
MySQL 5.6 的新特性之一,是加入了全局事务 ID (GTID) 来强化数据库的主备一致性,故障恢复,以及容错能力。但是,有关 GTID 的作用和原理,在 MySQL 官方网站 的文档库中却很少被提到。
随着 MySQL 5.6 的 rc 版本号原来越高(这意味着 MySQL 5.6 向正式发布越来越近),想要全面了解这个神秘功能的需求也越来越急迫。因此,在这篇博客里,我打算从有限的文档出发,通过分析 MySQL 源码,逐步了解 MySQL GTID 和它在主备复制中的作用。
什么是 GTID?
有关全局事务 ID(GTID),容易找到的是这一篇文档:
http://dev.mysql.com/doc/refman/5.6/en/replication-gtids.html
在这篇文档里,我们可以知道全局事务 ID 的官方定义是:
GTID = source_id:transaction_id
在 MySQL 5.6 中,每一个 GTID 代表一个数据库事务。在上面的定义中,source_id 表示执行事务的主库 uuid(server_uuid),transaction_id 是一个从 1 开始的自增计数,表示在这个主库上执行的第 n 个事务。MySQL 会保证事务与 GTID 之间的 1 : 1 映射。
例如,下面就是一个 GTID:
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
表示在以 3E11FA47-71CA-11E1-9E33-C80AA9429562 为唯一标示的 MySQL 实例上执行的第 23 个数据库事务。
很容易理解,MySQL 只要保证每台数据库的 server_uuid 全局唯一,以及每台数据库生成的 transaction_id 自身唯一,就能保证 GTID 的全局唯一性。
什么又是 server_uuid?
MySQL 5.6 用 128 位的 server_uuid 代替了原本的 32 位 server_id 的大部分功能。原因很简单,server_id 依赖于 my.cnf 的手工配置,有可能产生冲突 —— 而自动产生 128 位 uuid 的算法可以保证所有的 MySQL uuid 都不会冲突。
在首次启动时 MySQL 会调用 generate_server_uuid() 自动生成一个 server_uuid,并且保存到 auto.cnf 文件 —— 这个文件目前存在的唯一目的就是保存 server_uuid。
在 MySQL 再次启动时会读取 auto.cnf 文件,继续使用上次生成的 server_uuid。
使用 SHOW 命令可以查看 MySQL 实例当前使用的 server_uuid:
SHOW GLOBAL VARIABLES LIKE 'server_uuid';
它是一个 MySQL 5.6 global variables,文档链接在这里:
server_uuid
全局唯一的 server_uuid 可以解决由 server_id 配置冲突带来的 MySQL 主备复制的异常终止(BUG
#33815):
在 MySQL 5.6,Slave 向 Master 申请 binlog 时,会首先发送自己的 server_uuid,Master 用 Slave 发送的 server_uuid 代替 server_id (MySQL 5.6 之前的方式)作为 kill_zombie_dump_threads 的参数,终止冲突或者僵死的 BINLOG_DUMP 线程。
关于 GTID 的更多细节:
在 MySQL 5.6 源码内部,GTID 的数据结构可以用伪码写成:
(代码路径:mysql-5.6.9-rc\sql\rpl_gtid.h, 754 line)
Gtid := (sidno, gno)
其中 sidno 是代表 sid 的 32-bit 序号,sid 是 source_id 或者 server_uuid 的二进制表示 —— 这里我先忽略 sidno 和 sid 的关联(这需要解释一些另外复杂的东西)。gno 是 64 位整数,等同于上面提到的 transaction_id。
在 MySQL 内部更常见的数据类型是 Gtid_set,表示一组 GTID 的集合,在官方文档中通常写成 GTIDs。例如,下面就是一个 GTIDs:
3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5
表示在 MySQL 实例 3E11FA47-71CA-11E1-9E33-C80AA9429562 上执行的第 1 到第 5 个数据库事务。
复杂一点的是:如果这组 GTIDs 来自不同的 source_id,各组 source_id 之间用逗号分隔;如果事务序号有多个范围区间,各组范围之间用冒号分隔,例如:
3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5:11-18,
2C256447-3F0D-431B-9A12-575BB20C1507:1-27
GDITs 和 Gtid_set
在 MySQL 5.6 源码里,Gtid_set 是个较为复杂的数据结构,基本结构可以用伪码表示成:(代码路径:mysql-5.6.9-rc\sql\rpl_gtid.h, 842 line)
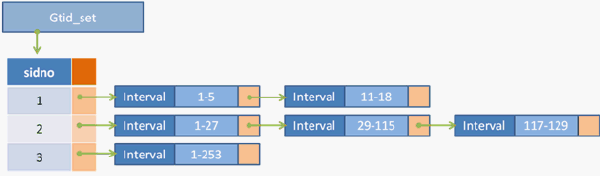
Gtid_set := array( sidno => link_list(Interval) )
Interval := (start, end)
用示意图表示应该是这样:
Gtid_set 的结构是一个以 sidno 为序号的数组(同样的,这里允许我先忽略什么是 sidno 这个挠头的问题),每个数组元素都指向一条 Interval 组成的链表,链表中的每个 Interval 用来存放一组事务 ID(gno)的区间,例如 (1,5)。
假设上文中 uuid:3E11FA47-71CA-11E1-9E33-C80AA9429562 对应的 sidno 为 1,那么下面的 GTIDs:
3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5
可以用 Gtid_set 表示为:
Gtid_set
| sidno: 1 | -> Interval(1, 5)
MySQL 5.6 引入 Gtid_set 数据结构的目的是为了轻量级的记录大量的连续全局事务 ID,比如已经在 Slave 上执行的全局事务 ID, 或者主库上正在运行的全局事务 ID。这些集合往往包含海量的全局事务 ID。
当 transaction_id / gno 保持连续,Gtid_set 可以在常数时间内判断一个 GTID 是否包含在集合内。这很容易用来检查一个 GTID 是否已经执行过,因此可以用在防止 MySQL 事务在同一个 Slave 上重复执行这类场景。
Gtid_set 也支持一些常见的集合操作,比如检查另一个 Gtid_set 是否子集:is_subset,比如两组 Gtid_set 做交集:intersection。这些方法在根据 GTIDs 自动查找主备复制位点,进行自适应主备切换时有用到。
有个值得一提的细节是,Gtid_set 为了减少链表导致的内存碎片,所有的 Interval 对象都是用 chunk 方式分配的,chunk 大小为 8 * sizeof(Interval)。
打断,解释一下 sidno
为减少在索引里保存 128 位 server_uuid 的消耗,Gtid_set 使用 int32 类型的 sidno 代替 server_uuid 作为 Interval 链表的索引。因此,MySQL 需要另一个数据结构在 128 位的 server_uuid 与 32 位的 sidno 之间建立映射,这个结构叫 Sid_map:
(代码路径:mysql-5.6.9-rc\sql\rpl_gtid.h, 467 line)
Sid_map := hash_map(sid => sidno)
它基本上就是一个 server_uuid 到 sidno 的 hash_map, 并且负责顺序产生 sidno:第一个放入 Sid_map 的 sidno 为 1,第二个 sidno 为 2 ...... 注意,生成的 sidno 是临时性的,在 Sid_map 被释放或者 MySQL 实例重启后又会重新分配。
在创建 Gtid_set 时,MySQL 会调用 ensure_sidno() 方法保证 array 内有足够的空间容纳 Sid_map 中所有分配的 sidno。
因为 Sid_map 是一个读多写少的数据结构(显然,只有 MySQL 集群增加或者更换实例时,server_uuid 才会增加),MySQL 用一个读写锁来保护 Sid_map,每当 Gtid_set 在查 Sid_map 时加读锁;每当 Gtid_set 找到新的 server_uuid 需要分配 sidno 时,加写锁。
基本上,MySQL 5.6 所有的 server_uuid 都通过一个全局变量 global_sid_map 来映射。相应的,也有一个全局锁 global_sid_lock 在保护这个 Sid_map。这些代码在 mysqld.cc 的 gtid_server_init 方法里可以找到。
(代码路径:mysql-5.6.9-rc\sql\mysqld.cc, 1719 line)
最后介绍一下 Gtid_state
现在,MySQL 5.6 有了记录全局事务 ID 的数据结构 Gtid_set,又维持了一个全局 Sid_map 来映射 server_uuid 与 sidno,下面我们可以开始接触 MySQL 全局事务 ID 的核心数据 Gtid_state 了:
Gtid_state := (logged_gtids, lost_gtids, owned_gtids)
全局事务状态 Gtid_state 在 MySQL 5.6 内只有唯一一个实例,目的是存储三组全局事务 ID 的集合,每个集合的功能我会在下一篇博客阐述:
+---------------+-------------------------------------------------------------+
| 名称 | 功能 |
+---------------+-------------------------------------------------------------+
| logged_gtids | 写入到 binlog 的全局事务 ID 集合。 |
+---------------+-------------------------------------------------------------+
| lost_gtids | 已经从 binlog 删除的全局事务 ID 集合。 |
+---------------+-------------------------------------------------------------+
| owned_gtids | 正在执行的全局事务 ID 与 MySQL 线程 ID 的集合 |
+---------------+-------------------------------------------------------------+
注:owned_gtids 变量的类型是 Owned_gtids, 它基本上可以看作一个 Gtid (sidno, gno) 到 owner_thread_id 的 hash_map:
Owned_gtids := array(sidno => hash_map(Node))
Node := (gno, owner_thread_id)
其中 gno 是 Gtid 中的事务 ID。
(未完待续)



