fast.ai 深度学习笔记(七)(1)https://developer.aliyun.com/article/1482687
感知损失[50:57]
使用感知损失,我们基本上要拿出我们的 VGG 网络,就像我们上周做的那样,找到在我们得到最大池之前的块索引。
def icnr(x, scale=2, init=nn.init.kaiming_normal): new_shape = [int(x.shape[0] / (scale ** 2))] + list(x.shape[1:]) subkernel = torch.zeros(new_shape) subkernel = init(subkernel) subkernel = subkernel.transpose(0, 1) subkernel = subkernel.contiguous().view( subkernel.shape[0], subkernel.shape[1], -1 ) kernel = subkernel.repeat(1, 1, scale ** 2) transposed_shape = [x.shape[1]] + \ [x.shape[0]] + list(x.shape[2:]) kernel = kernel.contiguous().view(transposed_shape) kernel = kernel.transpose(0, 1) return kernelm_vgg = vgg16(True) blocks = [ i-1 for i,o in enumerate(children(m_vgg)) if isinstance(o,nn.MaxPool2d) ] blocks, [m_vgg[i] for i in blocks] ''' ([5, 12, 22, 32, 42], [ReLU(inplace), ReLU(inplace), ReLU(inplace), ReLU(inplace), ReLU(inplace)]) '''
这是每个相同网格大小块的末尾。如果我们将它们打印出来,正如我们所期望的那样,每一个都是一个 ReLU 模块,所以在这种情况下,这最后两个块对我们来说不太有趣。那里的网格大小足够小,当然足够小,对于超分辨率来说并不那么有用。所以我们只会使用前三个。为了节省不必要的计算,我们只会使用 VGG 的前 23 层,然后丢弃其余的。我们会把它放在 GPU 上。我们不会训练这个 VGG 模型——我们只是用它来比较激活。所以我们会将其设置为评估模式,并设置为不可训练。
vgg_layers = children(m_vgg)[:23] m_vgg = nn.Sequential(*vgg_layers).cuda().eval() set_trainable(m_vgg, False) def flatten(x): return x.view(x.size(0), -1)
就像上周一样,我们将使用SaveFeatures类来做一个前向钩子,保存每个层的输出激活[52:07]。
class SaveFeatures(): features=None def __init__(self, m): self.hook = m.register_forward_hook(self.hook_fn) def hook_fn(self, module, input, output): self.features = output def remove(self): self.hook.remove()
现在我们已经有了创建我们的感知损失或者我在这里称之为FeatureLoss类所需的一切。我们将传入一个层 ID 列表,我们希望计算内容损失的层,以及每个层的权重列表。我们可以遍历每个层 ID 并创建一个具有前向钩子函数来存储激活的对象。所以在我们的前向传播中,我们可以直接调用模型的前向传播,使用目标(我们试图创建的高分辨率图像)。我们这样做的原因是因为这将调用那个钩子函数并将我们想要的激活存储在self.sfs(self 点保存特征)中。现在我们还需要对我们的卷积网络输出进行相同的操作。所以我们需要克隆这些,否则卷积网络输出将继续覆盖我已经有的内容。所以现在我们可以对卷积网络输出执行相同的操作,这是损失函数的输入。所以现在我们有了这两个东西,我们可以将它们与权重一起压缩在一起,所以我们有了输入、目标和权重。然后我们可以计算输入和目标之间的 L1 损失,并乘以层权重。我还做的另一件事是我也获取了像素损失,但我将其权重降低了很多。大多数人不这样做。我没有看到有论文这样做,但在我看来,这可能更好一点,因为你有感知内容损失激活的东西,但在最细微的层面上,它也关心个别像素。所以这就是我们的损失函数。
class FeatureLoss(nn.Module): def __init__(self, m, layer_ids, layer_wgts): super().__init__() self.m,self.wgts = m,layer_wgts self.sfs = [SaveFeatures(m[i]) for i in layer_ids] def forward(self, input, target, sum_layers=True): self.m(VV(target.data)) res = [F.l1_loss(input,target)/100] targ_feat = [V(o.features.data.clone()) for o in self.sfs] self.m(input) res += [ F.l1_loss(flatten(inp.features),flatten(targ))*wgt for inp,targ,wgt in zip(self.sfs, targ_feat, self.wgts) ] if sum_layers: res = sum(res) return res def close(self): for o in self.sfs: o.remove()
我们创建我们的超分辨率 ResNet,告诉它要放大多少倍。
m = SrResnet(64, scale)
然后我们将对像素混洗卷积进行icnr初始化[54:27]。这是非常无聊的代码,实际上我是从别人那里抄的。它实际上只是说,好吧,你有一些权重张量x,你想要初始化,所以我们将把它视为具有形状(即特征数量)除以比例平方特征的实际特征。所以这可能是 2² = 4,因为我们实际上只想保留一组然后将它们复制四次,所以我们除以四并创建一个相同大小的东西,我们用默认的kaiming_normal初始化它。然后我们只需复制它的 scale²份。其余部分只是稍微移动一下轴。所以这将返回一个新的权重矩阵,其中每个初始化的子核被重复 r²或scale²次。所以细节并不重要。这里重要的是我只是查找了一下,在像素混洗之前实际的卷积层,并将其存储起来,然后我调用icnr来获得我的新权重矩阵。然后我将这个新的权重矩阵复制回那一层。
conv_shuffle = m.features[10][0][0] kernel = icnr(conv_shuffle.weight, scale=scale) conv_shuffle.weight.data.copy_(kernel);
正如你所看到的,我在这个练习中费了很大的劲,真的尽力去实现所有最佳实践[56:13]。我倾向于做事情有点极端。我向你展示了一个只能勉强工作的非常粗糙的版本,或者我会尽最大努力让它真正运行良好。所以这个版本是我声称这几乎是一个最先进的实现。这是一个获奖的竞赛,或者至少是我重新实现的一个获奖方法。我这样做的原因是因为我认为这是那些实际上把很多细节做对的罕见论文之一,我希望你能感受到把所有细节做对的感觉。记住,把细节做对是区分丑陋模糊混乱和漂亮精致结果之间的区别。
m = to_gpu(m) learn = Learner(md, SingleModel(m), opt_fn=optim.Adam) t = torch.load( learn.get_model_path('sr-samp0'), map_location=lambda storage, loc: storage ) learn.model.load_state_dict(t, strict=False) learn.freeze_to(999) for i in range(10,13): set_trainable(m.features[i], True) conv_shuffle = m.features[10][2][0] kernel = icnr(conv_shuffle.weight, scale=scale) conv_shuffle.weight.data.copy_(kernel);
所以我们再次对其进行 DataParallel[57:14]。
m = nn.DataParallel(m, [0,2]) learn = Learner(md, SingleModel(m), opt_fn=optim.Adam) learn.set_data(md)
我们将把我们的标准设置为使用我们的 VGG 模型的 FeatureLoss,获取前几个块,这些是我发现效果非常好的一组层权重。
learn.crit = FeatureLoss(m_vgg, blocks[:3], [0.2,0.7,0.1]) lr=6e-3 wd=1e-7
进行学习率查找。
learn.lr_find(1e-4, 0.1, wds=wd, linear=True) ''' 1%| | 15/1801 [00:06<12:55, 2.30it/s, loss=0.0965] 12%|█▏ | 220/1801 [01:16<09:08, 2.88it/s, loss=0.42] ''' learn.sched.plot(n_skip_end=1)
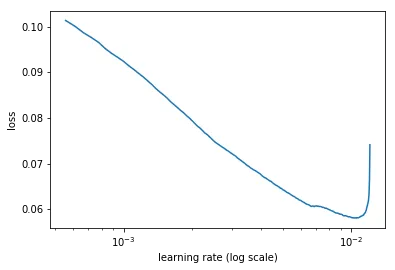
适应一段时间
learn.fit(lr, 1, cycle_len=2, wds=wd, use_clr=(20,10)) ''' epoch trn_loss val_loss 0 0.04523 0.042932 1 0.043574 0.041242 [array([0.04124])] ''' learn.save('sr-samp0') learn.save('sr-samp1')
我花了一段时间来尝试弄清楚一些细节。但这里是我最喜欢的论文部分,接下来会发生什么。现在我们已经为尺度等于 2 做好了准备——渐进式调整大小。渐进式调整大小是让我们在 DAWN 基准上对 ImageNet 训练获得最佳单台计算机结果的技巧。这个想法是从小开始逐渐变大。我只知道有两篇论文使用了这个想法。一篇是 GANs 渐进式调整大小的论文,允许训练非常高分辨率的 GANs,另一篇是 EDSR 论文。渐进式调整大小的酷之处不仅在于,假设你的前几个时期是 2x2 更小,速度快了四倍。你也可以让批量大小可能增加 3 或 4 倍。但更重要的是,它们将更好地泛化,因为在训练过程中你会向模型输入不同尺寸的图像。因此,我们能够为 ImageNet 训练使用一半的时代,比大多数人快。我们的时代更快,而且数量更少。因此,渐进式调整大小是一种特别适合从头开始训练的东西(我不确定它是否对微调迁移学习有用,但如果你是从头开始训练),你可能几乎想一直这样做。
渐进式调整大小
接下来的步骤是回到顶部,将尺度改为 4,批量大小为 32,重新启动。在这样做之前,我保存了模型。

回去,这就是为什么在这里重新加载时会有一点混乱,因为现在我需要做的是重新加载我的保存模型。

但有一个小问题,就是现在我有一个比以前多的上采样层,从 2x2 到 4x4。我的循环现在循环两次,而不是一次。因此,它添加了一个额外的卷积网络和一个额外的像素混洗。那么我要如何为不同的网络加载权重呢?

答案是我在 PyTorch 中使用一个非常方便的东西load_state_dict。这就是lean.load在幕后调用的内容。如果我传递这个参数strict=False,那么它会说“好吧,如果你不能填充所有的层,就填充你能填充的层。”因此,在这种方式下加载模型后,我们将得到一个加载了所有可能层的模型,而那个新的卷积层将被随机初始化。

然后我冻结所有的层,然后解冻那个上采样部分。然后在我新添加的额外层上使用icnr。然后我可以继续学习。所以接下来的步骤是一样的。
如果你试图复制这个过程,不要只是从头到尾运行。要意识到这需要有一些跳跃。
learn.load('sr-samp1') lr=3e-3 learn.fit(lr, 1, cycle_len=1, wds=wd, use_clr=(20,10)) ''' epoch trn_loss val_loss 0 0.069054 0.06638 [array([0.06638])] ''' learn.save('sr-samp2') learn.unfreeze() learn.load('sr-samp2') learn.fit(lr/3, 1, cycle_len=1, wds=wd, use_clr=(20,10)) ''' epoch trn_loss val_loss 0 0.06042 0.057613 [array([0.05761])] ''' learn.save('sr1') learn.sched.plot_loss()

def plot_ds_img(idx, ax=None, figsize=(7,7), normed=True): if ax is None: fig,ax = plt.subplots(figsize=figsize) im = md.val_ds[idx][0] if normed: im = denorm(im)[0] else: im = np.rollaxis(to_np(im),0,3) ax.imshow(im) ax.axis('off') fig,axes=plt.subplots(6,6,figsize=(20,20)) for i,ax in enumerate(axes.flat): plot_ds_img(i+200,ax=ax, normed=True)
x,y=md.val_ds[215] y=y[None] learn.model.eval() preds = learn.model(VV(x[None])) x.shape,y.shape,preds.shape ''' ((3, 72, 72), (1, 3, 288, 288), torch.Size([1, 3, 288, 288])) ''' learn.crit(preds, V(y), sum_layers=False) ''' [Variable containing: 1.00000e-03 1.1935 [torch.cuda.FloatTensor of size 1 (GPU 0)], Variable containing: 1.00000e-03 8.5054 [torch.cuda.FloatTensor of size 1 (GPU 0)], Variable containing: 1.00000e-02 3.4656 [torch.cuda.FloatTensor of size 1 (GPU 0)], Variable containing: 1.00000e-03 3.8243 [torch.cuda.FloatTensor of size 1 (GPU 0)]] ''' learn.crit.close()
训练时间越长,效果就越好。我最终训练了大约 10 个小时,但如果你不那么耐心,仍然可以更快地获得非常好的结果。所以我们可以试一试,这里是结果。左边是我的像素化鸟,右边是放大版本。它实际上发明了着色。但它弄清楚了这是什么鸟,知道这些羽毛应该是什么样子的。因此,它想象出了一组与这些确切像素兼容的羽毛,这是天才。同样适用于头部后面。你无法告诉这些蓝点代表什么。但如果你知道这种鸟在这里有一排羽毛,你就知道它们必须是这样的。然后你可以推断出羽毛必须是这样的,以至于当它们被像素化时它们会出现在这些位置。因此,它根据对这种确切鸟类的了解,逆向工程出了它必须看起来像这样才能创建这个输出。这太神奇了。它还知道周围所有的迹象表明这里(背景)几乎肯定被模糊处理了。因此,它实际上重建了模糊的植被。如果它没有做所有这些事情,它就不会得到如此好的损失函数。因为最终,它必须匹配激活,说“哦,这里有一根羽毛,看起来有点蓬松,朝这个方向”,等等。
_,axes=plt.subplots(1,2,figsize=(14,7)) show_img(x[None], 0, ax=axes[0]) show_img(preds,0, normed=True, ax=axes[1])

好了,这就是超分辨率的结束。别忘了查看向 Jeremy 提问任何问题的帖子。
向 Jeremy 提问
问题:fast.ai 和这门课程的未来计划是什么?会有第 3 部分吗?如果有第 3 部分,我真的很想参加。
Jeremy:我不太确定。猜测总是很困难的。我希望会有某种后续。去年,在第 2 部分之后,有一名学生发起了一个每周读书俱乐部,通过 Ian Goodfellow 的深度学习书籍,Ian 实际上进来并介绍了很多章节,还有一个专家,每章节都有人介绍。那是一个非常酷的第 3 部分。在很大程度上,这将取决于你们社区,提出想法并帮助实现它们,我肯定愿意帮助。我有很多想法,但我对说出来感到紧张,因为我不确定哪些会发生,哪些不会。但如果你们支持我,让你们想要发生的事情发生,那么它们发生的可能性就更大。
问题:你创业的经历是怎样的?你一直是创业者吗,还是从大公司开始,然后转向创业公司?你是从学术界转向创业公司,还是从创业公司转向学术界的?
Jeremy:不,我绝对不是学术界的。我完全是一个假学者。我 18 岁时在麦肯锡公司开始工作,那是一家战略公司,这意味着我不能真正去大学,所以我也没有去。然后在商界度过了 8 年,帮助一些大公司解决战略问题。我一直想成为一名企业家,计划只在麦肯锡待两年,我生命中唯一后悔的事情就是没有坚持那个计划,而是浪费了八年。所以两年本来就够了。然后我进入了创业领域,在澳大利亚创办了两家公司。最好的部分是我没有得到任何资金支持,所以我赚的钱都是我的,决策也是我和我的合作伙伴的。我完全专注于利润、产品、客户和服务。而我发现在旧金山,我很高兴来到这里,我和安东尼一起来到这里为 Kaggle 工作,为这家全新的公司筹集了 1100 万美元的资金。这真的很有趣,但也很分散注意力,要担心扩张和风险投资者想看到你的业务发展计划,而且根本没有真正需要实现利润。所以在 Enlitic,我又遇到了同样的问题,我很快又筹集了 1500 万美元,分散了很多注意力。我认为尝试自己创业,专注于通过销售盈利并将利润再投入公司,效果非常好。因为在五年内,我们从第三个月开始盈利,五年内,我们的利润足够不仅支付我们所有人的工资,还能看到我的银行账户在增长,十年后以一大笔钱出售,虽然不足以让风险投资者兴奋,但足以让我不再为钱担心。所以我认为自己创业是一个好主意,至少在旧金山的人似乎不太欣赏这个主意。
问题:如果你今天 25 岁,仍然知道你所知道的,你会在哪里寻找使用人工智能的机会?你现在正在做什么,或者在接下来的两年里打算做什么?
Jeremy:你应该忽略那个问题的最后部分。我甚至不会回答它。我在哪里寻找并不重要。你应该利用你对领域的知识。我们这样做的主要原因之一是为了让那些在招聘、油田调查、新闻业、活动主义等领域有背景的人解决问题。对你来说,真正的问题会很明显,你拥有的数据在哪里找也会很明显。对其他人来说,这些都是非常困难的部分。所以那些开始时说“哦,我现在懂深度学习了,我会找一些东西来应用它”的人基本上从来没有成功,而那些像“哦,我已经花了 25 年专门为法律公司招聘,我知道关键问题是什么,我知道这个数据完全解决了它,所以我现在就去做,我已经知道该打电话给谁或者开始销售了”的人往往会成功。如果你除了学术研究什么都没做过,那可能更多是关于你的爱好和兴趣。每个人都有爱好。我想说的主要是,请不要专注于为数据科学家或软件工程师构建工具,因为每个数据科学家都了解数据科学家的市场,而只有你了解分析油田调查世界或理解听力学研究等你所做的市场。
问题:鉴于您向我们展示了如何将迁移学习从图像识别应用到 NLP,看起来值得关注整个机器学习领域发生的所有发展,如果您专注于某一领域,可能会错过其他领域的一些重大进展。在深入研究您特定领域的同时,如何保持对整个领域的所有进展的了解?
Jeremy:是的,这太棒了。我是说这门课程的关键信息之一。在不同地方做了很多好工作,人们都很专业,大多数人都不知道。如果我在开始研究 NLP 六个月后就能获得最先进的结果,我认为这更多地反映了 NLP 而不是我。这有点像创业的事情。你选择你了解的领域,然后转移类似“哦,我们可以使用深度学习来解决这个问题”或者在这种情况下,我们可以使用计算机视觉的这个想法来解决那个问题。所以像迁移学习这样的东西,我敢肯定在其他领域有成千上万的机会让你像 Sebastian 和我在 NLP 中做 NLP 分类那样做。所以回答你的问题的简短答案是保持对正在发生的事情的了解的方法是关注我的 Twitter 收藏夹,我的方法是在 Twitter 上关注很多人,然后将他们放入你的 Twitter 收藏夹。每当我遇到有趣的东西时,我都会点击收藏。我这样做的原因有两个。第一个是当下一门课程出现时,我会浏览我的收藏夹,找出我想学习的东西。第二个是为了让你也可以做同样的事情。然后你深入研究的东西几乎无关紧要。我发现每次我看某件事情时,它都会变得非常有趣和重要。所以选择一些你觉得解决那个问题会真正有用的东西,而且似乎并不很受欢迎,这与其他人的做法恰恰相反。其他人都在解决已经受欢迎的问题,因为它们似乎很受欢迎。我无法完全理解这种思维方式,但它似乎非常普遍。
问题:在表格数据上使用深度学习是否过度?什么时候最好在表格数据上使用 DL 而不是 ML?
Jeremy:这是一个真正的问题,还是你只是放在那里让我指出 Rachel Thomas 刚写了一篇文章?www.fast.ai/2018/04/29/categorical-embeddings/
所以 Rachel 刚刚写了这篇文章,Rachel 和我花了很长时间讨论这个问题,简短的答案是我们认为在表格数据上使用深度学习是很棒的。实际上,在 Rachel 的 Twitter 流中出现的所有丰富复杂重要和有趣的事情中,从罗兴亚种族灭绝到 AI 公司最新的伦理违规行为,迄今为止引起社区最多关注和参与的是有关表格数据或结构化数据的问题。所以是的,问计算机人如何命名事物,你会得到很多兴趣。这里有一些来自 Instacart 和 Pinterest 以及其他一些在这一领域做出了一些出色工作的人的链接。如果你们中有人参加了数据研究所的会议,就会看到 Jeremy Stanley 在 Instacart 做的非常酷的工作的演示。
Rachel:我在撰写这篇文章时主要依赖于第 1 部分的第 3 和第 4 课,因此其中的许多内容可能对您来说很熟悉。
Jeremy: Rachel 在后面问我如何判断是否应该使用决策树集成,如 GBM 或随机森林,还是神经网络,我的答案是我仍然不知道。据我所知,没有人以任何特别有意义的方式进行过这方面的研究。所以这里有一个需要回答的问题,我想。我的方法是尽可能通过 fast.ai 库使这两种方法都尽可能易于使用,这样你就可以尝试它们并看看哪种方法有效。这就是我做的。
问题: 强化学习在最近逐渐受到关注。你对强化学习有什么看法?fast.ai 是否考虑在未来涵盖一些流行的强化学习技术?
Jeremy: 我仍然不相信强化学习。我认为解决这个问题是一个有趣的问题,但我们并没有一个很好的解决这个问题的方法。问题实际上是延迟奖励问题。所以我想学会玩乒乓球,我向上或向下移动,三分钟后我才知道我是否赢得了乒乓球比赛——我采取的哪些行动实际上是有用的?对我来说,计算输出相对于这些输入的梯度,奖励是如此延迟,以至于这些导数似乎并不那么有趣。到目前为止,在我所教授的四门课程中,我经常被问到这个问题。我总是说同样的话。我很高兴最近终于有一些结果表明,实际上基本上随机搜索往往比强化学习做得更好,所以基本上发生的情况是,拥有大量计算能力的资金充裕的公司将所有资源投入到强化学习问题中,并取得了良好的结果,然后人们就会说“这是因为强化学习”,而不是因为大量的计算资源。或者他们使用非常周到和聪明的算法,比如卷积神经网络和蒙特卡洛树搜索的组合,就像他们在 Alpha Go 项目中所做的那样取得了很好的结果,人们错误地说“这是因为强化学习”,而实际上根本不是强化学习。所以我对解决这些更通用的优化问题非常感兴趣,而不仅仅是预测问题,这些延迟奖励问题看起来就是这样。但我认为我们还没有得到足够好的最佳实践,我没有任何准备好教授的东西,也没有说我必须教你这个东西,因为我认为明年它仍然会有用。所以我们将继续观察并看看会发生什么。
超分辨率网络转换为风格转移网络[1:17:57]

我们现在要把超分辨率网络转换为风格转移网络。我们会很快地完成这个过程。我们基本上已经有了一些东西。x是我的输入图像,我将有一些损失函数和一些神经网络。这次我们的输入和输出大小是一样的,所以我们要先做一些下采样。然后是计算,最后是上采样。这是我们要做的第一个改变——我们要在网络的前面添加一些下采样,也就是一些步幅为 2 的卷积层。第二个改变是,不再只是比较yc和x是否相同。我们基本上要说我们的输入图像应该在最后看起来像它自己。具体来说,我们将通过 VGG 将其传递并在其中一个激活层进行比较。然后它的风格应该看起来像一幅画,我们将像我们用 Gatys 的方法那样通过查看多个层的 Gram 矩阵对应来实现。基本上就是这样。这应该非常简单明了。这实际上是将我们已经做过的两件事结合在一起。
风格转移网络
所以所有这些代码都是相同的,除了我们没有高分辨率和低分辨率,我们只有一个尺寸为 256。
%matplotlib inline %reload_ext autoreload %autoreload 2 from fastai.conv_learner import * from pathlib import Path torch.cuda.set_device(0) torch.backends.cudnn.benchmark=True PATH = Path('data/imagenet') PATH_TRN = PATH/'train' fnames_full,label_arr_full,all_labels = folder_source(PATH, 'train') fnames_full = ['/'.join(Path(fn).parts[-2:]) for fn in fnames_full] list(zip(fnames_full[:5],label_arr_full[:5])) ''' [('n01440764/n01440764_9627.JPEG', 0), ('n01440764/n01440764_9609.JPEG', 0), ('n01440764/n01440764_5176.JPEG', 0), ('n01440764/n01440764_6936.JPEG', 0), ('n01440764/n01440764_4005.JPEG', 0)] ''' all_labels[:5] ''' ['n01440764', 'n01443537', 'n01484850', 'n01491361', 'n01494475'] ''' np.random.seed(42) # keep_pct = 1. # keep_pct = 0.01 keep_pct = 0.1 keeps = np.random.rand(len(fnames_full)) < keep_pct fnames = np.array(fnames_full, copy=False)[keeps] label_arr = np.array(label_arr_full, copy=False)[keeps] arch = vgg16 # sz,bs = 96,32 sz,bs = 256,24 # sz,bs = 128,32 class MatchedFilesDataset(FilesDataset): def __init__(self, fnames, y, transform, path): self.y=y assert(len(fnames)==len(y)) super().__init__(fnames, transform, path) def get_y(self, i): return open_image(os.path.join(self.path, self.y[i])) def get_c(self): return 0 val_idxs = get_cv_idxs(len(fnames), val_pct=min(0.01/keep_pct, 0.1)) ((val_x,trn_x),(val_y,trn_y)) = split_by_idx( val_idxs, np.array(fnames), np.array(fnames) ) len(val_x),len(trn_x) ''' (12800, 115206) ''' img_fn = PATH/'train'/'n01558993'/'n01558993_9684.JPEG' tfms = tfms_from_model(arch, sz, tfm_y=TfmType.PIXEL) datasets = ImageData.get_ds( MatchedFilesDataset, (trn_x,trn_y), (val_x,val_y), tfms, path=PATH_TRN ) md = ImageData(PATH, datasets, bs, num_workers=16, classes=None) denorm = md.val_ds.denorm def show_img(ims, idx, figsize=(5,5), normed=True, ax=None): if ax is None: fig,ax = plt.subplots(figsize=figsize) if normed: ims = denorm(ims) else: ims = np.rollaxis(to_np(ims),1,4) ax.imshow(np.clip(ims,0,1)[idx]) ax.axis('off')
模型
我的模型是一样的。这里我做的一件事是我没有使用任何花哨的最佳实践。部分原因是因为似乎没有。与超分辨率的研究相比,对这种方法的跟进非常少。我们稍后会讨论原因。所以你会看到,这看起来更加正常。
def conv( ni, nf, kernel_size=3, stride=1, actn=True, pad=None, bn=True ): if pad is None: pad = kernel_size//2 layers = [nn.Conv2d( ni, nf, kernel_size, stride=stride, padding=pad, bias=not bn )] if actn: layers.append(nn.ReLU(inplace=True)) if bn: layers.append(nn.BatchNorm2d(nf)) return nn.Sequential(*layers)
我有批量归一化层。这里没有缩放因子。
class ResSequentialCenter(nn.Module): def __init__(self, layers): super().__init__() self.m = nn.Sequential(*layers) def forward(self, x): return x[:, :, 2:-2, 2:-2] + self.m(x) def res_block(nf): return ResSequentialCenter([ conv(nf, nf, actn=True, pad=0), conv(nf, nf, pad=0) ])
我没有像素混洗 —— 只是使用正常的上采样,然后是 1x1 的卷积。所以这只是更正常的。
def upsample(ni, nf): return nn.Sequential(nn.Upsample(scale_factor=2), conv(ni, nf))
他们在论文中提到的一件事是他们在零填充中遇到了很多问题,他们解决这个问题的方法是在开始时添加 40 像素的反射填充。所以我也做了同样的事情,然后他们在他们的 Res 块中的卷积中使用了零填充。现在如果你的 Res 块中的卷积中有零填充,那么你的 ResNet 的两部分将不再相加,因为你在每个卷积的每一侧都失去了一个像素。所以我的ResSequential变成了ResSequentialCenter,我去掉了那些好细胞的每一侧的最后 2 个像素。除此之外,这基本上和以前一样。
class StyleResnet(nn.Module): def __init__(self): super().__init__() features = [ nn.ReflectionPad2d(40), conv(3, 32, 9), conv(32, 64, stride=2), conv(64, 128, stride=2) ] for i in range(5): features.append(res_block(128)) features += [ upsample(128, 64), upsample(64, 32), conv(32, 3, 9, actn=False) ] self.features = nn.Sequential(*features) def forward(self, x): return self.features(x)
风格图像
然后我们可以引入我们的星夜图片。
style_fn = PATH/'style'/'starry_night.jpg' style_img = open_image(style_fn) style_img.shape ''' (1198, 1513, 3) ''' plt.imshow(style_img);

h,w,_ = style_img.shape rat = max(sz/h,sz/h) res = cv2.resize(style_img, (int(w*rat), int(h*rat)), interpolation=cv2.INTER_AREA) resz_style = res[:sz,-sz:]
我们可以调整大小。
plt.imshow(resz_style);

我们可以通过我们的变换
style_tfm,_ = tfms1style_tfm = np.broadcast_to(style_tfm[None], (bs,)+style_tfm.shape)
为了让我的大脑更容易处理这种方法,我拿出了我们的变换风格图像,经过 3 x 256 x 256 的变换后,我制作了一个小批量。我的批量大小是 24 — 有 24 个副本。这样做可以更容易地进行批量算术,而不用担心一些广播问题。它们实际上并不是 24 个副本。我使用np.broadcast基本上伪造了 24 个部分。
style_tfm.shape(24, 3, 256, 256)
感知损失
所以就像以前一样,我们创建了一个 VGG,抓住了最后一个块。这一次我们要使用所有这些层,所以我们保留了所有直到第 43 层的内容。
m_vgg = vgg16(True) blocks = [ i-1 for i,o in enumerate(children(m_vgg)) if isinstance(o,nn.MaxPool2d) ] blocks, [m_vgg[i] for i in blocks[1:]] ''' ([5, 12, 22, 32, 42], [ReLU(inplace), ReLU(inplace), ReLU(inplace), ReLU(inplace)]) ''' vgg_layers = children(m_vgg)[:43] m_vgg = nn.Sequential(*vgg_layers).cuda().eval() set_trainable(m_vgg, False) def flatten(x): return x.view(x.size(0), -1) class SaveFeatures(): features=None def __init__(self, m): self.hook = m.register_forward_hook(self.hook_fn) def hook_fn(self, module, input, output): self.features = output def remove(self): self.hook.remove() def ct_loss(input, target): return F.mse_loss(input,target) def gram(input): b,c,h,w = input.size() x = input.view(b, c, -1) return torch.bmm(x, x.transpose(1,2))/(c*h*w)*1e6 def gram_loss(input, target): return F.mse_loss(gram(input), gram(target[:input.size(0)]))
所以现在我们的组合损失将加上第三个块的内容损失,再加上所有块的 Gram 损失,使用不同的权重。再次回到尽可能正常的一切,我又回到了使用均方误差。基本上发生的事情是我在训练这个模型时遇到了很多困难。所以我逐渐去掉了一个又一个技巧,最终只是说“好吧,我只会让它尽可能平淡”。
上周的 Gram 矩阵是错误的。它只适用于批量大小为 1,而我们只有一个批量大小,所以没问题。我使用的是矩阵乘法,这意味着每个批次都与其他每个批次进行比较。实际上,你需要使用批量矩阵乘法(torch.bmm),它对每个批次执行矩阵乘法。所以这是需要注意的一点。
class CombinedLoss(nn.Module): def __init__(self, m, layer_ids, style_im, ct_wgt, style_wgts): super().__init__() self.m,self.ct_wgt,self.style_wgts = m,ct_wgt,style_wgts self.sfs = [SaveFeatures(m[i]) for i in layer_ids] m(VV(style_im)) self.style_feat = [ V(o.features.data.clone()) for o in self.sfs ] def forward(self, input, target, sum_layers=True): self.m(VV(target.data)) targ_feat = self.sfs[2].features.data.clone() self.m(input) inp_feat = [o.features for o in self.sfs] res = [ct_loss(inp_feat[2],V(targ_feat)) * self.ct_wgt] res += [ gram_loss(inp,targ)*wgt for inp,targ,wgt in zip(inp_feat, self.style_feat, self.style_wgts) ] if sum_layers: res = sum(res) return res def close(self): for o in self.sfs: o.remove()
所以我有 Gram 矩阵,我在 Gram 矩阵之间进行均方误差损失,我用风格权重对它们进行加权,所以我创建了那个 ResNet。
m = StyleResnet() m = to_gpu(m)learn = Learner(md, SingleModel(m), opt_fn=optim.Adam)
我创建了我的组合损失,传入 VGG 网络,传入块 ID,传入变换后的星夜图像,你会看到这里的开始,我通过我的 VGG 模型进行了前向传递,以保存其特征。请注意,现在非常重要的是我不做任何数据增强,因为我保存了特定未增强版本的风格特征。所以如果我增强它,可能会出现一些小问题。但没关系,因为我有所有的 ImageNet 要处理。我实际上不需要做数据增强。
learn.crit = CombinedLoss( m_vgg, blocks[1:], style_tfm, 1e4, [0.025,0.275,5.,0.2] ) wd=1e-7 learn.lr_find(wds=wd) learn.sched.plot(n_skip_end=1) ''' 1%|▏ | 7/482 [00:04<05:32, 1.43it/s, loss=2.48e+04] 53%|█████▎ | 254/482 [02:27<02:12, 1.73it/s, loss=1.13e+12] '''

lr=5e-3
所以我有我的损失函数,我可以继续拟合[1:24:06]。这里一点聪明的地方都没有。
learn.fit(lr, 1, cycle_len=1, wds=wd, use_clr=(20,10)) ''' epoch trn_loss val_loss 0 105.351372 105.833994 [array([105.83399])] ''' learn.save('style-2') x,y=md.val_ds[201] learn.model.eval() preds = learn.model(VV(x[None])) x.shape,y.shape,preds.shape ''' ((3, 256, 256), (3, 256, 256), torch.Size([1, 3, 256, 256])) '''
最后,我有我的sum_layers=False,这样我就可以看到每个部分的样子,看到它们是平衡的。然后我终于可以弹出它
learn.crit(preds, VV(y[None]), sum_layers=False) ''' [Variable containing: 53.2221 [torch.cuda.FloatTensor of size 1 (GPU 0)], Variable containing: 3.8336 [torch.cuda.FloatTensor of size 1 (GPU 0)], Variable containing: 4.0612 [torch.cuda.FloatTensor of size 1 (GPU 0)], Variable containing: 5.0639 [torch.cuda.FloatTensor of size 1 (GPU 0)], Variable containing: 53.0019 [torch.cuda.FloatTensor of size 1 (GPU 0)]] ''' learn.crit.close() _,axes=plt.subplots(1,2,figsize=(14,7)) show_img(x[None], 0, ax=axes[0]) show_img(preds, 0, ax=axes[1])

所以我提到这应该很容易,但实际上花了我大约 4 天,因为我发现这个真的很麻烦,才让它正常工作[1:24:26]。所以当我终于早上起床时,我对 Rachel 说“猜猜,它训练正确了。” Rachel 说“我从来没想过会发生这种事。” 它看起来一直很糟糕,真的是关于得到精确的内容损失和风格损失的混合以及风格损失的层次的混合。最糟糕的部分是训练这个该死的 CNN 需要很长时间,我真的不知道应该训练多久才能确定它表现不佳。我应该只是继续训练吗?我不知道所有这些细节似乎都没有稍微改变它,但它总是会完全崩溃。所以我提到这部分是为了提醒大家,最终你在这里看到的答案是在我整整一周把自己逼疯几乎总是不起作用,直到最后一刻它终于起作用。即使对于那些看起来不可能困难的事情,因为那是将两个我们已经有的工作结合在一起。另一个是要小心解释作者声称的内容。

让这个风格转移起作用真的很麻烦[1:26:10]。做完之后,我想为什么我要费这个劲,因为现在我有了一个需要花几个小时来创建一个可以将任何类型的照片转换为一个特定风格的网络。我觉得我很少会想要这样做。我能想到这有用的唯一原因是在视频上做一些艺术性的东西,我想把每一帧都转换成某种风格。这是一个极其狭隘的想法。但当我看了论文后,表格上写着“哦,我们比 Gatys 的方法快一千倍”,这种说法显然毫无意义。这是一个极其误导人的说法,因为它忽略了为每种风格进行的所有训练时间,我发现这很令人沮丧,因为像斯坦福这样的团体显然更清楚或应该更清楚,但仍然我猜学术界鼓励人们提出这些荒谬的夸大宣称。它也完全忽视了这个极其敏感的繁琐的训练过程,所以这篇论文一出来就被如此广泛接受。我记得每个人都在推特上说“哇,你知道这些斯坦福的人找到了这种方式可以让风格转移快一千倍。” 显然说这话的人是该领域的顶尖研究人员,显然他们中没有人真正理解,因为没有人说“我不明白为什么这有任何用处,而且我尝试过,让它正常工作真的很麻烦。” 直到 18 个月后,我最终回头看,有点想“等一下,这有点愚蠢。” 所以我认为这就是为什么人们没有对此进行后续研究,以创造真正令人惊叹的最佳实践和更好的方法,就像论文中的超分辨率部分一样。我认为答案是因为这很愚蠢。所以我认为论文中的超分辨率部分显然不愚蠢。它已经得到改进,现在我们有了很棒的超分辨率。我认为我们可以从中得到很棒的降噪、很棒的着色、很棒的倾斜去除、很棒的交互式伪影去除等等。所以我认为这里有很多很酷的技术。它还利用了我们一直在学习和不断进步的许多东西。
fast.ai 深度学习笔记(七)(3)https://developer.aliyun.com/article/1482690
