作者:阿里云异构计算高级技术专家 何旻
背景
云原生已经成为业内云服务的一个趋势。在云原生上支持异构计算,这个功能在标准的Docker上已经可以很好的支持了。为了进一步提高GPU的利用率、避免算力浪费,需要在单个GPU上可以运行多个容器,并且在多个容器间隔离GPU应用,这在标准的Docker上是无法做到的。为了满足这一需求,业界也做了很多探索。NVIDIA vGPU, NVIDIA MPS, 基于rCUDA的方案等,都为用户更小颗粒度的使用GPU提供了可能。
近日,阿里云异构计算推出的cGPU(container GPU)容器技术,创新地提出了一种不同于以往的GPU容器方案,克服了业内主流方案的一些常见的缺陷,在保证性能的前提下,做到了容器之间的GPU显存隔离和任务隔离,为客户充分利用GPU硬件资源进行训练和推理提供的有效保障。
业内常用方案简介
在介绍阿里云异构计算cGPU计算技术前,我们先看看业内有哪些GPU共享方案吧:
NVIDIA MPS
NVIDIA MPS (NVIDIA Multi-Process Service)是NVIDIA公司为了进行GPU共享而推出的一套方案,由多个CUDA程序共享同一个GPU context,从而达到多个CUDA程序共享GPU的目的。同时,在Volta GPU上,用户也可以通过CUDA_MPS_ACTIVE_THREAD_PERCENTAGE变量设定每个CUDA程序占用的GPU算力的比例。
然而由于多个CUDA程序共享了同一个GPU context,这样引入的问题就是:当一个CUDA程序崩溃或者是触发GPU错误的时候,其他所有CUDA程序的任务都无法继续执行下去了,而这对于容器服务是灾难性的问题。
NVIDIA vGPU
NVIDIA vGPU方案是GPU虚拟化的方案,可以对多用户的强GPU隔离方案。它主要应用于虚拟化平台中,每个vGPU的显存和算力都是固定的,无法灵活配置;另外vGPU的使用需要额外从NVIDIA公司购买license,这里我们就不再详细讨论。
rCUDA类似方案
业内还有一种常用方案是通过替换CUDA库实现API层面的转发,然后通过修改显存分配,任务提交等API函数来达到多个容器共享GPU的目的。这种方案的缺点是需要对静态链接的程序重新编译,同时在CUDA库升级的时候也需要进行修改来适配新版本。
阿里云cGPU容器技术
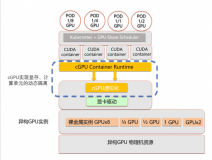
阿里云异构计算GPU团队推出了cGPU方案,相比其他方案,这是一个颠覆性的创新:通过一个内核驱动,为容器提供了虚拟的GPU设备,从而实现了显存和算力的隔离;通过用户态轻量的运行库,来对容器内的虚拟GPU设备进行配置。阿里云异构计算cGPU在做到算力调度与显存隔离的同时,也做到了无需替换CUDA静态库或动态库;无需重新编译CUDA应用;CUDA,cuDNN等版本随时升级无需适配等特性。

图1. cGPU容器架构图
cGPU内核驱动为一个自主研发的宿主机内核驱动。它的优点在于:
• 适配开源标准的Kubernetes和NVIDIA Docker方案;
• 用户侧透明。AI应用无需重编译,执行无需CUDA库替换;
• 针对NVIDIA GPU设备的底层操作更加稳定和收敛;
• 同时支持GPU的显存和算力隔离。
使用方式
1 利用阿里云容器服务
阿里云容器服务已经支持cGPU容器组件了,通过登录容器服务 Kubernetes 版控制台,只需要简单的点击几下,为容器节点打标,就可以利用cGPU容器隔离,最大化的利用GPU的硬件能力了。同时,还可以通过Prometheus的监控能力查看每个cGPU容器内的显存用量,在享受低成本的同时,保障了应用的可靠性。

快速部署和使用的方式,可以参见阿里云开发者社区的文章:
https://developer.aliyun.com/article/762973
更详细的使用文档,可以参考阿里云的帮助文档:
https://help.aliyun.com/document_detail/163994.html
2 在阿里云GPU实例上使用cGPU容器
为了更灵活的支持各种客户的需要,我们也开放了阿里云GPU实例上使用cGPU容器的能力。cGPU依赖 Docker 和 NVIDIA Docker,在使用cGPU前,请确保环境可以正常创建带GPU的容器服务。
- 安装:
下载cGPU 安装包:
wget http://cgpu.oss-cn-hangzhou.aliyuncs.com/cgpu-0.8.tar.gz
解压后执行 sh install.sh 命令安装。
安装后使用lsmod | grep cgpu 命令验证是否按照成功:
lsmod | grep cgpu
cgpu_km 71355 0
- 配置:
cGPU组件会检测以下docker的环境变量,进行相应操作:
• ALIYUN_COM_GPU_MEM_DEV:为正整数,表示为host上每张卡的总显存大小。
• ALIYUN_COM_GPU_MEM_CONTAINER: 为正整数,指定容器内可见的显存容量。此参数同
ALIYUN_COM_GPU_MEM_DEV一起设定cGPU内可见的显存大小。如在一张4G显存的显卡上,
我们可以通 过-e ALIYUN_COM_GPU_MEM_DEV=4 -e ALIYUN_COM_GPU_MEM_CONTAINER=1
的参数为容器分配1G显存。如果不指定此参数,则cGPU不会启动,此时会默认使用NVIDIA容器。• ALIYUN_COM_GPU_VISIBLE_DEVICES:为正整数或uuid,指定容器内可见的GPU设备。如在一个有4张显卡的机器上,我们可以通过-e ALIYUN_COM_GPU_VISIBLE_DEVICES=0,1来为容器分配第一和第二张显卡。或是-e ALIYUN_COM_GPU_VISIBLE_DEVICES=uuid1,uuid2,uuid3为容器分配uuid为uuid1,uuid2,uuid3z的3张显卡。
• CGPU_DISABLE:总开关,用于禁用cGPU。可以接受的参数是-e CGPU_DISABLE=true或-e CGPU_DISABLE=1,此时cGPU将会被禁用,默认使用nvidia容器。
• ALIYUN_COM_GPU_SCHD_WEIGHT 为正整数,有效值是1 - min(max_inst, 16),用来设定容器的算力权重。
c 运行演示:
以GN6i 单卡T4 为例,实现2个容器共享使用1个显卡。执行如下命令,分别创建2个docker 服务,设置显存分别为6G和8G。
docker run -d -t --gpus all --privileged --name gpu_test1 -e ALIYUN_COM_GPU_MEM_CONTAINER=6 -e ALIYUN_COM_GPU_MEM_DEV=15 nvcr.io/nvidia/tensorflow:19.10-py3
docker run -d -t --gpus all --privileged --name gpu_test2 -e ALIYUN_COM_GPU_MEM_CONTAINER=8 -e ALIYUN_COM_GPU_MEM_DEV=15 nvcr.io/nvidia/tensorflow:19.10-py3
如下图,进入Docker(gpu_test1) 后,执行nvidia-smi 命令,可以看到T4显卡的总内存为6043M

如下图,进入Docker(gpu_test2) 后,执行nvidia-smi 命令,可以看到T4显卡的总内存为8618M。

之后,就可以在每个容器内运行GPU训练或者推理的任务了。
性能分析
在使用过程中,用户经常关心的就是性能问题,cGPU容器方案会对性能有多少影响呢?下面是我们的一组测试数据,在常用的tensorflow框架下用benchmark工具分别测试了模型推理和训练性能。
以下数据的测试机为阿里云上的GPU型实例,具有8核CPU,32G内存,以及一张带有16G显存的NVIDIA T4显卡。测试数据为单次测试结果,因此可能会带有误差。
1 单cGPU容器 VS 单GPU直通性能比较
我们分别在cGPU容器内部以及标准的Docker容器内部跑测试,为cGPU容器内的GPU实例分配所有的显存和算力,来显示在不共享GPU的情况下的cGPU是否有性能损失。
下图是ResNet50训练测试在不同精度和batch_size下的性能比较,绿色柱表示标准的容器性能,橙色柱表示cGPU容器内的性能,可以看到在不同的情况下,cGPU容器实例都几乎没有性能损失。

图2. 单容器独占GPU--Resnet50 训练结果对比
下图是ResNet50推理测试在不同精度和batch_size下的性能比较,同样的在不同的情况下,cGPU容器实例都几乎没有性能损失。

图3. 单容器独占GPU--Resnet50 推理结果对比
2 cGPU容器 VS MPS容器GPU共享性能比较
如前文所述,标准的Docker容器不支持共享,为了测试多容器共享单个GPU的性能,我们采用了MPS容器作为基准来进行性能比较。同样的,我们采用了ResNet50的训练和推理benchmark作为测试用例,分别用两个cGPU容器和两个MPS容器共享一个GPU硬件。
下图是ResNet50训练测试在不同batch_size下的性能比较,绿色柱表示两个MPS容器性能跑分的总和,橙色柱表示两个cGPU容器跑分的总和,可以看到,cGPU容器实例对比MPS容器几乎没有性能损失,在大的batch_size的情况下甚至跑分高于MPS容器。

图4. 多容器共享GPU--Resnet50训练结果对比
下图是ResNet50推理测试在不同batch_size下的性能比较,MPS容器和cGPU容器的性能差距不大,基本都在误差范围之内。

图5. 多容器共享GPU--Resnet50推理结果对比
总结
阿里云cGPU容器技术,作为业内首创的基于内核虚拟GPU隔离的GPU共享容器方案,在保证性能的前提下,做到了容器之间的GPU显存隔离和任务隔离,为客户充分利用GPU硬件资源进行训练和推理提供的有效保障。
同时, cGPU方案具有多种输出方式:客户既可以选择阿里云GPU容器服务,简单便捷的实现GPU容器服务的共享、调度和监控;又可以选择在阿里云ECS GPU实例上进行手动安装配置,灵活可控,方便的和已有GPU容器进行整合。