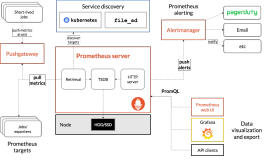
监控指标一览
Hologres管理控制台的监控告警页面,为您提供了实例的资源管理服务。您可以在该页面查看当前实例的资源使用及SQL语句的执行情况,及时识别系统报错并处理实例异常。
监控指标报包括:
1、CPU使用率(%):指实例的CPU综合使用率。Hologres的计算资源采用预留模式,即使没有执行查询操作,后台也会存在运行的进程,此时CPU使用率不为零属于正常现象。同时Hologres可以充分发挥CPU多核并行计算的能力。通常,单个查询可以迅速将CPU使用率提高至100%,这表明计算资源得到了充分利用。但是CPU长期100%表明实例负载较高
2、内存使用率(%):指实例的内存综合使用率。Hologres的内存资源采用预留模式,即使没有执行查询操作,也会有部分Meta或Index元数据加载到内存中,该类元数据用于提升计算速度。此时,在不存在查询的情况下,内存使用率可能会达到30%~40%左右,属于正常现象。如果内存使用率持续升高,甚至接近100%,表明实例负载较高。
说明:Hologres是分布式系统,一个实例有多个节点,一个节点的内存上限是64G,内存通常会分为3个部分:计算,元数据和缓存。
3、实例存储用量(字节):指实例存储的数据占用逻辑磁盘的大小,是所有DB存储用量的总和。如果您是使用包年包月付费模式购买实例,则存储资源的额度使用完后,超出部分会自动转为按量计费。请在超出存储规格后及时扩容存储
4、连接数(个):指实例中总的SQL连接数,包括active及idle状态的JDBC或PSQL连接。实例的默认连接数通常与实例的规格有关,具体的规格说明,请参见实例规格概述。
5、QPS(个/秒):QPS指平均每秒执行SELECT、INSERT、UPDATE或DELETE 4种SQL语句的次数。该指标每20秒上报一次,如果20秒内仅执行了一条SQL语句,则SQL语句的QPS将在该20秒的数据点显示1/20=0.05。
6、Query延迟(毫秒):Query延迟指执行SELECT、INSERT、UPDATE或DELETE 4种SQL语句的平均延迟(即响应时间)。您可以通过慢Query日志查看与分析Query延迟。
7、实时导入RPS(记录/秒):实时导入RPS指每秒通过SQL语句或SDK方式导入或更新的数据记录条数。
1)Insert RPS表示使用外部表批量导入、使用COPY语句批量导入或Hologres表间插入数据的导入速率。
2)Update RPS表示通过执行更新或删除SQL语句,每秒更新或删除的记录条数。
3)SDK RPS表示通过SDK方式写入Hologres的每秒数据写入或更新的条数。SDK方式包括:
- 通过Flink写入。
- 通过Holo Client读写数据。
- 写入Spark的数据至Hologres。
- 实时同步DataHub的数据至Hologres。
- 通过数据集成DataX离线写入。
- SQL或JDBC 通过
insert into values ()语句写入。
8、IO吞吐(字节/秒):该指标描述实例的读写数据量,反映实例的读写繁忙程度。您可以从I/O层面了解实例的压力情况和负载变化,及时诊断问题。
连接过多怎么查看有哪些连接以及怎么kill连接?
连接数包括实例中总的SQL连接数,包括active、idle状态的JDBC/PSQL等连接。实例的连接数通常与实例的规格有关,如果您发现连接数过多,甚至达到超出max_connections的地步,或者遇到如下错误之一:
产生FATAL: sorry, too many clients already connection limit exceeded for superusers报错。 产生FATAL: remaining connection slots are reserved for non-replication superuser connections报错。
说明实例连接数已达上限,意味着您需要检查您的实例是否存在连接数泄漏情况。通过HoloWeb,在活跃连接管理页面,可以对不符合预期或者Idle连接进行Kill操作,详情请参见HoloWeb可视化管理连接。
说明 Superuser账号可以看到实例全部连接。其余用户只能看到自己的连接
延迟过高怎么查看慢query以及怎么降低延迟?
通过在HoloWeb诊断与优化模块的历史慢Query页面可视化查看慢Query,详情请参见慢Query日志查看与分析。
常见降低查询延迟的方法如下:
- 让写入在查询低峰期进行,或者降低写入的并发度,提高查询效率,如果是外表写入,可以使用以下参数降低并发度。
--设置MaxCompute执行的最大并发度,默认为128,建议数值设置小一些,避免一个Query影响其他Query,导致系统繁忙导致报错。 set hg_experimental_foreign_table_executor_max_dop = 32; --优先考虑设置 --调整每次读取MaxCompute表batch的大小,默认8192。 set hg_experimental_query_batch_size = 1024; --直读orc set hg_experimental_enable_access_odps_orc_via_holo = on; --设置MaxCompute表访问切分spilit的数目,可以调节并发数目,默认64MB,当表很大时需要调大,避免过多的split影响性能。 set hg_experimental_foreign_table_split_size = 512MB;
怎么看正在运行的任务?
通过在HoloWeb诊断与优化模块的活跃Query页面可视化查看,详情请参见查看活跃Query。
Query长时间不结束,如何Kill以及设置超时时间?
您可以通过在HoloWeb诊断与优化模块的活跃Query页面可视化查看活跃Query,并对Query进行Kill操作;在SQL编辑器模块使用SQL命令设置Query超时时间,详情请参见Query管理。
内存使用率高如何解决?
Hologres实例的内存使用率为内存综合使用率。Hologres的内存资源采用预留模式,在没有查询的时候,也会有数据表的元数据、索引、数据缓存等加载到内存中,以便加快检索和计算,此时内存使用率不为零是正常情况。理论上,在无查询的情况,内存使用率达到30%~40%左右都属于正常现象。
一些情况下,会使得内存使用率持续升高,甚至接近100%。主要原因如下:
- 表越来越多,数据总量越来越大,以至于数据规模远大于当前计算规格。由于内存使用率和元数据、索引量存在正相关关系,因此,表的数量越多,数据量越大,索引越多,都会导致内存使用率升高。
- 索引不合理,例如表的列特别多,TEXT列居多,设置了过多的Bitmap或Dictionary索引。此情况可以考虑去掉一些Bitmap或者Dictionar索引,详情请参见ALTER TABLE。
但是当内存使用率稳定增长,长期接近100%时,通常意味着内存资源可能成为了系统的瓶颈,可能会影响实例的稳定性和或性能。稳定性影响体现在当元数据等过大,超额占据了正常Query可用的内存空间时,在查询过程中,可能会偶发SERVER_INTERNAL_ERROR、ERPC_ERROR_CONNECTION_CLOSED、Total memory used by all existing queries exceeded memory limitation等报错。性能影响体现在当元数据等过大,超额占据了正常Query本来能够使用的缓存空间,从而缓存命中会减少,Query延迟会增加。
因此当内存长期接近100%时,有如下几个操作建议:
- 删除不再查询的数据,以释放元数据等占的内存。
- 设置合理的索引,若是业务场景用不上的bitmap和dictionary,可以去掉,但不建议直接去掉,需要根据业务情况具体分析。
- 升配实例的计算和存储资源。对于升配的建议是:
- 普通场景:可以容许读磁盘数据的延迟,响应时间要求不严格,1CU(1Core+4GB内存)可以支持50~100GB的数据存储。
- 响应时间要求低的Serving场景:最好查询热点数据全在内存的缓存中。内存中缓存的比例默认占总内存的30%,即1CU(1Core+4GB内存)其中1.3GB用于数据缓存,同时数据缓存还会被表的元数据所使用一些。举个例子,低响应要求的场景,热点数据如果是100GB,那么最好要求100GB 在缓存可用(实际上数据读出来解压后,占用内存不止100GB),因此至少需要约320GB内存以上,从而推算计算资源至少需要96CU左右。
为什么CPU使用率很容易达到100%?
实例的CPU综合使用率。Hologres因其设计原理可以充分发挥多核并行计算的能力,通常来说单个查询可以迅速将CPU使用率提高到100%,这说明计算资源得到了充分利用。
cpu高不是问题,cpu高了之后,查询慢写入慢才是问题,需要综合去分析。
CPU使用率长期达到100%如何解决?
当Hologres实例CPU使用率长期接近100%时(例如CPU使用率连续3小时满载100%,或者连续12小时达到90%以上等),说明实例负载非常高,这通常意味着CPU资源成为了系统的瓶颈,需要分析具体的业务场景和查询,以判断原因。
可以从以下几方面进行排查:
- 查看是否有比较大的离线数据导入(INSERT),且数据规模还在日渐增长。可以考虑降低写入并发,或者错峰写入,不至于影响查询,或者使用Hologres V1.1版本的读写分离高可用部署模式。
- 查看是否有高QPS的查询或写入,共同用满了CPU使用率。可以考虑降低写入并发,让查询先完成。
- 查看活跃Query是否有数据量大的Query。可以在HoloWeb活跃Query页面查看是否有Query一直没有结束,若是不符合业务预期的可以执行KILL操作,详情请参见Query管理。
- 如果确定是业务场景需要,将CPU资源用满,可以对实例进行扩容,以适应更复杂的查询或更大的数据量,详情请参见实例升配。
云监控告警配置最佳实践
Hologres已经接入云监控的云服务监控,方便您通过云监控全面了解Hologres实例的资源使用、业务运行及健康状况,及时收到异常报警并做出响应,保证应用程序运行顺畅。详细配置使用请见文档云监控。
如何为业务设置合适的告警,达到不频繁地对不重要事件报警,又能及时感知到重要异常事件发生的目的,实际上取决于您的具体业务情况,以及Hologres在您的整体架构中所处的位置,请根据具体情况进行设置。不过有一些通用性的指标,建议您对其设置告警,并且设置合适的告警,如下所示:
- CPU水位
CPU水位反映了Hologres的资源是否存在瓶颈,也反映了您的资源使用是否充分。CPU水位告警的核心逻辑在于,设置规则检测出CPU水位持续100%,即CPU持续打满的情况。因为这种情况,意味着当前实例规模的资源已充分利用,难以支撑业务数据量、查询量、计算量等的增长,需要考虑扩容等手段。告警规则建议:
- 不建议出现一次CPU使用率达到100%就告警。如果CPU水位持续到达100%一段时间,随后降低维持在中等或较低水平,那么一般是那段时间在做大的计算,例如大规模数据的写入,或者大规模数据的查询,因此不建议出现一次CPU使用率达到100%就告警,这样可能会产生较多误报。
- 建议设置为“CPU水位连续3次>=99% Info(每次间隔5分钟)”类似的告警规则。设置为“CPU水位连续3次>=99% Info(每次间隔5分钟)”的告警规则,即15分钟内检测3次出现CPU使用率100%,产生Info级别的告警。此告警规则可以有效避免误报,根据具体情况的不同,您可以降低间隔时间,或者提高检测次数。
- 内存水位
内存水位的逻辑与CPU水位大体相同。不同于CPU水位具有不产生计算则几乎为0的特点,内存水位在没有计算时,并不会为0,有时甚至会比较高。Hologres把计算内存分为了三块,一是预留给计算的内存,约占30%,没有计算时,这块几乎为0;二是数据缓存,在诸多情况下,数据缓存可以极大地减少I/O读取,提高SQL的计算效率,约占30%;三是实例中所有表、索引等元数据缓存,以及表在内存中的句柄和缓冲区等,约占30%。告警规则建议
- 不建议内存水位设置过低的阈值。
没有计算时只能保证前30%是空的,还有60%甚至以上的内存,可能是被占据的,因此体现出内存水位不为0甚至较高。有可能超过60%被占据,是因为元数据优先放入内存,如果元数据过多,加上数据缓存的30%,无计算时内存使用会超过60%。
- 建议设置为“内存水位连续3次>=90% Warning(每次间隔5分钟)”类似的告警规则。
设置为内存水位连续3次>=90% Warning(每次间隔5分钟)”的告警规则,即15分钟内检测到3次出现内存使用率超过90%,产生Warning级别的告警。
- 连接数使用率
对连接使用率进行告警,是为了防止连接数打满,而造成无法连接的异常影响业务。一般连接数在总连接数的95%以下都算安全。因此可以设置告警规则为:连接数使用率(Info)连续3次>=95%就报警。
- P99延迟
SQL语句从提交到返回的过程中,Hologres引擎处理99%查询语句的时间。响应时间异常性变大反映出系统可能有慢Query的趋势,可能会影响下游业务处理。平均响应时间很难有一个标准,需要根据您的实际查询使用模式而定。P99延迟代表了99% Query跑完的时间,相对平均而言有特定的意义。
例如您是持续服务型应用,平常的正常延迟都在1s以内,那么响应时间突然到5s或10s,就不太正常,需要告警出来,偶尔到1.2s,1.5s,则正常。
例如您是分析性应用,根据不同业务人员的需求,查询的大小、响应时间都不尽相同,那么就需要根据自己的场景进行设置。
另外要注意的是,当实例负载很高的时候,SQL运行时间波动可能越大,这种情况下就容易产生告警。解决方法是适当调整阈值,或者扩增实例规格以维持负载平稳。
- Query QPS
在您的业务中,有持续的SQL语句执行时,往往有持续稳定的QPS(Query Per Second)指标。当QPS突然降到很低,或者为0时,如果不是业务有意停止,那么可能意味着系统有异常。如果业务QPS持续稳定在某个值A,那么建议告警阈值设置为A的80%、50%或10%等,即告警规则设置为:QPS连续3次<=(A*0.8) Warning(每次间隔5分钟)。
- 实时写入RPS
在您的业务中,有持续的外部数据导入(通过Flink/数据集成等等)时,往往有持续的实时导入RPS(Record Per Second)指标。当RPS突然降到很低,或者为0时,如果不是作业有意停止,那么可能意味着系统有异常。例如,设置告警为:RPS(cmdType=sdk)连续1次<=10 Warning。
了解Hologres:https://www.aliyun.com/product/bigdata/hologram