的方法。最后,我们强调我们只执行跨数据库实验。
|
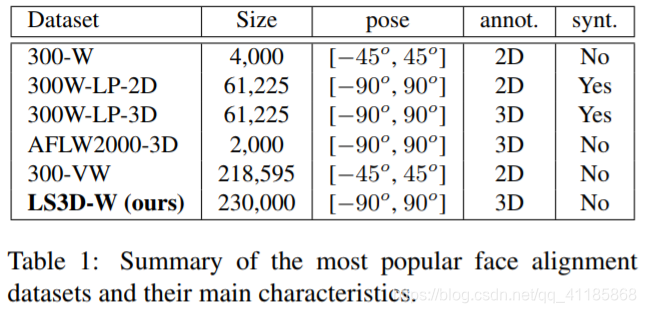
Table 1: Summary of the most popular face alignment datasets and their main characteristics. |
表1:最流行的人脸比对数据集及其主要特征的摘要。 |
3.1. Training datasets
For training and validation, we used 300-W-LP [50], a synthetically expanded version of 300-W [29]. 300-W-LP provides both 2D and 3D landmarks allowing for training models and conducting experiments using both types of annotations. For some 2D experiments, we also used the original 300-W dataset [29] for fine tuning, only. This is because the 2D landmarks of 300-W-LP are not entirely compatible with the 2D landmarks of the test sets used in our experiments (i.e. 300-W test set, [28], 300-VW [33] and Menpo [45]), but the original annotations from 300-W are. 300-W. 300-W [29] is currently the most widely-used inthe-wild dataset for 2D face alignment. The dataset itself is a concatenation of a series of smaller datasets: LFPW [3], HELEN [22], AFW [51] and iBUG [30], where each image was re-annotated in a consistent manner using the 68 2D landmark configuration of Multi-PIE [13]. The dataset contains in total ~4,000 near frontal facial images. 300W-LP-2D and 300W-LP-3D. 300-W-LP is a synthetically generated dataset obtained by rendering the faces of 300-W into larger poses, ranging from −900 to 900 , using the profiling method of [50]. The dataset contains 61,225 images providing both 2D (300W-LP-2D) and 3D landmark annotations (300W-LP-3D). |
为了进行培训和验证,我们使用了300-W- lp[50],这是300-W[29]的综合扩展版本。300-W-LP提供了2D和3D地标,允许使用这两种类型的注释来训练模型和进行实验。对于一些2D实验,我们也仅使用原始的300-W数据集[29]进行微调。这是因为300w - lp的2D landmark与我们实验中使用的测试集(即300w test set, [28], 300vw [33], Menpo[45])的2D landmark并不完全兼容,而300w原始的annotation却兼容。 300 - w。300w[29]是目前野外应用最广泛的二维人脸比对数据集。数据集本身是一系列较小数据集的串联:LFPW[3]、HELEN[22]、AFW[51]和iBUG[30],其中每个图像都使用68个2D地标式多饼[13]重新进行了一致的注释。该数据库共包含近4000张正面人脸图像。300年w-lp-2d和300 w-lp-3d。300w - lp是一个综合生成的数据集,使用[50]的profiling方法,将300w的面渲染成更大的位姿,范围从−900到900。数据集包含61,225张图像,提供2D (300W-LP-2D)和3D地标注释(300W-LP-3D)。 |
3.2. Test datasets
| This Section describes the test sets used for our 2D and 3D experiments. Observe that there is a large number of 2D datasets/annotations which are however problematic for moderately large poses (2D landmarks lose correspondence) and that the only in-the-wild 3D test set is AFLW2000-3D [50] 2 . We address this significant gap in 3D face alignment datasets in Section 6. | 本节描述用于我们的2D和3D实验的测试集。注意,有大量的2D数据集/注释,但是这些数据集/注释对于中等大小的位姿是有问题的(2D地标丢失对应关系),并且唯一的野外3D测试集是AFLW2000-3D[50] 2。我们在第6节中解决了3D人脸对准数据集中的这个重要差距。 |
3.2.1 2D datasets 300-W test set. The 300-W test set consists of the 600 images used for the evaluation purposes of the 300-W Challenge [28]. The images are split in two categories: Indoor and Outdoor. All images were annotated with the same 68 2D landmarks as the ones used in the 300-W data set. 300-VW. 300-VW[33] is a large-scale face tracking dataset, containing 114 videos and in total 218,595 frames. From the total of 114 videos, 64 are used for testing and 50 for training. The test videos are further separated into three categories (A, B, and C) with the last one being the most challenging. It is worth noting that some videos (especially from category C) contain very low resolution/poor quality faces. Due to the semi-automatic annotation approach (see [33] for more details), in some cases, the annotations for these videos are not so accurate (see Fig. 3). Another source of annotation error is caused by facial pose, i.e. large poses are also not accurately annotated (see Fig. 3). Menpo. Menpo is a recently introduced dataset [45] containing landmark annotations for about 9,000 faces from FDDB [18] and ALFW. Frontal faces were annotated in terms of 68 landmarks using the same annotation policy as the one of 300-W but profile faces in terms of 39 different landmarks which are not in correspondence with the landmarks from the 68-point mark-up. |
3.2.1 2 d数据集 300-W测试集。300-W测试集包含用于300-W挑战[28]的评估目的的600张图像。这些图片分为两类:室内和室外。所有的图像都被标注上了与300-W数据集中使用的相同的68个2D地标。300-VW[33]是一个大型的人脸跟踪数据集,包含114个视频,总共218,595帧。在114个视频中,有64个用于测试,50个用于培训。测试视频进一步分为三个类别(A、B和C),最后一个是最具挑战性的。值得注意的是,有些视频(尤其是C类视频)的分辨率很低,质量很差。由于半自动标注方法(详见[33]),在某些情况下,这些视频的标注并不十分准确(见图3)。另一个标注错误的来源是由面部姿态造成的,即大的pose也没有准确的标注(见图3)。Menpo是最近推出的一个数据集[45],其中包含来自FDDB[18]和ALFW的大约9,000个面孔的地标注释。正面脸被标注了68个地标,使用与300-W相同的标注策略,但侧面脸被标注了39个不同的地标,这些地标与68点标记的地标不一致。 |
3.2.2 3D datasets AFLW2000-3D. AFLW2000-3D [50] is a dataset constructed by re-annotating the first 2000 images from AFLW [21] using 68 3D landmarks in a consistent manner with the ones from 300W-LP-3D. The faces of this dataset contain large-pose variations (yaw from −90o to 90o ), with various expressions and illumination conditions. However, some annotations, especially for larger poses or occluded faces are not so accurate (see Fig. 6). |
3.2.2 3 d数据集 AFLW2000-3D。AFLW2000-3D[50]是一个数据集,它使用68个3D地标,以与300W-LP-3D一致的方式重新注释来自AFLW[21]的前2000个图像。该数据集的面包含了较大的姿态变化(从−90o到90o的偏航),具有不同的表达式和光照条件。然而,一些注释,特别是对于较大的姿势或遮挡的面部,并不是很准确(见图6)。 |
3.3. Metrics
Traditionally, the metric used for face alignment is the point-to-point Euclidean distance normalized by the interocular distance [10, 29, 33]. However, as noted in [51], this error metric is biased for profile faces for which the interocular distance can be very small. Hence, we normalize by the bounding box size. In particular, we used the Normalized Mean Error defined as:
where x denotes the ground truth landmarks for a given face, y the corresponding prediction and d is the squareroot of the ground truth bounding box, computed as d = √ wbbox ∗ hbbox. Although we conducted both 2D and 3D experiments, we opted to use the same bounding box definition for both experiments; in particular we used the bounding box calculated from the 2D landmarks. This way, we can readily compare the accuracy achieved in 2D and 3D. |
传统上,用于人脸对齐的度量是点对点欧几里德距离,由眼间距归一化[10,29,33]。然而,正如在[51]中所指出的,这种误差度量对于眼间距可能非常小的侧面是有偏差的。因此,我们通过边界框大小进行规范化。特别地,我们使用归一化平均误差定义为: 其中x为给定人脸的ground truth landmarks, y为相应的预测,d为ground truth绑定框的squareroot,计算为d =√wbbox hbbox。虽然我们同时进行了2D和3D实验,但我们选择对两个实验使用相同的边界框定义;我们特别使用了从2D地标计算出的边界框。这样,我们就可以很容易地比较2D和3D的精度。 |

4. Method
| This Section describes FAN, the network used for 2D and 3D face alignment. It also describes 2D-to-3D FAN, the network used for constructing the very large scale 3D face alignment dataset (LS3D-W) containing more than 230,000 3D landmark annotations. | 本节描述风扇,用于二维和三维人脸对准的网络。它还描述了2D-to-3D FAN,用于构建包含超过230,000个3D地标注释的超大规模3D人脸比对数据集(LS3D-W)的网络。 |
4.1. 2D and 3D Face Alignment Networks We coin the network used for our experiments simply Face Alignment Network (FAN). To our knowledge, it is the first time that such a powerful network is trained and evaluated for large scale 2D/3D face alignment experiments. We construct FAN based on one of the state-of-the-art architectures for human pose estimation, namely the HourGlass (HG) network of [23]. In particularly, we used a stack of four HG networks (see Fig. 1). While [23] uses the bottleneck block of [14] as the main building block for the HG, we go one step further and replace the bottleneck block with the recently introduced hierarchical, parallel and multi-scale block of [7]. As it was shown in [7], this block outperforms the original bottleneck of [14] when the same number of network parameter were used. Finally, we used 300W-LP-2D and 300W-LP-3D to train 2D-FAN and 3DFAN, respectively.
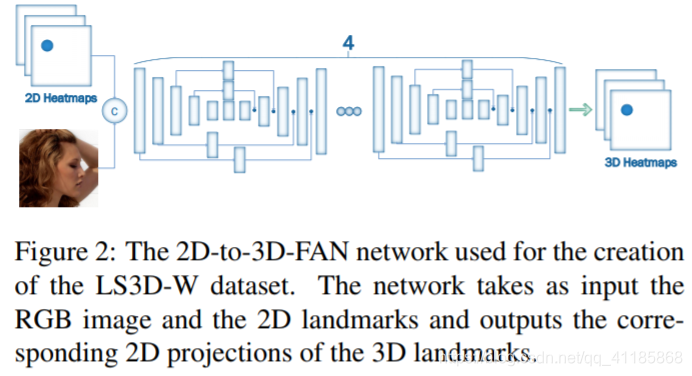
Figure 2: The 2D-to-3D-FAN network used for the creation of the LS3D-W dataset. The network takes as input the RGB image and the 2D landmarks and outputs the corresponding 2D projections of the 3D landmarks. |
4.1。二维和三维人脸对准网络 我们创造了用于我们的实验的网络简单地面对对准网络(风扇)。据我们所知,这是第一次为大规模的二维/三维人脸对准实验训练和评估这样一个强大的网络。 我们基于最先进的人体姿态估计架构之一,即[23]的沙漏(HG)网络来构建风扇。特别地,我们使用了4个HG网络的堆栈(见图1)。当[23]使用[14]的瓶颈块作为HG的主要构建块时,我们更进一步,用最近引入的[7]的分级、并行和多尺度块替换瓶颈块。如[7]所示,当使用相同数量的网络参数时,此块的性能优于[14]的原始瓶颈。最后,我们使用300W-LP-2D和300W-LP-3D分别训练2D-FAN和3DFAN。 图2:用于创建LS3D-W数据集的2D-to-3D-FAN网络。网络以RGB图像和二维地标为输入,输出相应的三维地标的二维投影。 |
4.2. 2D-to-3D Face Alignment Network Our aim is to create the very first very large scale dataset of 3D facial landmarks for which annotations are scarce. To this end, we followed a guided-based approach in which a FAN for predicting 3D landmarks is guided by 2D landmarks. In particular, we created a 3D-FAN in which the input RGB channels have been augmented with 68 additional channels, one for each 2D landmark, containing a 2D Gaussian with std = 1px centered at each landmark’s location. We call this network 2D-to-3D FAN. Given the 2D facial landmarks for an image, 2D-to-3D FAN converts them to 3D. To train 2D-to-3D FAN, we used 300-W-LP which provides both 2D and 3D annotations for the same image. We emphasize again that the 3D annotations are actually the 2D projections of the 3D coordinates but for simplicity we call them 3D. Please see supplementary material for extending these annotations to full 3D. |
4.2。二维到三维人脸对准网络 我们的目标是创建第一个非常大的三维面部地标数据集,其中注释是稀缺的。为此,我们采用了基于指南的方法,其中用于预测3D地标的风扇由2D地标引导。特别地,我们创建了一个3D-FAN,其中输入RGB通道被增加了68个额外通道,每个2D地标一个通道,包含一个2D高斯函数,std = 1px以每个地标的位置为中心。我们称这个网络为2D-to-3D风扇。给定图像的2D面部地标,2D-to-3D FAN将其转换为3D。为了训练2D- To -3D风扇,我们使用了300-W-LP,它为相同的图像提供了2D和3D注释。我们再次强调,3D标注实际上是3D坐标的2D投影,但为了简单起见,我们称它们为3D。请参阅补充材料扩展这些注释到完整的3D。 |
4.3. Training
| For all of our experiments, we independently trained three distinct networks: 2D-FAN, 3D-FAN, and 2D-to-3DFAN. For the first two networks, we set the initial learning rate to 10−4 and used a minibatch of 10. During the process, we dropped the learning rate to 10−5 after 15 epochs and to 10−6 after another 15, training for a total of 40 epochs. We also applied random augmentation: flipping, rotation (from −50o to 50o ), color jittering, scale noise (from 0.8 to 1.2) and random occlusion. The 2D-to-3D-FAN model was trained by following a similar procedure increasing the amount of augmentation even further: rotation (from −70o to 70o ) and scale (from 0.7 to 1.3). Additionally, the learning rate initially was set to 10−3 . All networks were implemented in Torch7 [9] and trained using rmsprop [37]. | 在我们所有的实验中,我们独立地训练了三个不同的网络:2D-FAN、3D-FAN和2D-to-3DFAN。对于前两个网络,我们将初始学习率设置为10−4,并使用10个小批。在这个过程中,我们在15个时点之后将学习率降低到10 - 5,在15个时点之后将学习率降低到10 - 6,总共训练了40个时点。我们还应用了随机增强:翻转、旋转(从−50o到50o)、颜色抖动、尺度噪声(从0.8到1.2)和随机遮挡。2D-to-3D-FAN模型按照类似的程序进行训练,进一步增加增加量:旋转(从−70o到70o)和缩放(从0.7到1.3)。此外,学习速率最初设置为10−3。所有网络在Torch7[9]中实现,使用rmsprop[37]进行训练。 |
5. 2D face alignment
This Section evaluates 2D-FAN (trained on 300-W-LP2D), on 300-W test set, 300-VW (both training and test sets), and Menpo (frontal subset). Overall, 2D-FAN is evaluated on more than 220,000 images. Prior to reporting our results, the following points need to be emphasized:
Figure 3: Fittings with the highest error from 300-VW (NME 6.8-7%). Red: ground truth. White: our predictions. In most cases, our predictions are more accurate than the ground truth. |
本节评估2D-FAN(在300-W- lp2d上进行训练)、300-W测试集、300-VW(包括训练和测试集)和Menpo(正面子集)。总的来说,2D-FAN在超过22万张图片上进行了评估。在报告我们的结果之前,需要强调以下几点:
图3:300-VW的配件误差最大(NME 6.8-7%)。红色:地面真理。白:我们的预测。在大多数情况下,我们的预测比事实更准确。 |
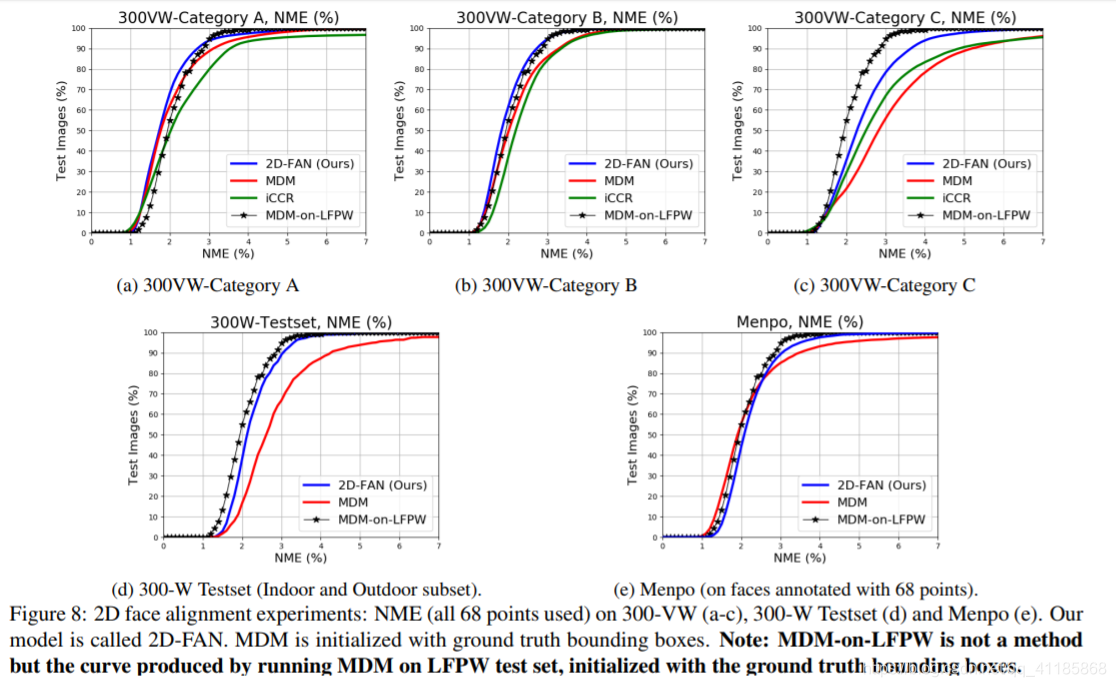
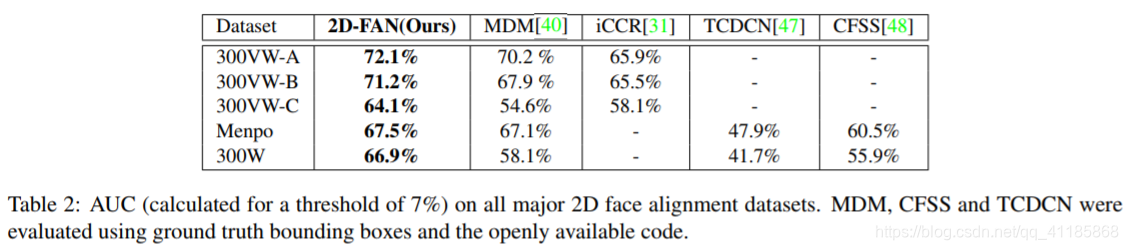
The cumulative error curves for our 2D experiments on 300-VW, 300-W test set and Menpo are shown in Fig. 8. We additionally report the performance of MDM on all datasets initialized by ground truth bounding boxes, ICCR, the stateof-the-art face tracker of [31], on 300-VW (the only tracking dataset), and our unconventional baseline (called MDMon-LFPW). Comparison with a number of methods in terms of AUC are also provided in Table 2. With the exception of Category C of 300-VW, it is evident that 2D-FAN achieves literally the same performance on all datasets, outperforming MDM and ICCR, and, notably, matching the performance of MDM-on-LFPW. Out of 7,200 images (from Menpo and 300-W test set), there are in total only 18 failure cases, which represent 0.25% of the images (we consider a failure a fitting with NME > 7%). After removing these cases, the 8 fittings with the highest error for each dataset are shown in Fig. 4.
Figure 4: Fittings with the highest error from 300-W test set (first row) and Menpo (second row) (NME 6.5-7%). Red: ground truth. White: our predictions. In most cases, our predictions are more accurate than the ground truth. |
我们在300vw、300w和Menpo上进行的二维实验累积误差曲线如图8所示。此外,我们还报告了MDM在所有数据集上的性能,这些数据集由ground truth包围盒(ICCR,[31]的最先进的面跟踪器)在300-VW(唯一的跟踪数据集)上初始化,以及我们的非常规基线(称为MDMon-LFPW)。表2还提供了在AUC方面与一些方法的比较。 除了300-VW的C类,2D-FAN在所有数据集上的性能都是一样的,优于MDM和ICCR,特别是在性能上与MDM-on- lfpw相当。在7200张图像(来自Menpo和300-W测试集)中,总共只有18张失败案例,占图像的0.25%(我们认为失败是与NME > 7%的拟合)。去除这些情况后,每个数据集误差最大的8个配件如图4所示。 图4:在300-W的测试装置(第一行)和门珀(第二行)(NME 6.5-7%)中,误差最大的配件。红色:地面真理。白:我们的预测。在大多数情况下,我们的预测比事实更准确。
|
| Regarding the Category C of 300-VW, we found that the main reason for this performance drop is the quality of the annotations which were obtained in a semi-automatic manner. After removing all failure cases (101 frames representing 0.38% of the total number of frames), Fig. 3 shows the quality of our predictions vs the ground truth landmarks for the 8 fittings with the highest error for this dataset. It is evident that in most cases our predictions are more accurate. Conclusion: Given that 2D-FAN matches the performance of MDM-on-LFPW, we conclude that 2D-FAN achieves near saturating performance on the above 2D datasets. Notably, this result was obtained by training 2D-FAN primarily on synthetic data, and there was a mismatch between training and testing landmark annotations. | 对于300-VW的C类,我们发现性能下降的主要原因是半自动获得的标注质量问题。在删除了所有的失败案例(101帧代表所有帧数的0.38%)之后,图3显示了我们的预测的质量与该数据集的8个误差最大的装置的地面真实地标。很明显,在大多数情况下,我们的预测更准确。结论:在2D- fan性能与MDM-on-LFPW匹配的情况下,我们认为2D- fan在上述2D数据集上的性能接近饱和。值得注意的是,这一结果主要是基于合成数据对2D-FAN进行训练得到的,训练与测试地标标注之间存在不匹配。 |


6. Large Scale 3D Faces in-the-Wild dataset
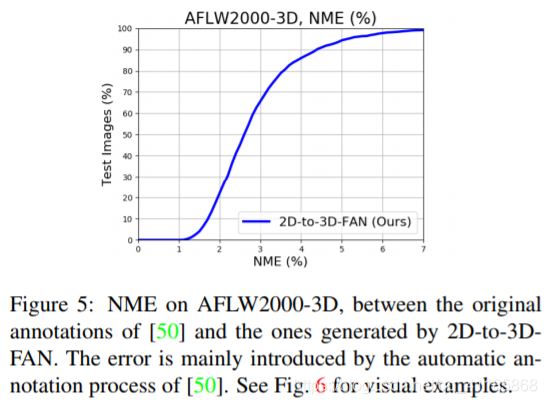
Motivated by the scarcity of 3D face alignment annotations and the remarkable performance of 2D-FAN, we opted to create a large scale 3D face alignment dataset by converting all existing 2D face alignment annotations to 3D. To this end, we trained a 2D-to-3D FAN as described in Subsection 4.2 and guided it using the predictions of 2D-FAN, creating 3D landmarks for: 300-W test set, 300-VW (both training and all 3 testing datasets), Menpo (the whole dataset). Evaluating 2D-to-3D is difficult: the only available 3D face alignment in-the-wild dataset (not used for training) is AFLW2000-3D [50]. Hence, we applied our pipeline (consisting of applying 2D-FAN for producing the 2D landmarks and then 2D-to-3D FAN for converting them to 3D) on AFLW2000-3D and then calculated the error, shown in Fig. 5 (note that for normalization purposes, 2D bounding box annotations are still used). The results show that there is discrepancy between our 3D landmarks and the ones provided by [50]. After removing a few failure cases (19 in total, which represent 0.9% of the data), Fig. 6 shows 8 images with the highest error between our 3D landmarks and the ones of [50]. It is evident, that this discrepancy is mainly caused from the semi-automatic annotation pipeline of [50] which does not produce accurate landmarks especially for images with difficult poses. |
由于3D人脸对齐注释的稀缺性和2D- fan的卓越性能,我们选择通过将所有现有的2D人脸对齐注释转换为3D来创建一个大规模的3D人脸对齐数据集。为此,我们按照4.2小节的描述培训了一个2D-to-3D风扇,并使用2D-FAN的预测指导它,创建了3D地标:300-W测试集、300-VW(包括培训和所有3个测试数据集)、Menpo(整个数据集)。 评估2D-to-3D是困难的:野外唯一可用的3D人脸对准数据集(不用于培训)是AFLW2000-3D[50]。因此,我们在AFLW2000-3D上应用了我们的管道(包括应用2D-FAN生成2D地标,然后应用2D-to-3D FAN将它们转换成3D),然后计算了误差,如图5所示(注意,出于规范化目的,仍然使用2D包围框注释)。结果表明,我们的三维地标与[50]提供的有差异。在排除了一些失败案例(总共19个,占数据的0.9%)之后,图6显示了8张我们的3D地标和[50]的地标之间的误差最大的图像。很明显,这一差异主要是由于[50]的半自动标注流水线无法生成准确的地标,特别是对于姿态困难的图像。 |
Table 2: AUC (calculated for a threshold of 7%) on all major 2D face alignment datasets. MDM, CFSS and TCDCN were evaluated using ground truth bounding boxes and the openly available code. 表2:所有主要的2D人脸比对数据集的AUC(阈值为7%)。MDM、CFSS和TCDCN使用ground truth包围盒和公开可用的代码进行评估。
Figure 5: NME on AFLW2000-3D, between the original annotations of [50] and the ones generated by 2D-to-3DFAN. The error is mainly introduced by the automatic annotation process of [50]. See Fig. 6 for visual examples. Figure 6: Fittings with the highest error from AFLW2000- 3D (NME 7-8%). Red: ground truth from [50]. White: predictions of 2D-to-3D-FAN. In most cases, our predictions are more accurate than the ground truth. 图5:AFLW2000-3D上的NME,在[50]的原始注释和2D-to-3DFAN生成的注释之间。误差主要是由[50]的自动标注过程引起的。图6为可视化示例。 图6:装具误差最高的AFLW2000- 3D (NME 7-8%)。红色:地面真相来自[50]。白色:2d - 3d风扇的预测。在大多数情况下,我们的预测比事实更准确。 |
|
| By additionally including AFLW2000-3D into the aforementioned datasets, overall, ~230,000 images were annotated in terms of 3D landmarks leading to the creation of the Large Scale 3D Faces in-the-Wild dataset (LS3D-W), the largest 3D face alignment dataset to date. | 通过将AFLW2000-3D添加到上述数据集中,总的来说,约23万张图像被标注了3D地标,从而创建了迄今为止最大的3D人脸比对数据集——野外大型3D人脸数据集(LS3D-W)。 |

7. 3D face alignment
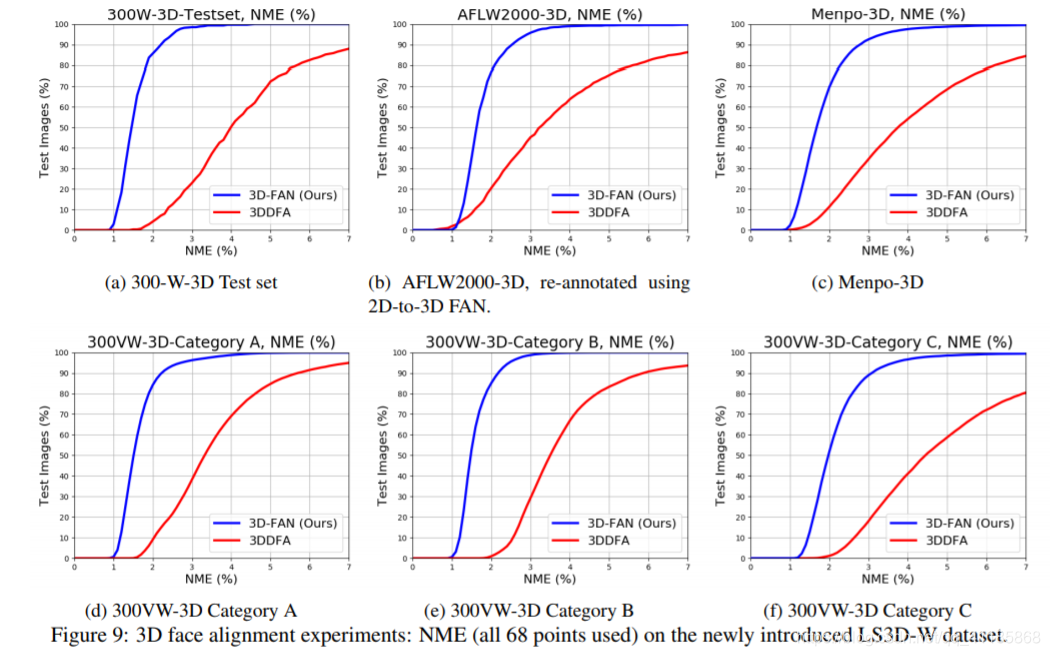
| This Section evaluates 3D-FAN trained on 300-W-LP3D, on LS3D-W (described in the previous Section) i.e. on the 3D landmarks of the 300-W test set, 300-VW (both training and test sets), and Menpo (the whole dataset) and AFLW2000-3D (re-annotated). Overall, 3D-FAN is evaluated on ~230,000 images. Note that compared to the 2D experiments reported in Section 5, more images in large poses have been used as our 3D experiments also include AFLW2000-3D and the profile images of Menpo (~2000 more images in total). The results of our 3D face alignment experiments on 300-W test set, 300-VW, Menpo and AFLW2000-3D are shown in Fig. 9. We additionally report the performance of the state-of-the-art method of 3DDFA (trained on the same dataset as 3D-FAN) on all datasets. Conclusion: 3D-FAN essentially produces the same accuracy on all datasets largely outperforming 3DDFA. This accuracy is slightly increased compared to the one achieved by 2D-FAN, especially for the part of the error curve for which the error is less than 2% something which is not surprising as now the training and testing datasets are annotated using the same mark-up. | 真实感三维人脸对齐 本节将评估3D- fan在300-W- lp3d、LS3D-W(在前一节中描述)上的训练,即在300-W测试集、300-VW(包括训练和测试集)、Menpo(整个数据集)和AFLW2000-3D(重新注释)上的3D地标上的训练。总的来说,3D-FAN在大约23万张图像上进行了评估。注意,与第5节报道的2D实验相比,我们的3D实验使用了更多的大位姿图像,包括AFLW2000-3D和Menpo的profile images(总共多了约2000张图像)。我们在300w试验台上、300vw、Menpo和AFLW2000-3D上进行的三维人脸对准实验结果如图9所示。此外,我们还报告了3DDFA(在与3D-FAN相同的数据集上训练)的最新方法在所有数据集上的性能。结论:3D-FAN在所有数据集上产生的准确性基本上都优于3DDFA。与2D-FAN相比,这种精度略有提高,特别是对于误差小于2%的误差曲线部分,这并不奇怪,因为现在训练和测试数据集都使用相同的标记进行注释。 |
8. Ablation studies
| To further investigate the performance of 3D-FAN under challenging conditions, we firstly created a dataset of 7,200 images from LS3D-W so that there is an equal number of images in yaw angles [0o − 30o ], [30o − 60o ] and [60o − 90o ]. We call this dataset LS3D-W Balanced. Then, we conducted the following experiments: | 为了进一步研究3D-FAN在复杂条件下的性能,我们首先创建了一个包含来自LS3D-W的7200张图像的数据集,以便在偏航角[0o−30o]、[30o−60o]和[60o−90o]有相同数量的图像。我们称这个数据集为LS3D-W平衡。然后,我们进行了以下实验: |
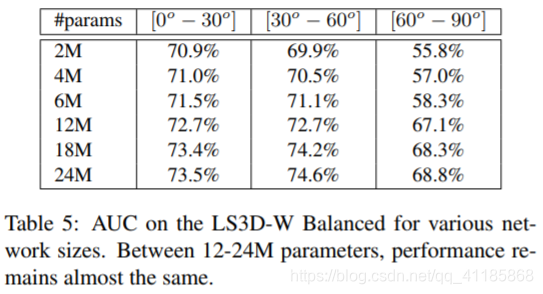
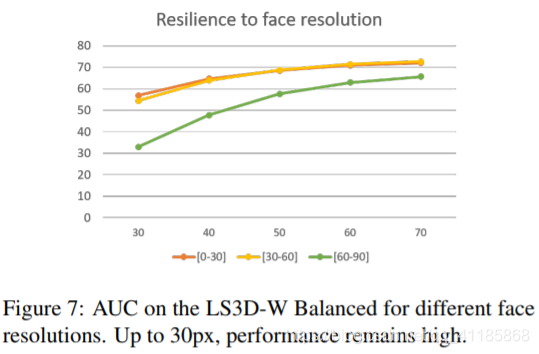
Table 3: AUC (calculated for a threshold of 7%) on the LS3D-W Balanced for different yaw angles. Table 4: AUC on the LS3D-W Balanced for different levels of initialization noise. The network was trained with a noise level of up to 20%. Table 5: AUC on the LS3D-W Balanced for various network sizes. Between 12-24M parameters, performance remains almost the same. Figure 7: AUC on the LS3D-W Balanced for different face resolutions. Up to 30px, performance remains high. 表3:不同偏航角度下LS3D-W平衡时的AUC(阈值为7%)。 表4:在不同初始化噪声水平下,LS3D-W上的AUC平衡。该网络在20%的噪音水平下进行训练。 表5:LS3D-W上的AUC为各种网络大小而平衡。在12-24M参数之间,性能几乎保持不变。 图7:在LS3D-W上的AUC为不同的面分辨率而平衡。高达30px,性能仍然很高。 |
|
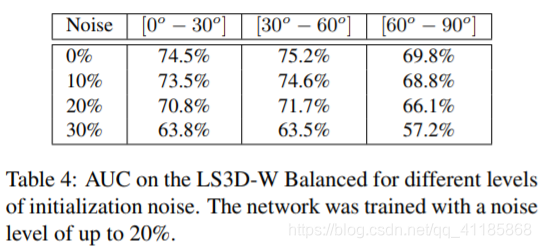
Performance across pose. We report the performance of 3D-FAN on LS3D-W Balanced for each pose separately in terms of the Area Under the Curve (AUC) (calculated for a threshold of 7%) in Table 3. We observe only a slight degradation of performance for very large poses ([60o − 90o ]). We believe that this is to some extent to be expected as 3D-FAN was largely trained with synthetic data for these poses (300-W-LP-3D). This data was produced by warping frontal images (i.e. the ones of 300-W) to very large poses which causes face distortion especially for the face region close to the ears. Conclusion: Facial pose is not a major issue for 3D-FAN. Performance across resolution. We repeated the previous experiment but for different face resolutions (resolution is reduced relative to the face size defined by the tight bounding box) and report the performance of 3D-FAN in terms of AUC in Fig. 7. Note that we did not retrain 3D-FAN to particularly work for such low resolutions. We observe significant performance drop for all poses only when the face size is as low as 30 pixels. Conclusion: Resolution is not a major issue for 3D-FAN. Performance across noisy initializations. For all reported results so far, we used 10% of noise added to the ground truth bounding boxes. Note that 3D-FAN was trained with noise level of 20%. Herein, we repeated the previous experiment but for different noise levels and report the performance of 3D-FAN in terms of AUC in Table 4. We observe only small performance decrease for noise level equal to 30% which is greater than the level of noise that the network was trained with. Conclusion: Initialization is not a major issue for 3D-FAN. |
在构成性能。根据曲线下面积(AUC)(阈值为7%),我们报告了3D-FAN在LS3D-W上的表现。我们只观察到在非常大的位姿([60o - 90o])下性能有轻微的下降。我们认为这在某种程度上是可以预期的,因为3D-FAN主要是使用这些姿势的合成数据进行训练的(300-W-LP-3D)。这些数据是通过将正面图像(即300-W的图像)扭曲成非常大的姿态产生的,这会导致面部变形,尤其是靠近耳朵的面部区域。 结论:面部姿势不是3d风扇的主要问题。 在分辨率性能。我们重复了之前的实验,但是对于不同的人脸分辨率(分辨率相对于紧边界框定义的人脸尺寸减小),并在图7中以AUC的形式报告了3D-FAN的性能。请注意,我们并没有对3D-FAN进行再培训,使其特别适合如此低分辨率的工作。我们观察到,只有当面部尺寸低至30像素时,所有姿势的表现才会显著下降。 结论:解决问题并不是3D-FAN的主要问题。 跨有噪声的初始化的性能。对于到目前为止所有报告的结果,我们使用10%的噪音添加到地面真实边界框。注意3D-FAN的训练噪音等级为20%。在此,我们重复了之前的实验,但是在不同的噪声水平下,我们用AUC来报告3D-FAN的性能如表4所示。我们观察到,当噪声水平大于网络训练时的噪声水平时,当噪声水平等于30%时,系统的性能只有很小的下降。 结论:初始化不是3D-FAN的主要问题。
|
| Performance across different network sizes. For all reported results so far, we used a very powerful 3D-FAN with 24M parameters. Herein, we repeated the previous experiment varying the number of network parameters and report the performance of 3D-FAN in terms of AUC in Table 5. The number of parameters is varied by firstly reducing the number of HG networks used from 4 to 1. Then, the number of parameters was dropped further by reducing the number of channels inside the building block. It is important to note that even then biggest network is able to run on 28-30 fps on a TitanX GPU while the smallest one can reach 150 fps. We observe that up to 12M, there is only a small performance drop and that the network’s performance starts to drop significantly only when the number of parameters becomes as low as 6M. Conclusion: There is a moderate performance drop vs the number of parameters of 3D-FAN. We believe that this is an interesting direction for future work. | 跨不同网络大小的性能。到目前为止,所有报告的结果,我们使用了一个非常强大的24米参数的3d风扇。在此,我们重复了之前的实验,改变网络参数的个数,并以AUC的形式报告了3D-FAN的性能如表5所示。参数的数量是变化的,首先减少使用的4到1的HG网络的数量。然后,通过减少构建块内的通道数量进一步减少参数的数量。值得注意的是,即使是最大的网络也可以在TitanX GPU上运行28-30帧每秒,而最小的可以达到150帧每秒。我们观察到,在高达12M的情况下,只有很小的性能下降,并且只有当参数的数量低至6M时,网络的性能才开始显著下降。结论:随着3D-FAN参数的增加,性能有一定程度的下降。我们认为这是未来工作的一个有趣的方向。 |

9. Conclusions
| We constructed a state-of-the-art neural network for landmark localization, trained it for 2D and 3D face alignment, and evaluate it on hundreds of thousands of images. Our results show that our network nearly saturates these datasets, showing also remarkable resilience to pose, resolution, initialization, and even to the number of the network parameters used. Although some very unfamiliar poses were not explored in these datasets, there is no reason to believe, that given sufficient data, the network does not have the learning capacity to accommodate them, too. | 我们构建了一个最先进的用于地标定位的神经网络,对其进行了二维和三维人脸对准训练,并对数十万张图像进行了评估。我们的结果表明,我们的网络几乎饱和了这些数据集,在姿态、分辨率、初始化,甚至使用的网络参数的数量方面也表现出了显著的弹性。虽然在这些数据集中没有探索一些非常不熟悉的姿势,但没有理由相信,给定足够的数据,网络也不具备容纳它们的学习能力。 |
10. Acknowledgments
| Adrian Bulat was funded by a PhD scholarship from the University of Nottingham. This work was supported in part by the EPSRC project EP/M02153X/1 Facial Deformable Models of Animals. | Adrian Bulat获得了诺丁汉大学的博士奖学金。该工作部分得到了EPSRC项目EP/M02153X/1面部可变形动物模型的支持。 |