
文章要点


🍺前言 💦(一)利用pandas对数据求和,算平均数
💦(一)利用pandas对数据求和,算平均数
💨1. 在excel表格中实现
结果:
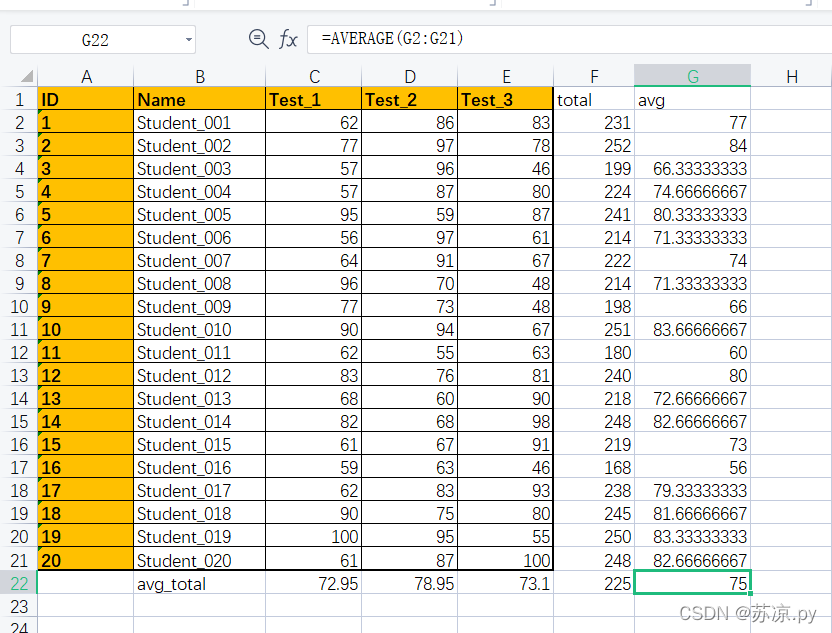
需要完成以上结果在pandas中又如何实现呢?
💨2.在pandas中进行实现
import pandas as pd test = pd.read_excel('./excel/test008.xlsx',index_col="ID") df = pd.DataFrame(test) # 求总和 sum = df[['Test_1','Test_2','Test_3']].sum(axis=1) # 求平均值 avg = df[['Test_1','Test_2','Test_3']].mean(axis=1) df['total'] = sum df['avg'] = avg # 求总计的平均值 T_avg = df[['Test_1','Test_2','Test_3','total','avg']].mean() T_avg['Name'] = 'avg_total' df =df.append(T_avg,ignore_index=True) print(df)
 结果:
结果:
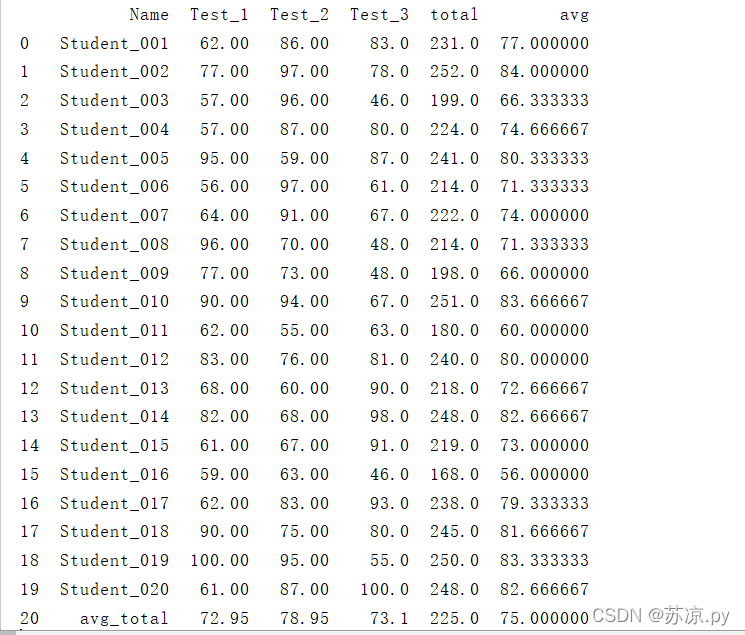
这样就实现了上述结果。
💦(二)消除重复数据
💨1.在excel中进行实现
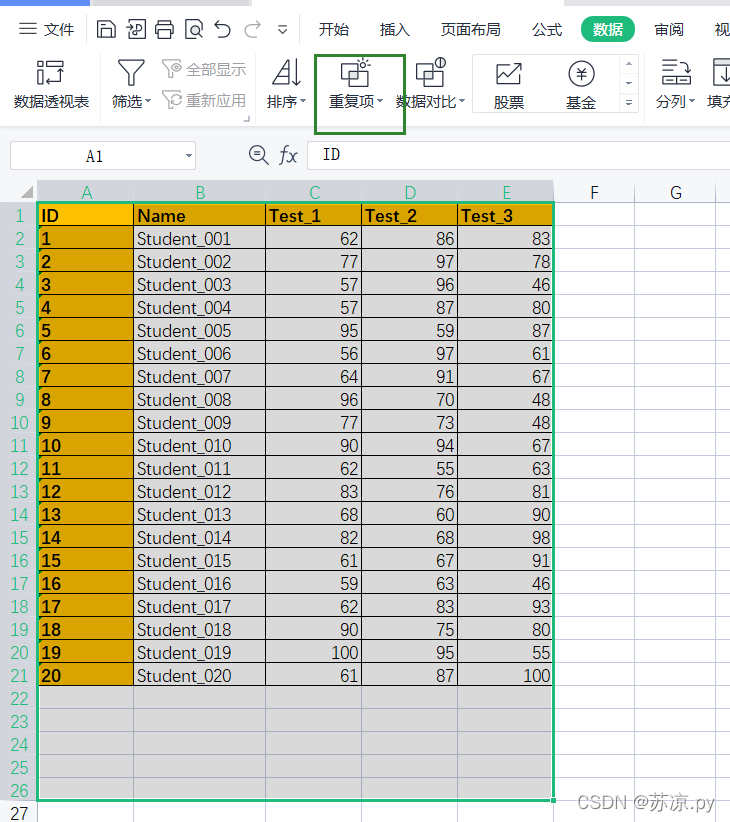
需要实现以上结果,在pandas中要如何进行操作呢?pandas还有什么强大的功能呢,让我们一起来看看吧!
💨2.在pandas中实现
import pandas as pd test = pd.read_excel('./excel/test009.xlsx') df = pd.DataFrame(test) # 消除重复数据 df.drop_duplicates(subset='Name',inplace=True,keep='last') print(df)
结果:
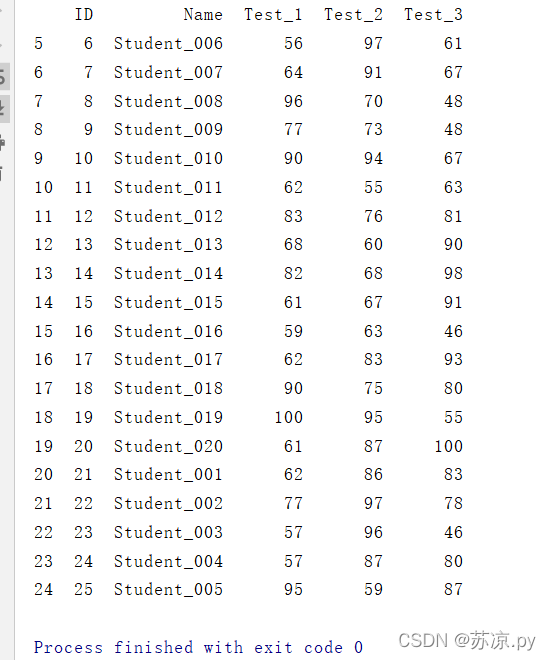
利用keep参数我们将前面重复的数据删除而保留了后面的数据,这就是pandas对比excel的一强大之处。而在此方面,pandas远不止于此,pandas还可以将重复的数据筛选出来。
💫2.1 利用pandas将重复的数据筛选出来
import pandas as pd test = pd.read_excel('./excel/test009.xlsx') df = pd.DataFrame(test) re = df.duplicated(subset='Name') # 找出重复项 re = re[re == True] # re.index 找出重复数据的索引 print(df.iloc[re.index])
结果:
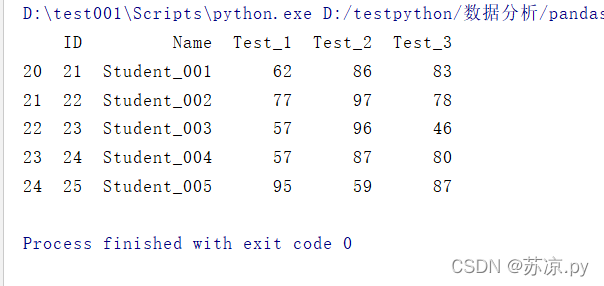
对上面两点,足以说明pandas在对excel数据进行操作时还是比excel更胜一筹的。
💦(三)数据转置在excel表中,有些数据需要转置看起来才更明了,更直观。那么在excel和pandas中要如何操作呢?
实例:将下列数据进行转置
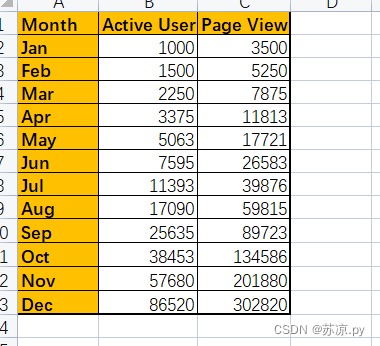
💨1.在excel中进行实现
结果:

那在pandas中又如何操作呢?是否更快捷更简单呢?
💨2.在pandas中进行操作结果:

import pandas as pd test = pd.read_excel('./excel/test010.xlsx',index_col="Month") df = pd.DataFrame(test) # 将数据转置 table = df.transpose() # 显示所有数据,若不设置则中间数据不显示 pd.options.display.max_columns = 100 print(table)
结果:
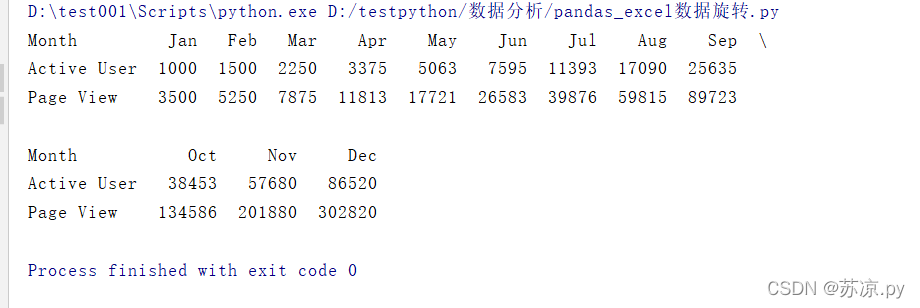
这样就实现了上述结果,pandas相对来说处理数据更方便快捷!!
🍻结语
今天的内容就到这里啦,希望看到此文的小伙伴能有所收获,另外pandas在excel中还有很多操作需要探索,关注我,咱们下期再见!!



