
背景
对象存储OSS是阿里云提供的云存储服务,能够以低成本为用户提供高可靠性的海量数据存储服务。作为基础服务,用户需要时刻关注OSS的使用状况,检测异常状态,从而及时作出响应。
阿里云日志服务(SLS)是云原生观测分析平台,为Log/Metric/Trace等数据提供大规模、低成本、实时平台化服务。一站式提供数据采集、加工、分析、告警可视化与投递功能,全面提升研发、运维、运营和安全等场景数字化能力。

用户在访问对象存储 OSS 的过程中,会产生大量的访问日志。SLS允许一键接入OSS 访问日志,方便用户完成操作审计、访问统计、异常事件回溯和问题定位等工作。

- 问题一:存储空间持续增加
以 1000 QPS 的请求量计算,每条日志 1500 Bytes,一个月累计后达到 3.8 TB。但 访问日志随时间推移逐渐从温数据变为冷数据,这带来一笔不小的存储开销。
- 问题二:分析计算消耗大
假设对 30 天的数据分析小时级流量特征,如果每次对全量数据做即时分析,计算成本是巨大的,计算延时的增加也影响了体验。
以 bucket、method 分组计算小时级流量特征为例:
* | select (__time__ - __time__ % 3600) as dt, bucket, http_method, sum(request_length)/1024.0/1024.0 as request_MB, sum(response_body_length)/1024.0/1024.0 as response_MB, avg(response_time) as avg_latency group by dt, bucket, http_method order by dt asc limit 10000
随着查询时间范围增加,计算引擎需要扫描更多的数据量做计算,增加了资源开销与分析延时。
数据查询范围 |
扫描日志条数 |
计算耗时 |
24 hours |
5,153,426 |
1,767ms |
30 days |
35,754,384 |
4,636ms |
方案
本文介绍一种将日志转为指标的方案,允许用户快速查询分析OSS指标。常见的Log转Metric的方法可以有两种:
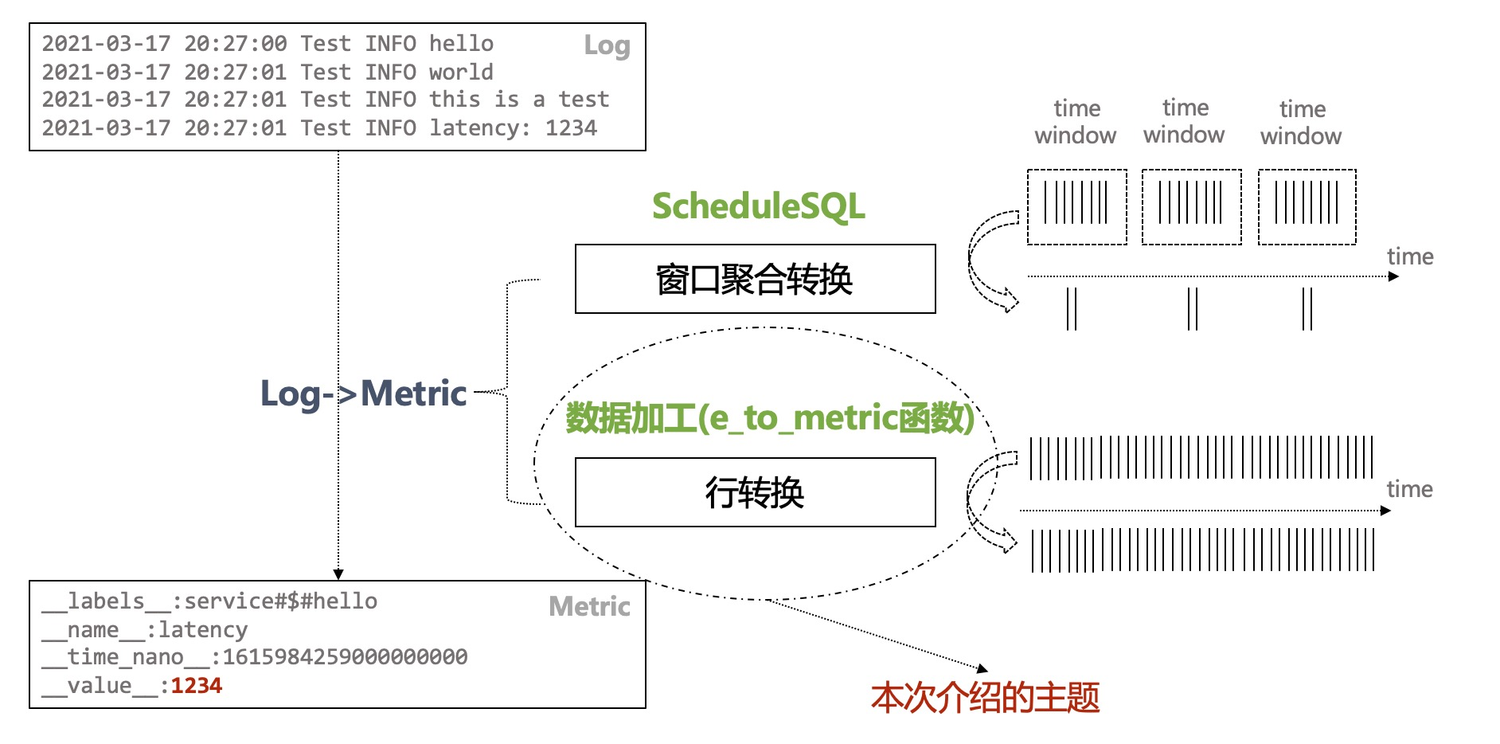
- 聚合日志产生指标,类似sql做group by以后产生对应的统计值。
- 将日志格式做格式转换,使其符合Metric格式. 对应SLS数据加工e_to_metric场景
本文主要介绍第一种方案,可以实现:
- 降低分析延迟:将日志数据转为时序数据,存入时序存储分析;SLS时序库针对指标场景做了大量优化;
- 优化数据存储:只存储监控相关数据,移除多余字段;
- 能够使用Prometheus生态:时序存储支持Prometheus查询语句,同时支持Prometheus 查询API;
原理即为使用SLS提供的ScheduledSQL服务,在后台定时运行SQL计算任务,将统计结果存入时序存储。
OSS指标数据
OSS访问日志中包含多种信息,首先需要确定日志信息能够计算得到的指标数据种类。本文给出了部分常用指标,更多的指标用户可以根据需求自行构建。指标标签我们统一使用:bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation字段。用户可以根据自己的需用
访问次数
计算分钟级不同类型OSS请求的次数。
计算SQL
*|select bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation, (__time__ - __time__ % 60) as time, count(1) as request_count from log group by bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation, time
请求数据量
计算分钟级OSS请求数据量。
计算SQL
*|select bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation, (__time__ - __time__ % 60) as time, sum(content_length_in) as request_size from log group by bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation, time
响应数据量
计算分钟级OSS响应数据量。
计算SQL
*|select bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation, (__time__ - __time__ % 60) as time, sum(content_length_out) as response_size from log group by bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation, time
响应时间
计算分钟级OSS平均响应时间。
计算SQL
*|select bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation, (__time__ - __time__ % 60) as time, avg(response_time) as response_time from log group by bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation, time
为了便于计算,我们将上述多条SQL合并为一条,一次性计算所有指标。
*|select bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation, (__time__ - __time__ % 60) as time, count(1) as request_count, sum(content_length_in) as request_size, sum(content_length_out) as response_size, avg(response_time) as response_time from log group by bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation, time
Scheduled SQL 实践
计算配置
资源池有免费(Project 级别 15 并行度)、增强型(收费,但资源可扩展,适用于大量计算且有 SLA 要求的业务场景)两种,按照你的需求来设置即可。

写入模式
写入模式有三种选择,当源为日志库时,可以选择日志库导入日志库以及日志库导入时序库;当源为时序库时,可以选择时序库导入时序库。因为oss访问数据为日志库,计算结果为时序数据,所以此处选择日志库导入时序库。
指标列
指标列用于选择计算结果列,类型必须为数字,这里选择request_count, request_size, response_size以及response_time,分别表示请求次数,请求大小,响应大小以及响应延迟。这里需要注意的是,如果结果中某行数据的指标列无效(无法转为数字),ScheduledSQL任务会忽略该错误,并继续执行。
Labels
Labels选择作为指标标签的列,类型没有限制,这里选择bucket, bucket_location, bucket_storage_type, http_method, http_status, object, operation。
哈希列
如果时序库中同一label的数据写入到固定的hard中,可以增强局部性,提升查询效率。因此可以选择常用的过滤标签,作为哈系列,使给定标签相同的指标存入同一shard中。这里选择bucket。
时间列
时间列用于指定该条指标的具体时间,类型必须为数字,这里直接使用time列即可。
调度配置
设置 SQL 每 5 分钟执行一次,每次执行处理最近 5 分钟窗口的数据。
注意:
1. 设置延迟执行参数,上游 Logstore 的数据到来可能延迟,建议设置大一些的值做等待来保证计算数据的完整性。
2. SQL 运行超过指定次数或指定时间后,这一次的 SQL 实例会失败并继续下一个实例的调度。

任务管理
在SLS控制台可以查看之前创建的ScheduledSQL作业。

在作业管理页面内,可以查看到每一次执行的实例列表。
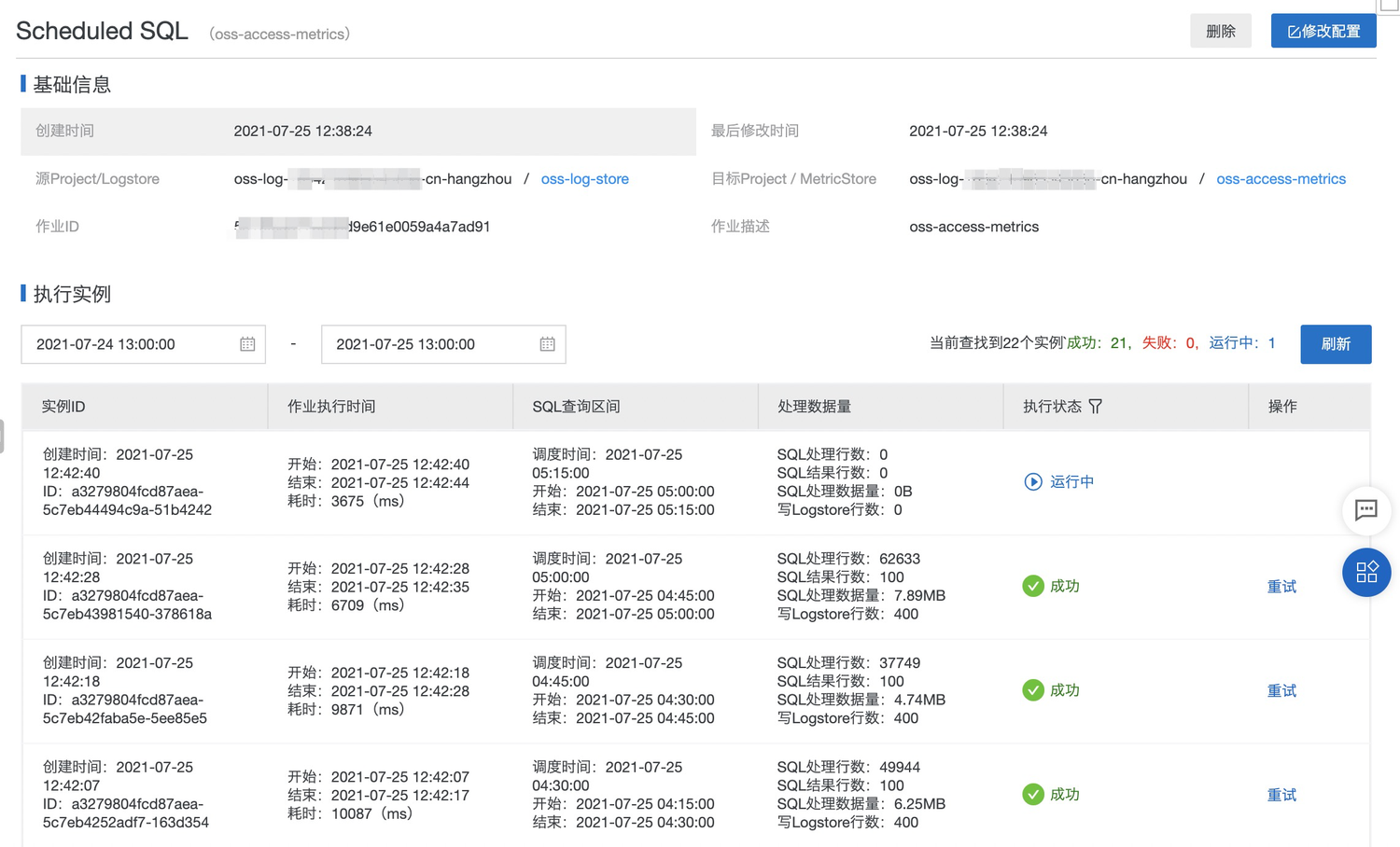
每个实例信息中有 SQL 查询区间,如果任务失败(权限、SQL 语法等原因)或 SQL 处理行数指标为 0(数据迟到或确实没有数据),可以对指定实例做重试运行(失败告警功能开发中)。
效果
计算完成之后,可以在时序库中查询oss访问指标。
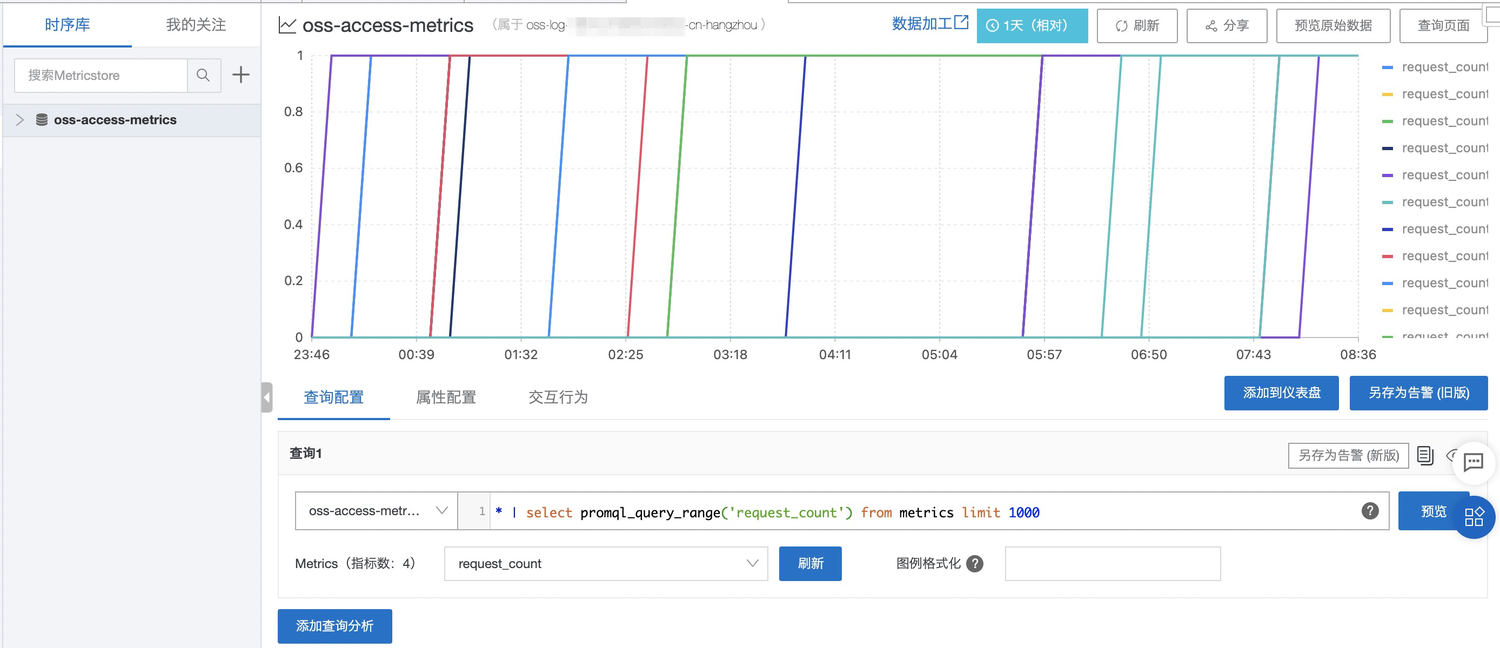
不同Bucket请求次数

不同类型请求次数
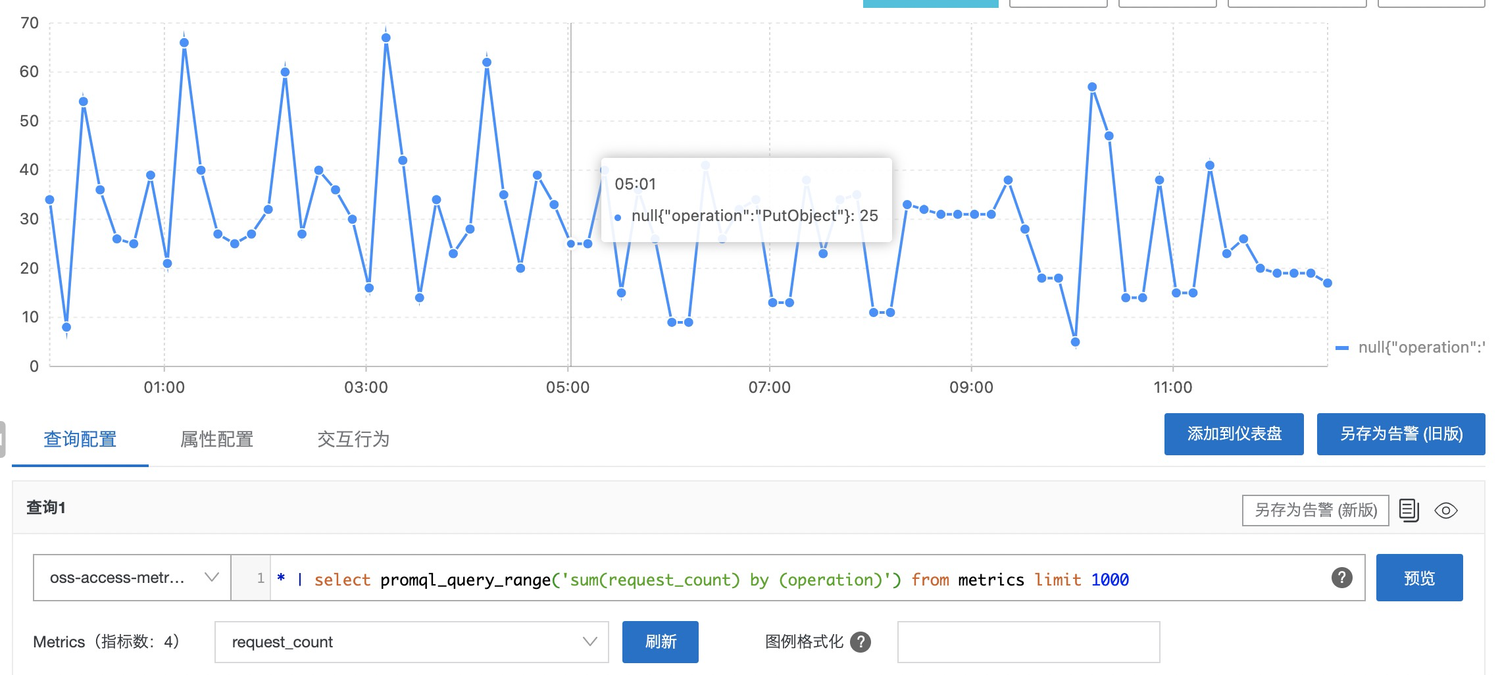
不同Bucket平均请求延迟
总结
通过SLS提供的ScheduledSQL功能,用户可以轻松将日志数据转为时序数据,存入到SLS的时序库中,满足用户监测系统指标的需求。
更多内容请参考:


