用户福利
阿里云最新发布业界首款云原生多模数据库Lindorm,新用户可申请首月免费试用,获取产品技术支持,请加入钉钉群:35977898,更多内容请参考链接
一、背景
广告顾名思义就是广而告之,通过广告推销商品或服务。在人类进入互联网时代之前,广告往往依赖传统的报纸、杂志、电视等大众媒体,广告的售卖也以线下的方式进行。当人类进入互联网、移动互联网之后,广告的售卖形式随着门户网站、各类手机APP的出现而发生了翻天覆地的变化,由此也推动了广告程序化购买的不断发展,与之相关的各类在线广告系统也不断发展。
二、广告的程序化购买流程及业务特征
2.1 一次广告的购买流程
广告的程序化购买通过广告交易平台(Ad Exchange,简写为ADX)、供应方平台(Supply-Side Platform,简写为SSP)、需求方平台(Demand-Side Platform,简写为DSP)、数据管理平台(Data Management Platform,简写为DMP)等几个新兴的互联网技术平台,将消费者、广告主、媒体等几方的需求有机的联系起来。
在SSP内实现广告库存的管理,当消费者触达广告位时,信息传递到ADX,同时在DMP内完成对消费者的画像数据查询,确定广告位展现需求,接着向各个DSP发起邀约,确定合适的广告主,然后进入竞价环节,达成广告交易,并最终在媒体端将广告主需要宣传的产品投放出去,展现在消费者面前。
备注:本图片来自网络,如有侵权请联系作者删除。
2.2 广告购买流程分析
从上述整个程序化购买广告的流程中可以看到:
- 整个广告购买链路涉及到环节众多,链路非常长,而实时性要求却非常高,通常在百毫秒级别,否则用户体验就会很差,超时的请求对于各方而言都是有损的:媒体的广告位没有卖出去、广告主没有将其产品展现给终端用户、DSP/SSP/DMP等各方也因为交易未达成而收不到佣金
- 为了实现广告的“精准营销”、“千人千面”,用户画像数据发挥了至关重要的作用,决定着向该特定用户展现什么样的广告内容,否则就会闹出把冰箱卖给爱斯基摩人的笑话。
那么,这里的数据包含哪些可能的内容呢?
- 用户画像数据,即用户的一些基本属性数据,如:性别、年龄、地址、收入状况等
- 用户在广告主网站/门店的浏览(包括时长等)、收藏、加购、交易等行为数据
- 用户其他行为数据,如:频道浏览,商家页面浏览、评论、打分、社区&论坛等
- 场景化广告中的特定数据,如:用户实时位置及时间数据
- 用户在投放广告的点击/互动的数据
- 来自于三方的线下数据。人们的线下行为往往比线上行付出的代价更大,因此往往具有更强的目的性,比如去4S店往往是有购车的意向。
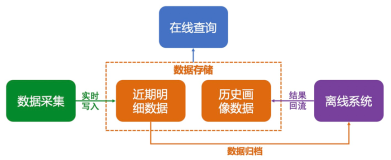
2.3广告业务系统的数据存储特征
- 能低成本支撑海量数据:互联网应用的一个典型特征是拥有海量的用户,往往都是以千万甚至亿计算,其浏览/加购/收藏及其他各类行为数据、场景化数据、广告点击&互动数据也必然是海量的。海量明细数据需要通过离线模型训练产出最终的用户画像数据,是数以亿计的高维(数百,数千甚至万计的字段数量)数据。
- 能支撑高并发读写并且低延迟:海量用户产生大量的数据需要实时写入到后台的存储系统中,因此数据写入的并发度往往会达到每秒数万,数十万甚至数百万或更高。同时广告投放与交易不同,往往和用户的浏览行为成正比,因此是一种更高频的读行为,而且在链路非常长的广告系统中需要确保百毫秒内返回。
- 需要具备归档能力:写入后端存储的用户行为明细或其他类型数据,为了尽快的反馈到用户画像数据中,往往需要准实时的归档到离线系统以完成分析产出结果。
- 需要具备高效&低影响的数据回流能力:归档到离线系统的数据经过分析后产生新的画像数据,需要能高效、无影响(对在线查询业务)的情况下,回流到在线存储内提供在线查询。
- 需具备动态Schema能力:如前所述,广告系统依赖的数据来源众多,例如:行为数据的采集需求也会不断变化,因此表结构也会处于不断变化当中。
针对上述数据存储的能力要求,同时该类数据没有强事务要求的特点,是否存在一个合适的存储方案呢?
三、面向大数据场景的Lindorm
没有强事务要求、海量数据、高并发&低延迟、准实时归档能力、高效数据回流能力以及动态schema能力,这些种种要求正是阿里云自研NoSQL数据库产品着力要解决的问题。
作为面向大数据场景的半结构化、结构化存储系统,Lindorm已经在阿里发展近十年,并始终保持着快速的能力更新和技术升级,是目前支撑阿里经济体业务的核心数据库产品之一。在过去的岁月,伴随着经济体内部对于海量结构数据存储处理的需求牵引,其在功能、性能、稳定性等方面的诸多创新历经了长时间的大规模实践考验,被全面应用于阿里集团、蚂蚁集团、菜鸟、大文娱等各个业务板块,成为目前为阿里内部数据体量最大、覆盖业务最广的数据库产品。
基于lindorm存储的用户画像架构可以用下图来描述:
下面笔者详细阐述下Lindorm的那些特性可以满足以用户画像数据为基础推进的程序化广告购买、投放系统对存储系统的需求。
3.1 低成本
大数据有众所周知5V特征,这其中首当其冲的是Volume,因此面向大数据场景的数据存储解决方案必须具备高密度、低成本的特性。Lindorm是诞生于大数据时代的一款NoSQL数据库,低成本解决海量大数据的高效存、取是根植于其体内的基因。Lindorm的低成本能力体现在:
-多样化存储类型支持
性能型存储、标准型存储、容量型存储,总有一款适合你的业务场景
-深度压缩优化
存储成本最低的系统是没有数据需要存储的系统,但这点显然是不现实的,现实可行的方案是将需要存储的数据降到合理的最低点。为了降低存储开销,Lindorm引入了一种新的无损压缩算法,旨在提供快速压缩,并实现高压缩比。它既不像LZMA和ZPAQ那样追求尽可能高的压缩比,也不像LZ4那样追求极致的压缩速度。这种算法的压缩速度超过200MB/s, 解压速度超过400MB/s(实验室数据),很好的满足Lindorm对吞吐量的需求。经实际场景验证,新的压缩优化下,压缩比相对于LZO有非常显著的提高,存储节省可以达到50%~100%,对于存储型业务,这就意味着最高可以达到50%的成本减少。
-冷热分离
Lindorm具备在单一个存储架构下的“一张表”内实现数据的冷热分离,系统会自动根据用户设置的冷热分界线,自动将表中的冷数据归档到冷存储中。在用户的访问方式上和普通表几乎没有任何差异,在查询的过程中,用户只需配置查询Hint或者Time Range,系统根据条件自动地判断查询应该落在热数据区还是冷数据区。对用户而言始终是一张表,对用户几乎做到完全的透明。
3.2 高性能吞吐
根据实测同样规格,相同数据量的情况下,Lindorm不管是在单行读、范围读还是单行写及批量写场景下,其吞吐量和P99延迟相比社区版本HBase2.0都有数倍提升。
备注:1) P99延迟指99%请求的响应时间小于该值; 2) 图中数值供参考,具体以实际场景为准
下图为以批量写为主的真实业务场景迁移后的表现,而用户画像的行为日志数据采集往往也可以通过累积一定量的数据后做批量写入。
3.3 多AZ + Speculative访问
Lindorm提供跨可用区强一致或最终一致不同模式来满足不同业务场景下的高可用及性能要求。对于以用户画像为基础数据的广告场景,对于数据一致性的要求并不高,能保证最终一致即可。在这样的前提下,就可以通过Lindorm提供的Speculative访问方式来大幅度降低单机/集群异常导致的访问毛刺,从而满足广告场景对于响应时间的极高要求。
3.4 实时增量归档
实时增量归档是Lindorm的一项独立服务,通过监听Lindorm产生的日志,LTS解析日志并同步到离线系统比如Hadoop或者MaxCompute。同步到离线系统的数据按时间分区,这样可以很方便的进行T+1,H+1或其他不同周期的计算。
这样的同步机制下,一方面数据归档过程与在线存储解耦,在线读写完全不会受到数据归档的影响。另一方面明细数据可以实现准实时同步到离线,然后进行分析,从而可以高效实现用户画像数据的更新。
3.5 Bulkload技术
与关系型数据库不同,Lindorm采用LSM Tree架构。读取存储到Lindorm里的一条记录需要合并对应数据分片内存中(即memestore)的数据、该数据分片所owner的多个LDFile中该记录的最新版本数据,合并后提交给客户端。基于这样的原理,Lindorm可以实现直接生成并向系统中“插入”新的LDFile,从而实现“新”数据的加载,使得其相比于其他的关系型数据库或NoSQL有非常大的优势。这样的数据加载过程完全绕过了存储引擎,WAL及Memstore等等,只有必不可少的物理IO和网络开销,从而极大的提升了数据加载的性能,降低了对在线业务请求的影响。
3.6 动态列
Lindorm的宽表模型支持多列簇、动态列、TTL、多版本等特性,可以很好的适合用户画像这样表结构不稳定,经常需要进行变更的业务场景。
四、Lindorm核心能力概述
Lindorm通过其具备的全方位、多角度的能力,可以很好的满足用户画像业务大数据量、高并发、实时归档、高效&稳定批量数据加载、动态列及多维度复杂查询的需求。
当然,Lindorm的能力还远不止于此,Lindorm具备了大数据背景下,面向海量数据的存储系统应该具备的一系列的能力:
- 是一款支持宽表、时序、搜索、文件的多模数据库
- 是一款基于存储计算分离架构的数据库,提供极致的计算、存储弹性伸缩能力,并将全新提供Serverless服务,实现按需即时弹性、按使用量付费的能力
- 是一款支持冷热分离、、追求更优压缩优化方案的极具性价比的数据库
- 是一款具备全局二级索引、多维检索、时序索引等功能的数据库
- 提供具备智能化服务能力的LDInsight工具,白屏化完成系统管理、数据访问及故障诊断
- 提供LTS(Lindorm Tunnel Service,原BDS),支持简单易用的数据交换、处理、订阅等能力,满足用户的数据迁移、实时订阅、数湖转存、数仓回流、单元化多活、备份恢复等需求
五、案例
某全球性的媒介投资管理集团
该公司每年管理着超过千亿美金的媒介投资,在全球市场上拥有众多深入了解消费者和媒体平台的媒介专家、专业的媒介购买能力、引领市场的品牌安全举措、技术解决方案,为客户及其他利益相关者打造市场优势。
该公司通过将其广告系统依赖的内存型数据库couchbase迁移至Lindorm,在大幅度降低运行成本的同时,成本通过Lindorm提供的Speculative访问方式,实现P99最大毛刺5ms,很好的满足了广告系统对于响应时间的极致要求,同时该架构下具备了多可用区的灾备能力。
系统架构如及业务流程参考下图所示:
咨询交流
欢迎加入Lindorm技术交流群