作者 | 邓小勇(静行),阿里巴巴高级技术专家
本文由阿里巴巴高级技术专家邓小勇(静行)分享,主要用 Demo 演示如何通过实时计算 Flink 实时计算pv/uv的场景。内容将从以下几部分进行:
- App 计算 pv/uv 场景
- 实现方案(From Flink-1.11)
- DDL
- DML
- 实操
首先为大家展示一个比较简单的pv/uv场景。以下图所示的APP为例,整个业务构架需要几个入口,包括用户访问入口、作者入口和运营人员入口。在运营人员入口进去可以查看系统的一些指标,比如app 的pv/uv。

在开始介绍如何计算实时pv/uv之前,可以先了解下上图的10个字段和它们对应的含义。通过这些字段可以了解到,用户在APP上的任何一次操作都会在数据库中留下一条对应的记录,所有记录就是该用户在APP上的操作流水。
那么如何实时计算pv/uv呢?
有两种方案。
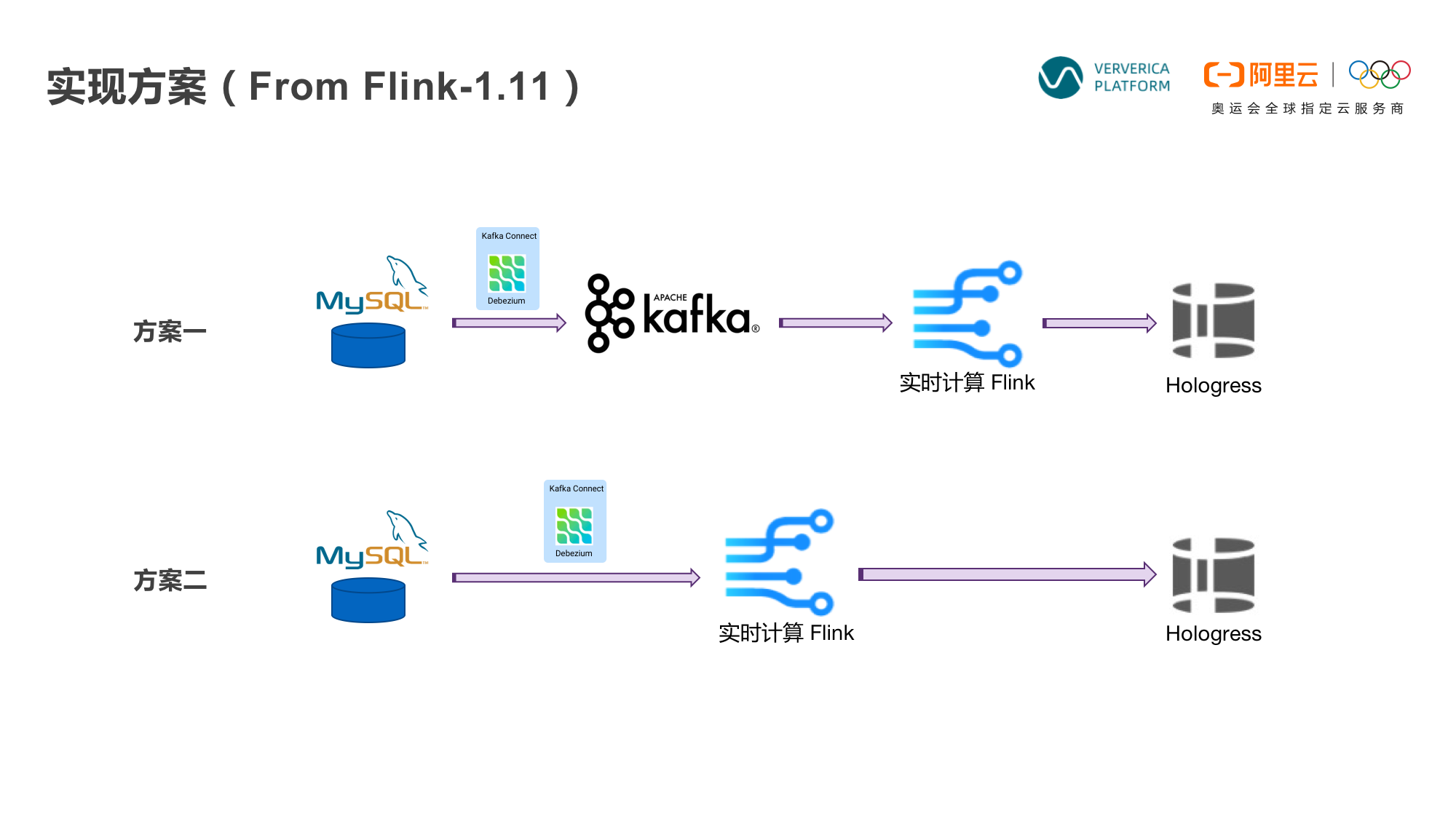
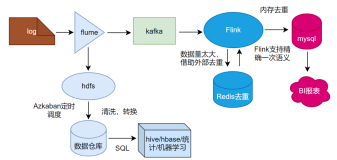
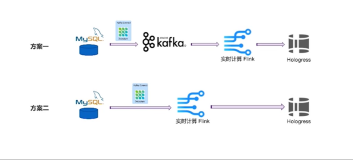
方案一,MySQL的变更数据同步到Kafka后进行实时计算。由于 Flink在设计之初是具有流表二象性的,所以在 Flink 1.1版本之后,就可以实现 Flink 对 Kafka变更数据的处理了,包括处理一些修改、删除等操作。处理后的结果会放到阿里云Hologress里,方便用户进行大数据查询和分析。
方案二,从上图可以看到方案一比方案二只多了一个Kafka,在 Flink 1.11 版本之后,可以直接通过Debezium连接MySQL,然后经过Flink 实时计算,也可以完成同样功能。
两个方案都可以实现,那么如何选择呢?主要取决于业务。如果数据只是暂存,日志需要展示或是需要多个下游使用,需要保存到Kafka;如果日志不需要回溯,或是没有下游使用,那么方案二更适合。
实战演示
如下图所示,我们选择方案二(MySQL-CDC源表方式)来演示。

首先打开实时计算 Flink平台,点击左侧SQL编辑器,然后通过Create Table方式设定上文提到的10个字段。这样就定义了数据的源头。
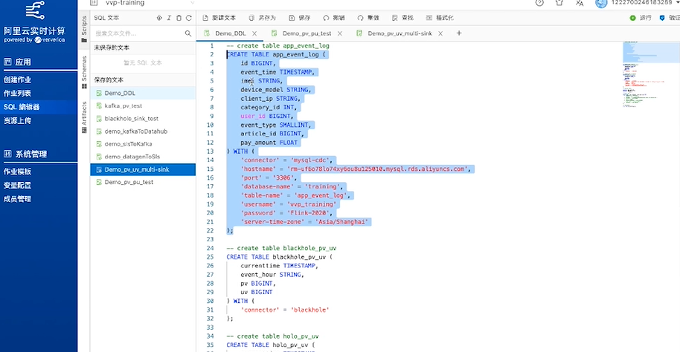
定义源头之后,接下来要构建目标表。如下图所示,在构建目标表时,定义了blackhole_pv_uv表,构造了一个无实际存储的目标端,充当调试作用,先把逻辑跑通,然后再去往目标端去写代码。Blackhole 会吸收掉输出结果数据,先处理掉源端和计算的问题。
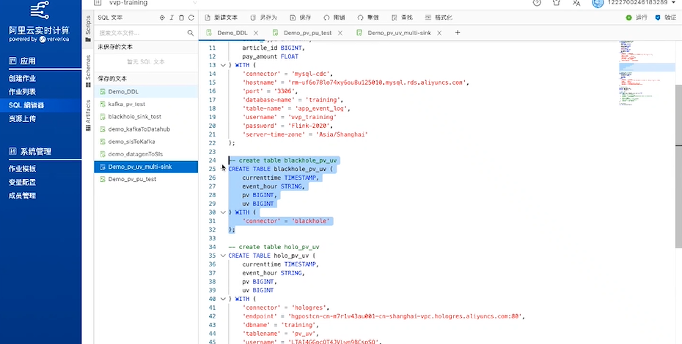
以上的表会落到 Flink Catalog里,对于实时计算pv/uv上下游表格的准备就完成了。如果需要调整表,也可以通过DDL SQL语句完成。
做好建表准备后,如何实时计算想要达到的目标呢?以最简单的方式来演示。
先把数据写到Blackhole里,然后把4个字段值计算出来,比如cuurenttime,event_hour等。
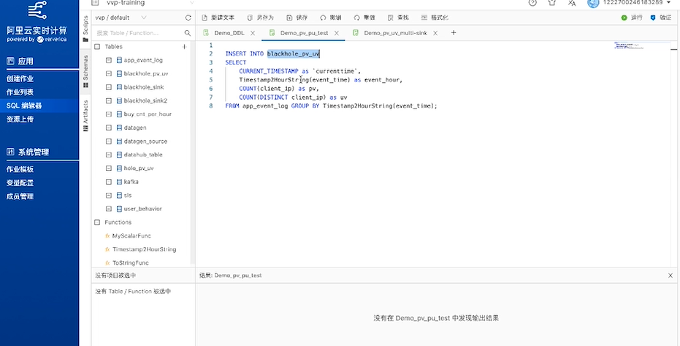
通过上图所示的代码可以计算出,数据是什么时候输入的,数据的pv/uv值等等。
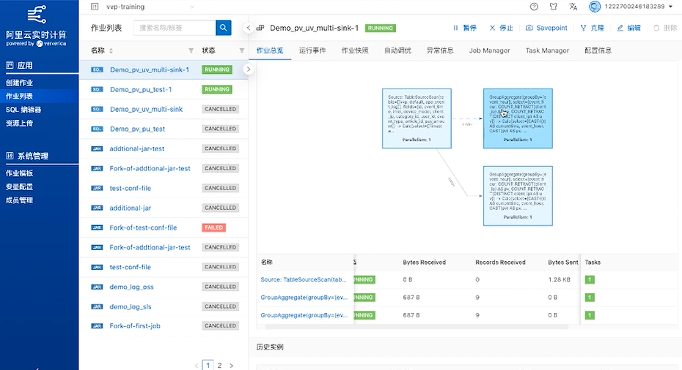
运行刚刚写入的作业:
然后点击创建SQL作业,
创建完成后,点击启动。
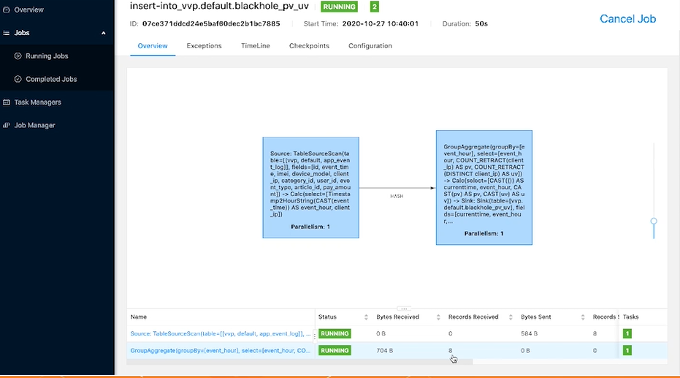
启动后可以点击 Flink UI 来查看运行状态。查看时候可以看到下端有显示记录了8条数据:
回到数据库也能看到对应的8条数据:
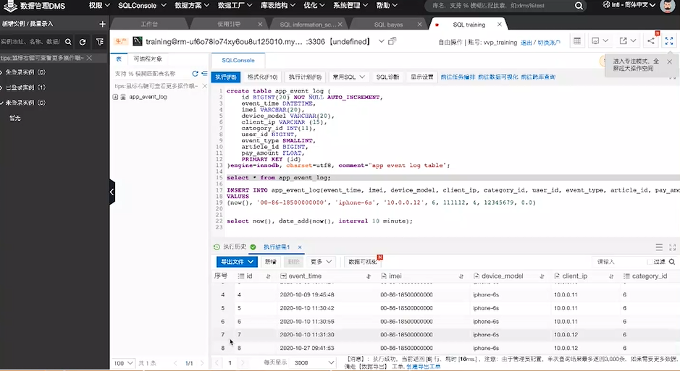
如何把实际的结果写到holo里呢?
核心逻辑与上文实时计算的逻辑是一样的,唯一不一样的是,要把计算的结果既输出到holo_pv_uv里去,同时也输出到backhole里去,也就是要把同样的结果输出两份,这是在流计算里经常会遇到的情况。甚至还有在同一作业里不同的业务逻辑或计算结果,也要输出到不同的目标端的情况。
打开实时计算 Flink 页面的SQL编辑器,在输入框中创建 temporary view,把数据记录到blackhole 里和holo里。
为了实现这个目标,需要增加一个叫begin statement set和end的语法,这其实是定义了一个计算逻辑,使得在它们中间的逻辑任务就会同时运行。
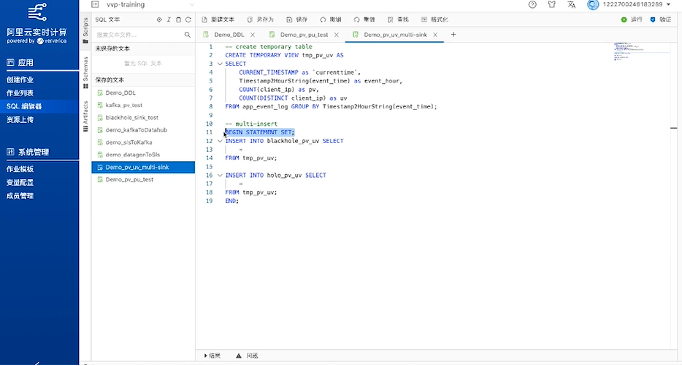
然后完成部署、创建作业和启动后,就能看到这个计算逻辑已经成功了。