【GPU】GPU CUDA 编程的基本原理是什么?
作者:董鑫
想学好 CUDA 编程, 第一步就是要理解 GPU 的硬件结构, 说到底, CUDA 的作用就是最大程度压榨出 NVIDIA GPU 的计算资源.
想要从零理解起来, 还有有些难度. 这里希望能够用最简单的方式把一些最基本的内容讲清楚. 所以, 本文以易懂性为主, 牺牲了一些完全准确性.
GPU 结构
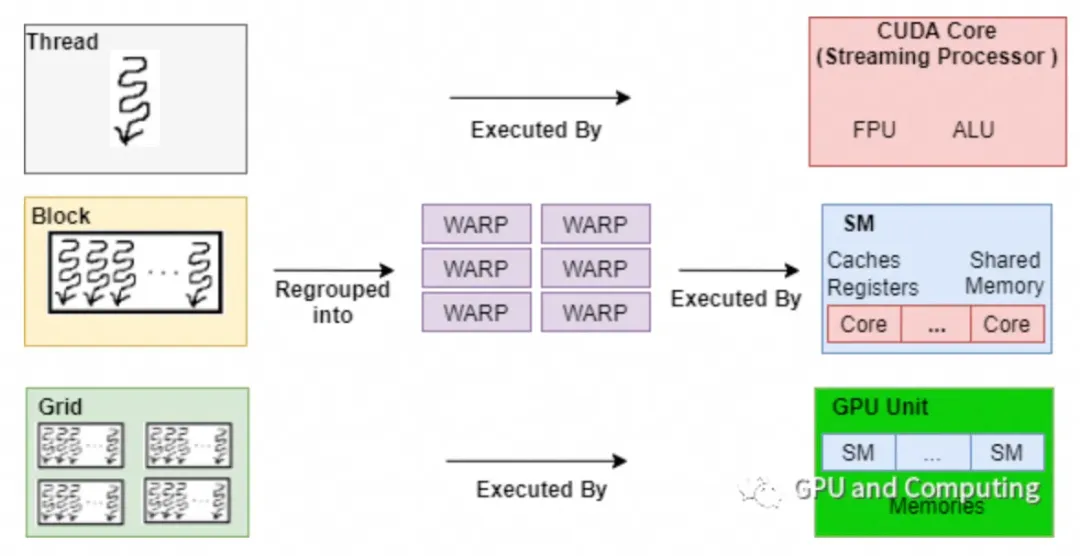
这是 GPU 的基本结构. CUDA 编程主打一个多线程 thread.
多个 thread 成为一个 thread block, 而 thread block 就是由这么一个 Streaming Multiprocessor (SM) 来运行的.
CUDA 编程中有一个 “同一个 block 内的 thread 共享一段内存”. 这恰好对应上图下面的那段 “Shared Memory”.
另外, 一个 SM 里面有多个 subcore (本图中有 4 个), 每个 subcore 有一个 32 thread 的 warp scheduler 和 dispatcher, 这个是跟 CUDA 编程中 warp 的概念有关的.
另外, 我们还要理解 GPU 的金字塔状的 Memory 结构.
最快的是 register, 但是非常小.
其次是 l1 cache, 也就是前面提到的 shared memory.
Global memory 就是我们常说的 显存 (GPU memory). 其实是比较慢的.
Global memory 和 shared memory 之间是 L2 cache, L2 cache 比 global memory 快. 每次 shared memory 要到 global memory 找东西的时候, 会去看看 l2 cache 里面有没有, 有的话就不用去 global memory 了.
有的概率越大, 我们说 memory hit rate 越高, CUDA 编程的一个目的也是要尽可能提高 hit rate. 总的来说,
我们就是希望能够尽可能多的利用比较快的 SRAM (shared memory). 但是因为 SRAM 比较小, 所以基本原则就是: 每次往 SRAM 移动数据的, 都可能多的用这个数据. 避免来来回回的移动数据.
其实, 这种 idea 直接促成了最近大火的 FlashAttention. FlashAttention 发现很多操作计算量不大, 但是 latency 很高, 那肯定是不符合上述的 “每次往 SRAM 移动数据的”. 怎么解决呢?
Attention 基本上是由 matrix multiplication 和 softmax 构成的. 我们已经知道了 matrix multiplication 是可以分块做的, 所以就剩下 softmax 能不能分块做? softmax 其实也是可以很简单的被分块做的. 所以就有了 FlashAttention. 关于 GPU Architecture 更进一步细节推荐大家看这个:
一些跟 CUDA 有关的库
首先先理一下 NVIDIA 那么多库, 他们之间到底是什么关系?
这里以三个库为例 CuTLASS , CuBLAS, CuDNN .
从名字看, 他们都是用 CUDA 写出来的.总结起来, 他们之间的区别就是封装程度不同, 专注的领域不同.
CuTLASS 和 CuBLAS 都是比较专注于最基本的线性代数的运算的, 比如 矩阵乘法, 矩阵加法, 等等.
而 CuDNN 则是更进一步, 将关注点落在了 Deep Neural Network 上面了. 比如, DNN 中非常常见的 convolution 操作, 是通过 矩阵乘法 来实现的.
那么, CuDNN 做的工作更像是, 完成从 convolution 到 矩阵乘法 的转换, 转换之后, 就可以复用 CuTLASS 或者 CuBLAS 来做.
当前, DNN 里面不全都是矩阵乘法, 遇到一些特殊的算子, CuDNN 也会自己实现一些.而 CuTLASS 和 CuBLAS 之间的区别, 更像是”傻瓜程度” 不同.
CuBLAS 可以理解成 英伟达 给你找了一堆傻瓜相机, 每个相机都针对某个非常非常具体的场景优化到了极致, 你唯一要做的就是根据你的场景找到最适合相机.
因为每个相机已经被写死了, 你不知道英伟达到底做了什么黑魔法优化, 你也没办法去根据想法进一步修改.
虽然 CuBLAS 闭源, 不灵活, 但是只要场景找对了, 效果确实拔群.
而 CuTLASS 是一个模板库, 相当于有这么一些不同 系列 的相机, 有拍夜景, 拍近景的, 等等. 当然, 就夜景而言, 肯定还有各种不同场景, 对应不同配置可以尝试. 在 CuTLASS 你可以尝试不同的配置, 直到你满意为止.
矩阵乘法 (CuTLASS)
假设做 GEMM (general matrix multiplication), 我们以 CuTLASS 里面的实现来讲解
C = A * B
A 是 M x K
B 是 K x N
这张图的信息量很大.
1. 第一部分:
是关于如何拆分一个大矩阵乘法到多个小矩阵乘法. 也就是说, 这段时间我们就 focus on 某个小矩阵的计算. 其他部分我们不管.
这样, 因为不同小矩阵之间是完全独立的, 就可以很容易实现并行.
具体来说 也是需要多次紫色和黄色部分的矩阵乘法. 紫色从左到右滑动, 黄色从上到下滑动. 他们的滑动的次数是完全一样.
他们每滑动一次, 就是一次矩阵乘法(及加法, 因为要把乘出来的结果加到之前的结果之上). 下图是滑动到某个位置的情况.
之所以绿色部分没有高亮, 是因为要把所有都滑动完, 才能得到最终绿色部分的结果.
2. 第二部分:
先忽略绿色部分.注意, 这紫色的一整行和黄色的一整列都是由一个 thread block 处理的.为什么? 因为他们都要在同一块 C tile 上面累加.
如果切换 thread block 的话, 就会比较麻烦.理论上来说, 紫色的一整行和黄色的一整列都要被 load 到 shared memory.
但是, 因为我们每次只会用到 紫色高亮部分 和 黄色高亮部分, 所以完全可以声明一块小内存, 每次只 load 一小块 (A tile and B tile), 用完之后就可以覆盖掉, 用来 load 下一个滑动位置.具体到某一次滑动,
把 紫色高亮部分 (A tile) 和 黄色高亮部分 (B tile) 从 global memory 移动到 shared memory (SMEM).接下来要做的就是计算 A tile * B tile, 然后把结果累加到 C tile 上面.好了, 现在我们明确两点:A tile 和 B tile 都在 shared memory 了.
也就是说, thread block 里面的每一个 thread 都可以看到 A tile 和 B tile.A tile 和 B tile 每次窗口滑动是需要重新 load 的,
但是 C tile 每次窗口滑动是需要在原来的基础上更新的.因为 C tile 一直需要更新, 而且这个更新是计算驱动的 (不是 load 驱动的),
所以我们最好把 C tile 放到 register (RF) 里面去. register 是一种比 shared memory 更快的内存, 而且 register 是跟 thread 相关的.
其实计算的时候, A tile 和 B tile 也必须从 shared memory 被 load 到 register. 只是 C tile 一直待在 register 里面等待被更新.
3. 第三部分:
刚刚讲了, 我们需要把 C tile held 在 register, 而 register 有是跟具体某个 thread 是关联的. 所以我们自然需要根据 thread 再来划分 C tile.
但是, CUDA 其实在 thread 和 thread block 还有一层叫做 warp. 我们可以暂时理解把 warp 一种计量单位: 1 warp = 32 thread.在上述例子中, 一个 thread block 被分成了八个 warp.每个 warp 承担了 C tile 中的 16*8 个数字.
假设每个数字是 32bit, 那么恰好是一个 register 的容量.那么, 也就是说, 我们需要 16*8 个 registers. 前面讲了一个 warp 是 32 thread. 这并不矛盾. 因为一个 thread 可以配有多个 registers.
但是, 某个 thread 是不定访问 其他 thread 的 register 的. CUDA 之所以这么限制, 主要原因还是 thread 之间做 sync 太复杂.这里, 要算一个 warp 对应的结果, 还是跟前面的讲的一样. 横向滑动紫色高亮块, 纵向滑动黄色高亮块,
每次滑动, 都是将当前高亮块从 shared memory load 到 register 中, 计算矩阵乘法 (虽然看着像向量, 但是不一定是向量), 然后累加到 C warp tile 上面. 正如前面所说, C warp tile 一直都是在 register 上面的.
4. 第四部分:
最终, 还是要落到单个 thread 上面.
这里的 Warp tile 代表这一整个 tile 都是由一个 Warp 完成的.先看左上角灰色的部分, 后面的内容也是在这个灰色的部分.数一下, 恰好是 32 个格子.
而我们知道一个 Warp 是 32 个 thread. 也就是说, 一个 thread 处理一个灰色的格子. 这 32 个格子中, 有一个绿色的格子 (先不要看另外三个绿色的),
这个绿色的格子就是我们现在要讨论的 32 个 thread 中的某个 thread.实际上, 这个绿色的格子里面有 16 个数, 也就说是一个 44 的迷你矩阵.
也就说, 一个 thread 要处理这样一个 44 的矩阵. 那么, 既然想得到这样 44 的矩阵, 就需要读入 41 的紫色部分, 1*4 的黄色部分.
好, 现在我们可以跳出左上角灰色部分了. 我们发现这个 Warp tile 还有剩下三个部分, 但是在左上角灰色部分我们已经这个 Warp 中 32 个 thread 用过一遍了, 怎么办?
谁说 Warp 只能用一遍? 完全可以让这个 Warp keep alive, 再如法炮制地去分别按顺序处理 (所以这里其实在时间上不是并行的) 剩下的三个部分.这个时候, 我们再看一个thread的工作量.
首先, 一个 thread 要被用 4 次, 然后每次要处理 4x4 的迷你矩阵,
所以总的来看, 一个 thread 相当于处理了一个 8x8 的矩阵. 这就是上图右边想表达的意思.