
CDH和CM(Cloudera Manager)
CDH (Cloudera’s Distribution, including Apache Hadoop)是众多Hadoop发行版本中的一种,由Cloudera维护,目前有不少用户使用这个发行版本。CM是管理集群的工具,使用它可以很方便地部署、安装、运维包括Hadoop、Spark、Hive在内的大数据开源组件。
目前,CDH的最新发布的版本是CDH6.0.1,这个发行版本中,Hadoop的版本是3.0.0,天然支持OSS;而CDH5中的Hadoop是2.6,还不支持OSS(目前Apache Hadoop支持OSS的最低版本是2.9.1)。下面将介绍如何使CDH5支持OSS读写。
CDH5支持读写OSS
问题
由于CDH5的httpclient和httpcore这两个组件版本较低(4.2.5),而OSS SDK要求这两个组件的版本较高。然而Resource Manager要求的httpclient和httpcore必须是低版本。因此,下面提供了一个workaround方案。
搭建CDH集群
首先,我们根据官方文档搭建好CDH集群(这里以CDH 5.14.4为例);
下面的步骤需要在所有的CDH节点执行
下载支持包
http://gosspublic.alicdn.com/hadoop-spark/hadoop-oss-cdh-5.14.4.tar.gz
下载这个版本的CDH支持OSS的支持包并解压,里面的文件是:
[root@cdh-master ~]# ls -lh hadoop-oss-cdh-5.14.4/
总用量 2.7M
-rw-r--r-- 1 root root 114K 10月 8 17:36 aliyun-java-sdk-core-3.4.0.jar
-rw-r--r-- 1 root root 770K 10月 8 17:36 aliyun-java-sdk-ecs-4.2.0.jar
-rw-r--r-- 1 root root 211K 10月 8 17:36 aliyun-java-sdk-ram-3.0.0.jar
-rw-r--r-- 1 root root 13K 10月 8 17:36 aliyun-java-sdk-sts-3.0.0.jar
-rw-r--r-- 1 root root 550K 10月 8 17:36 aliyun-sdk-oss-3.4.1.jar
-rw-r--r-- 1 root root 70K 10月 8 17:36 hadoop-aliyun-2.6.0-cdh5.14.4.jar
-rw-r--r-- 1 root root 720K 10月 8 18:16 httpclient-4.5.2.jar
-rw-r--r-- 1 root root 320K 10月 8 18:16 httpcore-4.4.4.jar这个支持包是根据CDH5.14.4中Hadoop的版本,并打了Apache Hadoop对OSS支持的patch后编译得到,其他CDH5的小版本对OSS的支持后续也将陆续提供。
部署
将解压后的文件复制到CDH5的安装目录中的jars文件夹中,CDH5的安装目录CDH_HOME(以在/opt/cloudera/parcels/CDH-5.14.4-1.cdh5.14.4.p0.3为例)结构是
[root@cdh-master CDH-5.14.4-1.cdh5.14.4.p0.3]# ls -lh
总用量 100K
drwxr-xr-x 2 root root 4.0K 6月 12 21:03 bin
drwxr-xr-x 27 root root 4.0K 6月 12 20:57 etc
drwxr-xr-x 5 root root 4.0K 6月 12 20:57 include
drwxr-xr-x 2 root root 68K 6月 12 21:09 jars
drwxr-xr-x 38 root root 4.0K 6月 12 21:03 lib
drwxr-xr-x 3 root root 4.0K 6月 12 20:57 lib64
drwxr-xr-x 3 root root 4.0K 6月 12 20:51 libexec
drwxr-xr-x 2 root root 4.0K 6月 12 21:02 meta
drwxr-xr-x 4 root root 4.0K 6月 12 21:03 share
[root@cdh-master CDH-5.14.4-1.cdh5.14.4.p0.3]# ls -ltrh jars/
总用量 1.4G
.......
-rw-r--r-- 1 root root 114K 10月 28 14:27 aliyun-java-sdk-core-3.4.0.jar
-rw-r--r-- 1 root root 770K 10月 28 14:27 aliyun-java-sdk-ecs-4.2.0.jar
-rw-r--r-- 1 root root 13K 10月 28 14:27 aliyun-java-sdk-sts-3.0.0.jar
-rw-r--r-- 1 root root 211K 10月 28 14:27 aliyun-java-sdk-ram-3.0.0.jar
-rw-r--r-- 1 root root 550K 10月 28 14:27 aliyun-sdk-oss-3.4.1.jar
-rw-r--r-- 1 root root 70K 10月 28 14:27 hadoop-aliyun-2.6.0-cdh5.14.4.jar
-rw-r--r-- 1 root root 720K 10月 28 14:27 httpclient-4.5.2.jar
-rw-r--r-- 1 root root 320K 10月 28 14:27 httpcore-4.4.4.jar进入到$CDH_HOME/lib/hadoop目录, 执行如下命令 ```sh [root@cdh-master hadoop]# rm -f lib/httpclient-4.2.5.jar [root@cdh-master hadoop]# rm -f lib/httpcore-4.2.5.jar [root@cdh-master hadoop]# ln -s ../../jars/hadoop-aliyun-2.6.0-cdh5.14.4.jar hadoop-aliyun-2.6.0-cdh5.14.4.jar [root@cdh-master hadoop]# ln -s hadoop-aliyun-2.6.0-cdh5.14.4.jar hadoop-aliyun.jar [root@cdh-master hadoop]# cd lib [root@cdh-master lib]# ln -s ../../../jars/aliyun-java-sdk-core-3.4.0.jar aliyun-java-sdk-core-3.4.0.jar [root@cdh-master lib]# ln -s ../../../jars/aliyun-java-sdk-ecs-4.2.0.jar aliyun-java-sdk-ecs-4.2.0.jar [root@cdh-master lib]# ln -s ../../../jars/aliyun-java-sdk-ram-3.0.0.jar aliyun-java-sdk-ram-3.0.0.jar [root@cdh-master lib]# ln -s ../../../jars/aliyun-java-sdk-sts-3.0.0.jar aliyun-java-sdk-sts-3.0.0.jar [root@cdh-master lib]# ln -s ../../../jars/aliyun-sdk-oss-3.4.1.jar aliyun-sdk-oss-3.4.1.jar [root@cdh-master lib]# ln -s ../../../jars/httpclient-4.5.2.jar httpclient-4.5.2.jar [root@cdh-master lib]# ln -s ../../../jars/httpcore-4.4.4.jar httpcore-4.4.4.jar [root@cdh-master lib]# ln -s ../../../jars/jdom-1.1.jar jdom-1.1.jar ``` 进入到Resurce Manager部署节点的$CDH_HOME/lib/hadoop-yarn/bin/目录,将yarn文件中的
CLASSPATH=${CLASSPATH}:$HADOOP_YARN_HOME/${YARN_DIR}/*
CLASSPATH=${CLASSPATH}:$HADOOP_YARN_HOME/${YARN_LIB_JARS_DIR}/*替换为
CLASSPATH=$HADOOP_YARN_HOME/${YARN_DIR}/*:${CLASSPATH}
CLASSPATH=$HADOOP_YARN_HOME/${YARN_LIB_JARS_DIR}/*:${CLASSPATH}进入到Resurce Manager部署节点的$CDH_HOME/lib/hadoop-yarn/lib目录,执行 ```sh [root@cdh-master lib]# ln -s ../../../jars/httpclient-4.2.5.jar httpclient-4.2.5.jar [root@cdh-master lib]# ln -s ../../../jars/httpcore-4.2.5.jar httpcore-4.2.5.jar ``` ###增加OSS配置 通过CM来增加配置(对于没有CM管理的集群,可以通过修改core-site.xml来达到) 这里以CM为例,需要增加如下配置: 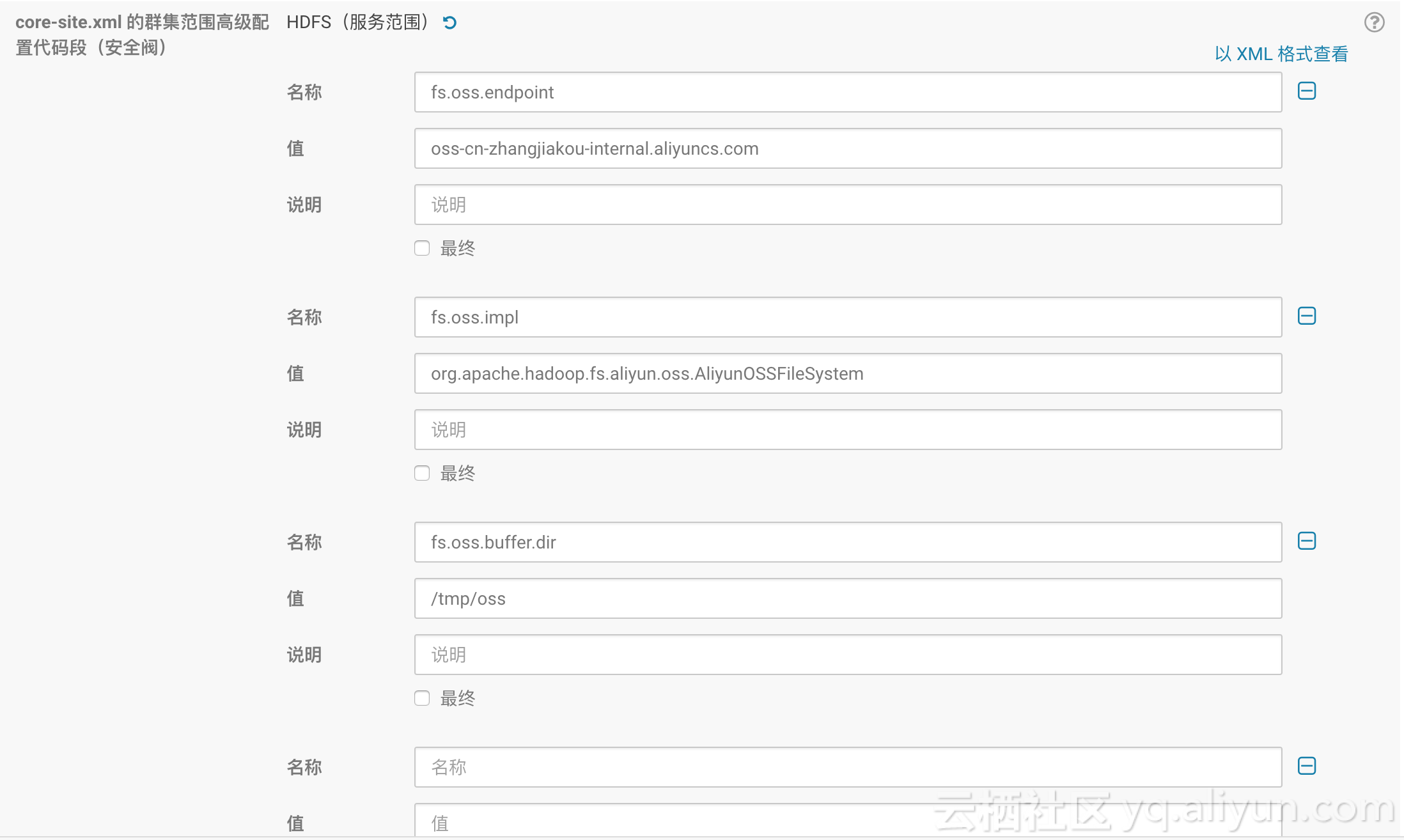 配置项 | 值 | 说明 ------- | ------- | ------- fs.oss.endpoint | 如 oss-cn-zhangjiakou-internal.aliyuncs.com | 要连接的endpoint fs.oss.accessKeyId | | access key id fs.oss.accessKeySecret | | access key secret fs.oss.impl | org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem | hadoop oss文件系统实现类,目前固定为这个 fs.oss.buffer.dir | /tmp/oss | 临时文件目录 fs.oss.connection.secure.enabled | false | 是否enable https, 根据需要来设置,enable https会影响性能 fs.oss.connection.maximum | 2048 | 与oss的连接数,根据需要设置 相关参数的解释可以在[**这里**](https://github.com/apache/hadoop/blob/trunk/hadoop-tools/hadoop-aliyun/src/site/markdown/tools/hadoop-aliyun/index.md)找到 ##重启集群,验证读写OSS 增加配置后,根据CM提示重启集群,重启后,可以测试 ```sh # 测试写 hadoop fs -mkdir oss://{your-bucket-name}/hadoop-test # 测试读 hadoop fs -ls oss://{your-bucket-name}/ ``` ## Impala查询OSS中的数据 Impala可以直接查询存储在HDFS的数据,在CDH5支持OSS后,就可以直接查询存储在OSS的数据,由于上面所说的httpclient与httpcore的版本问题,**需要在所有部署impala的节点上**做如下步骤: 进入到$CDH_HOME/lib/impala/lib,执行如下命令
[root@cdh-master lib]# rm -f httpclient-4.2.5.jar httpcore-4.2.5.jar
[root@cdh-master lib]# ln -s ../../../jars/httpclient-4.5.2.jar httpclient-4.5.2.jar
[root@cdh-master lib]# ln -s ../../../jars/httpcore-4.4.4.jar httpcore-4.4.4.jar
[root@cdh-master lib]# ln -s ../../../jars/hadoop-aliyun-2.6.0-cdh5.14.4.jar hadoop-aliyun.jar
[root@cdh-master lib]# ln -s ../../../jars/aliyun-java-sdk-core-3.4.0.jar aliyun-java-sdk-core-3.4.0.jar
[root@cdh-master lib]# ln -s ../../../jars/aliyun-java-sdk-ecs-4.2.0.jar aliyun-java-sdk-ecs-4.2.0.jar
[root@cdh-master lib]# ln -s ../../../jars/aliyun-java-sdk-ram-3.0.0.jar aliyun-java-sdk-ram-3.0.0.jar
[root@cdh-master lib]# ln -s ../../../jars/aliyun-java-sdk-sts-3.0.0.jar aliyun-java-sdk-sts-3.0.0.jar
[root@cdh-master lib]# ln -s ../../../jars/aliyun-sdk-oss-3.4.1.jar aliyun-sdk-oss-3.4.1.jar
[root@cdh-master lib]# ln -s ../../../jars/jdom-1.1.jar jdom-1.1.jar进入到$CDH_HOME/bin目录,修改impalad/statestored/catalogd这三个文件,**在文件最后一行exec命令前,增加如下一行** ``` export CLASSPATH=$CLASSPATH:${IMPALA_HOME}/lib/httpclient-4.5.2.jar:${IMPALA_HOME}/lib/httpcore-4.4.4.jar:${IMPALA_HOME}/lib/hadoop-aliyun.jar:${IMPALA_HOME}/lib/aliyun-java-sdk-core-3.4.0.jar:${IMPALA_HOME}/lib/aliyun-java-sdk-ecs-4.2.0.jar:${IMPALA_HOME}/lib/aliyun-java-sdk-ram-3.0.0.jar:${IMPALA_HOME}/lib/aliyun-java-sdk-sts-3.0.0.jar:${IMPALA_HOME}/lib/aliyun-sdk-oss-3.4.1.jar:${IMPALA_HOME}/lib/jdom-1.1.jar
重启所有节点的impala相关进程,这样impala就可以查询OSS的数据。
示例:TPC-DS的benchmark有一张表为call_center,目前假设存储在OSS中,为此,我们可以创建一个外部表指向它,并且查询这张表根据cc_country分组分别有多少条记录
```sql
[root@cdh-master ~]# impala-shell -i cdh-slave01:21000
Starting Impala Shell without Kerberos authentication
Connected to cdh-slave01:21000
Server version: impalad version 2.11.0-cdh5.14.4 RELEASE (build 20e635646a13347800fad36a7d0b1da25ab32404)
***********************************************************************************
Welcome to the Impala shell.
(Impala Shell v2.11.0-cdh5.14.4 (20e6356) built on Tue Jun 12 03:43:08 PDT 2018)
The HISTORY command lists all shell commands in chronological order.
***********************************************************************************
[cdh-slave01:21000] > drop table if exists call_center;
Query: drop table if exists call_center
[cdh-slave01:21000] >
[cdh-slave01:21000] > create external table call_center(
> cc_call_center_sk bigint
> , cc_call_center_id string
> , cc_rec_start_date string
> , cc_rec_end_date string
> , cc_closed_date_sk bigint
> , cc_open_date_sk bigint
> , cc_name string
> , cc_class string
> , cc_employees int
> , cc_sq_ft int
> , cc_hours string
> , cc_manager string
> , cc_mkt_id int
> , cc_mkt_class string
> , cc_mkt_desc string
> , cc_market_manager string
> , cc_division int
> , cc_division_name string
> , cc_company int
> , cc_company_name string
> , cc_street_number string
> , cc_street_name string
> , cc_street_type string
> , cc_suite_number string
> , cc_city string
> , cc_county string
> , cc_state string
> , cc_zip string
> , cc_country string
> , cc_gmt_offset double
> , cc_tax_percentage double
> )
> row format delimited fields terminated by '|'
> location 'oss://{bucket}/call_center';
Query: create external table call_center(
cc_call_center_sk bigint
, cc_call_center_id string
, cc_rec_start_date string
, cc_rec_end_date string
, cc_closed_date_sk bigint
, cc_open_date_sk bigint
, cc_name string
, cc_class string
, cc_employees int
, cc_sq_ft int
, cc_hours string
, cc_manager string
, cc_mkt_id int
, cc_mkt_class string
, cc_mkt_desc string
, cc_market_manager string
, cc_division int
, cc_division_name string
, cc_company int
, cc_company_name string
, cc_street_number string
, cc_street_name string
, cc_street_type string
, cc_suite_number string
, cc_city string
, cc_county string
, cc_state string
, cc_zip string
, cc_country string
, cc_gmt_offset double
, cc_tax_percentage double
)
row format delimited fields terminated by '|'
location 'oss://{bucket}/call_center'
Fetched 0 row(s) in 0.07s
[cdh-slave01:21000] > select cc_country, count(*) from call_center group by cc_country;
Query: select cc_country, count(*) from call_center group by cc_country
Query submitted at: 2018-10-28 16:21:13 (Coordinator: http://cdh-slave01:25000)
Query progress can be monitored at: http://cdh-slave01:25000/query_plan?query_id=fb4e09977145f367:3bdfe4d600000000
+---------------+----------+
| cc_country | count(*) |
+---------------+----------+
| United States | 30 |
+---------------+----------+
Fetched 1 row(s) in 4.71s其他版本的支持包
CDH5.8.5
http://gosspublic.alicdn.com/hadoop-spark/hadoop-oss-cdh-5.8.5.tar.gz
CDH5.4.4
http://gosspublic.alicdn.com/hadoop-spark/hadoop-oss-cdh-5.4.4.tar.gz
CDH6.3.2
http://gosspublic.alicdn.com/hadoop-spark/hadoop-oss-cdh-6.3.2.tar.gz
注:CDH6目前已经支持OSS,但CDH6支持的版本过低,很多优化没有包含在里面,这个支持包会及时包含OSS的优化。将优化包的内容复制到CDH6的安装目录中的jars文件夹中,然后参考CDH5的部署步骤执行即可(主要是更新aliyun-sdk-oss-3.4.1.jar以及将aliyun-java-sdk-*.jar符号链接到对应的位置)。
参考文章
https://yq.aliyun.com/articles/292792?spm=a2c4e.11155435.0.0.7ccba82fbDwfhK
https://github.com/apache/hadoop/blob/trunk/hadoop-tools/hadoop-aliyun/src/site/markdown/tools/hadoop-aliyun/index.md



