向量检索服务 DashVector免费试用进行中,玩转大模型搜索,快来试试吧~
了解更多信息,请点击:https://www.aliyun.com/product/ai/dashvector
为什么现在大家都在谈论向量数据库呢?
在深入探讨向量数据库是什么之前,有什么可以解释这个领域的活动和投资热潮吗?
大型语言模型(LLM)的时代
在2022年11月,OpenAI发布了ChatGPT的早期演示(它是GPT 3.5及以上版本的OpenAI接口),随后它迅速成为历史上增长最快的应用程序,在仅仅5天内就获得了一百万用户 !事实上,如果你查看一些主要的开源向量数据库存储库在GitHub上的历史记录,可以清楚地看到在2022年11月发布ChatGPT以及随后在2023年3月发布ChatGPT插件后,其中一些存储库的星标计数出现了明显的增长。这些因素以及它们在Hacker News和流行媒体等网站上的相关帖子,是为什么在这个领域出现了如此多的活动的重要原因之一。

依赖大型语言模型的问题
大型语言模型(LLMs)是生成型的,意味着它们根据用户的提示以顺序方式生成有意义、连贯的文本。然而,当使用LLMs回答人类的问题时,它们经常会产生与问题无关或事实上不正确的结果。
- LLMs经常会产生幻觉,即虚构信息,例如指向不存在的URL或编造不存在的数字。
- LLMs学习/记忆其训练数据的压缩版本,虽然它们学习得很好,但并不完美—模型对数据的内部表示总是会“丢失”一些信息。
- LLMs无法知道其训练完成后发生的事实。
向量数据库有助于解决这些问题,它们作为底层存储层,可以被LLMs高效地查询以检索事实。与传统数据库不同,向量数据库专门将数据以向量的形式进行本地表示。因此,我们现在可以构建应用程序,让LLMs位于包含最新、最新的事实数据(远远超过LLMs的训练日期)的向量存储层之上,并使用它们来“基于事实”地约束模型,缓解幻觉问题。 尽管向量数据库(如Vespa、Weaviate、Milvus)在LLMs之前就已经存在,但自ChatGPT发布以来,开源社区以及向量数据库供应商的营销团队迅速意识到它们在搜索和检索等主流用例中与高质量文本生成的结合中的潜力。这解释了为什么在向量数据库领域出现了绝对的风投资金热潮!
什么是嵌入?
向量数据库不仅存储原始数据(可以是图像、音频或文本),还存储其编码形式:嵌入(embeddings)。这些嵌入实质上是存储数据的上下文表示的数字列表(即向量)。直观地说,当我们提到“嵌入”时,我们指的是实际存在于更高维度中的数据(图像、文本、音频)的压缩、低维表示。 在存储层内,数据库以m个向量堆栈的形式存储,每个向量使用n个维度表示一个数据点,总大小为m×n。为了查询性能的原因,这些堆栈通常通过分片进行划分。

嵌入是如何生成的?
在自然语言处理(NLP)中,Transformer的革命为工程师们提供了高效且可扩展地生成这些压缩表示或嵌入的丰富手段。
- 一种流行的方法是使用开源库Sentence Transformers,可以通过Hugging Face模型中心或直接从源代码的reposentence-transformers获取。
- 另一种(更昂贵的)方法是使用许多API服务:OpenAI嵌入API或者Cohere嵌入API
需要记住的是,底层向量的维度越低,嵌入空间中的表示就越紧凑,这可能会影响下游任务的质量。
将嵌入存储在矢量数据库中
由于向量数据库在嵌入空间中的可操作性,它们对于多种形式的数据(文本、图像、音频)的语义或相似性搜索非常有用。在语义搜索中,用户发送的输入查询(通常是自然语言)被转换为向量形式,与数据本身在相同的嵌入空间中,以便返回与输入查询最相似的前k个结果。下面是这个过程的可视化示例。

如何计算相似度?
不同的向量数据库提供不同的相似度计算指标,但对于文本数据,最常用的两个指标如下:
- 点积(Dot product):产生一个非归一化的任意大小的值。
- 余弦距离(Cosine distance):产生一个归一化的值(介于-1和1之间)。
考虑一个简化的例子,我们将红葡萄酒和白葡萄酒的标题在二维空间中进行向量化,其中水平轴表示红葡萄酒,垂直轴表示白葡萄酒。在这个空间中,距离较近的点表示具有相似单词或概念的葡萄酒,而距离较远的点则没有太多共同之处。余弦距离被定义为连接每个葡萄酒在嵌入空间中位置与原点之间的线之间的夹角的余弦值。

一幅可视化图将使这更加直观。

在左边,两种葡萄酒(Reserve White和Toscana Red)在词汇和概念上几乎没有共同之处,因此它们的余弦距离接近零(在向量空间中它们是正交的)。在右边,来自纳帕谷的两种Zinfandel葡萄酒有更多的共同之处,因此它们的余弦相似度更接近1。极限情况下,余弦距离为1;当然,在实际情况中,实际数据存在于更高维的向量空间中(除了葡萄酒的品种之外还有许多其他轴),无法在二维平面上可视化,但余弦相似度的原理仍然适用。
可扩展的最近邻搜索
一旦向量被生成并存储,当用户提交一个搜索查询时,相似性搜索的目标是提供与输入查询向量最相似的前k个向量。再次,我们可以在简化的二维空间中可视化这一过程。

最简单的方法是使用所谓的k最近邻(kNN)方法,将查询向量与数据库中的每个向量进行比较。然而,随着数据规模扩大到数百万(甚至数十亿)个数据点,这种方法很快变得过于昂贵,因为所需的比较次数与数据呈线性增长关系。
近似最近邻(ANN)
每个现有的向量数据库都专注于通过一类称为近似最近邻(ANN)搜索的算法,使搜索在数据集的大小上高效无论如何。与在数据库中的每个向量之间进行详尽比较不同,近似搜索会寻找最近邻,从而在结果的准确性上有一定的损失(可能并不总是返回真正的最近邻),但使用ANN算法可以获得巨大的性能提升。
索引
通过索引将数据存储在向量数据库中,索引是指创建称为索引的数据结构,通过快速缩小搜索空间来实现对向量的高效查找。通常使用的嵌入模型将向量存储在维度约为10^2到10^3的范围内,而ANN算法则尽可能高效地在时间和空间上捕捉数据的实际复杂性。 在各种可用的向量数据库中使用了许多索引算法,它们的详细信息超出了本文的范围,但为了参考,下面列出了其中一些算法。
- 倒排文件索引(IVF)
- 分层可导航小世界(HNSW)图
- Vamana(在DiskANN实现中使用)
把它们放在一起,将上述所有想法结合起来,形成一个关于向量数据库实际是什么的概念图:

对于从业者来说,每个数据库供应商如何实现可扩展性(通过Kubernetes、分片、流式处理等)的具体细节并不重要 - 这取决于每个供应商在延迟、成本和可扩展性之间权衡的系统架构。
存储层和数据摄入
- 数据(存储在本地或云端)经过嵌入模型转换为向量形式,并通过API网关摄入到向量数据库的存储层中。
- 数据在索引过程中进行分区/分片,以实现可扩展性和更快的查找。
- 查询引擎与存储层紧密集成,通过数据库的ANN实现快速检索最近邻。
应用程序层
- 用户通过应用程序的用户界面向嵌入模型发送查询,该模型将输入查询转换为与数据处于相同嵌入空间的向量。
- 向量化的查询通过API网关发送到查询引擎:多个传入的查询被异步处理,并将前k个结果发送回用户。
扩展矢量数据库以服务其他功能
上述用例展示了向量数据库如何在规模上实现了语义搜索,然而,这只是冰山一角:向量数据库用于支持许多下游功能。
混合搜索系统
在Colin Harman的优秀评论文章中,他描述了许多公司由于当前存在大量的向量数据库营销材料,对于搜索和检索领域存在“隧道视野”。指出向量数据库并不是搜索的万灵药 ,它们在语义搜索方面非常出色,但在许多情况下,传统的关键字搜索可以产生更相关的结果并提高用户满意度。为什么会这样?这主要是因为基于余弦相似度等指标进行排名会导致具有更高相似度分数的结果出现在可能包含特定输入关键字的部分匹配之上,从而降低了它们对最终用户的相关性。 然而,纯关键字搜索也有其局限性 , 如果用户输入的术语在语义上与存储的数据相似(但不完全相同),则可能有用和相关的结果将不会返回。由于这种权衡,搜索和检索的实际应用案例需要关键字和向量搜索的结合,其中向量数据库是关键组成部分(因为它们存储了嵌入向量,实现了语义相似性搜索,并能够扩展到非常大的数据集)。 总结以上观点:
- 关键字搜索:当用户知道自己在寻找什么并期望结果与搜索词中的确切短语匹配时,可以找到相关、有用的结果。不需要向量数据库。
- 向量搜索:当用户不确定自己在寻找什么时,可以找到相关的结果。需要向量数据库。
- 混合关键字+向量搜索:通常结合全文关键字搜索和向量搜索的候选结果,并使用交叉编码器模型重新排序它们。
可以通过下面的图表有效地进行可视化:

BM25是某些数据库(如Elasticsearch、Opensearch、MongoDB)中用于关键字搜索的最常见的索引算法。它通过考虑关键字词频与其逆文档频率(IDF)的关系来生成稀疏向量。相比之下,向量数据库通常使用稠密向量来编码和存储文本嵌入(与BM25不同,向量中的所有术语都不为零),通常通过类似BERT的双编码器模型来实现,该模型为一对文档生成一个句子嵌入,然后可以进行比较以生成余弦相似度分数。
理解双编码器和交叉编码器之间的区别
为了有效地进行混合搜索,需要通过BM25(关键字搜索)和余弦相似度(向量搜索)获得的搜索结果候选项进行组合,这需要使用交叉编码器。如下图所示,这是一个下游步骤,允许将两个句子同时传递给像BERT这样的编码器模型。与用于生成句子嵌入的双编码器不同,交叉编码器不会生成嵌入向量,而是通过softmax层为一对句子分配一个介于0和1之间的分数,从而对其进行分类。这被称为重新排序,是一种非常强大的方法,可以获得结合了关键字搜索和向量搜索优势的结果。

需要注意的是:通过交叉编码器进行重新排序是一个昂贵的步骤,因为它在查询时需要使用一个Transformer模型。这种方法在搜索质量对于使用案例至关重要时使用,并且需要更多的计算资源(通常是GPU)和调优时间,以确保应用程序按预期运行。
生成式问答:“与数据聊天”
随着强大的语言模型(如GPT-4)的出现,我们可以有效地将应用程序的用户体验与存储在向量数据库中的干净、事实性信息进行整合,使用户能够通过自然语言查询他们的数据。因为问答可能涉及的不仅仅是信息检索(可能需要对数据的部分进行分析,而不仅仅是查询),在应用程序界面和向量数据库之间包含一个基于代理的框架(如LangChain7)可能比直接连接向量数据库更加强大。
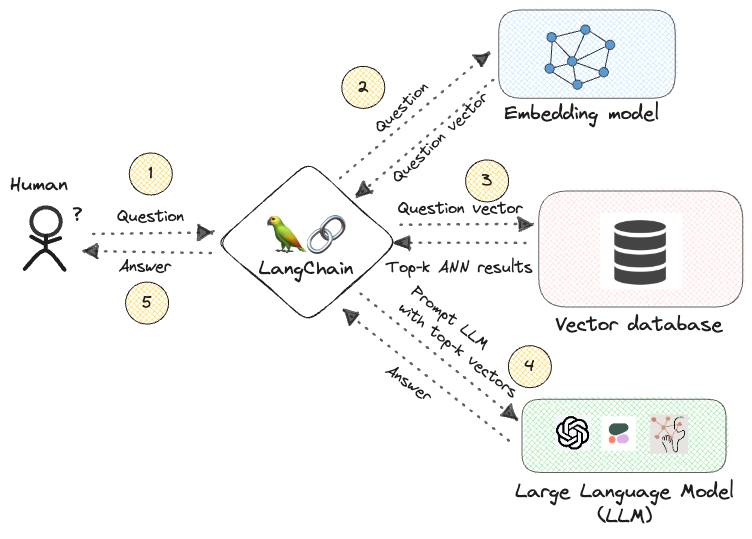
由于向量数据库将要查询的数据存储为嵌入向量,并且语言模型(LLM)也将其内部的知识编码为嵌入向量,因此它们在生成式问答应用中是天然的配对。向量数据库充当知识库的功能,而LLM可以直接在嵌入空间中查询数据的子集。可以使用以下方法进行操作:
- 用户通过界面用自然语言提出问题。
- 问题的文本被传递给嵌入模型(双编码器),然后返回一个句子嵌入向量。
- 问题向量被传递给向量数据库,通过ANN搜索返回与之最相似的前k个结果。这一步非常关键,因为它大大缩小了LLM在下一步中的搜索空间。
- 构建一个LLM提示(基于开发者预定义的模板),将其转换为嵌入向量,并传递给LLM。使用类似LangChain的框架可以方便地执行此步骤,因为可以动态构建提示,并调用LLM的本地嵌入模块,而无需为每个工作流编写大量自定义代码。
- LLM在前k个结果中搜索信息,并生成问题的答案。
- 答案发送回用户。
上述工作流程可以以许多方式进行扩展。例如,如果用户的问题涉及从数据库中获取的数字进行一些算术运算(LLM在这方面的表现往往不好),LangChain代理可以确定首先需要进行算术运算。然后,它将从前k个结果中提取的数值信息传递给计算器API,执行计算,然后将答案发送回用户。通过这种可组合的工作流程,可以看到向量数据库为生成式问答聊天界面提供了强大的支持。
结论
结合LLM和向量数据库可以构建许多其他有用的应用程序。然而,了解向量数据库的一些潜在限制是很重要的:
- 在搜索应用程序中,它们不一定优先考虑关键词短语的精确匹配来确定相关性。
- 存储和查询的数据必须适应所使用的嵌入模型的最大序列长度(对于类似BERT的模型,这个长度不超过几百个词)。目前,最好的方法是利用像LangChain和LlamaIndex这样的框架,将数据分块或压缩成适合底层模型上下文的固定大小的向量。
向量数据库非常强大,可以明确定义业务案例并研究手头的工具,有效地将它们结合起来解决现实世界的问题,希望这个关于向量数据库的解释对您有所帮助。
免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector