
“我正在参加「掘金·启航计划」”
这是我关于《一种轻松且客观介绍大模型方式,避免过度解读》第一篇
一、前言
这篇文章旨在为没有计算机科学背景的读者提供一些关于ChatGPT及其类似的人工智能系统(如GPT-3、GPT-4、Bing Chat、Bard等)如何工作的原理。ChatGPT是一种聊天机器人,建立在一个大型语言模型之上,用于对话交互。这些术语可能比较晦涩难懂,我将对其进行解释。同时,我们将讨论它们背后的核心概念,而且本文并不需要读者具备任何技术或数学方面的背景知识。我们将大量使用比喻来解释相关概念,以便更好地理解它们。我们还将讨论这些技术的意义,以及我们应该期待或不应该期待大型语言模型如ChatGPT所能做的事情。
接下来我们将以尽可能不使用专业术语的方式,从基础的“什么是人工智能”开始,逐步深入讨论与大型语言模型和ChatGPT相关的术语和概念,并将使用比喻来解释它们。同时,我们也将谈论这些技术的意义,以及我们应该期待它们能够做什么或不应该期待它们能够做什么。
二、什么是人工智能
首先,让我们从一些基本术语开始,这些术语你可能经常听到。那么什么是人工智能呢?
人工智能:指一种能够表现出类似于人类所认为的智能行为的实体。用“智能”来定义人工智能有些问题,因为“智能”本身并没有一个清晰的定义。但是,这个定义仍然比较恰当。它基本上意味着,如果我们看到一些人造的东西,它们能够进行有趣、有用、看起来有一定难度的行为,那么我们可能会说它们具有智能。例如,在电脑游戏中,我们通常称计算机控制的角色为“AI”。这些角色大多是基于if-then-else代码的简单程序(例如,“如果玩家在射程范围内,则开火,否则移动到最近的石头后躲藏”)。但是,如果这些角色可以保持我们的参与度和娱乐性,同时不做任何显然愚蠢的事情,那么我们可能会认为它们比实际上更为复杂。
一旦我们了解了某个东西的工作原理,我们可能就不会觉得它很神奇,而是期望在幕后有更为复杂的东西。这完全取决于我们对幕后发生的事情的了解程度。
重要的一点是,人工智能不是魔术。因为它不是魔术,所以它是可以被解释的。
三、 什么是机器学习
另一个与人工智能经常相关联的术语是机器学习。
机器学习:一种通过收集数据、形成模型,然后执行模型的方式来创建行为的方法。有时候,手动创建一堆if-then-else语句以捕捉某些复杂现象(比如语言)是很困难的。在这种情况下,我们尝试找到大量数据,并使用能够在数据中找到模式的算法进行建模。
那么什么是模型呢?模型是某种复杂现象的简化版本。例如,汽车模型是真实汽车的更小、更简单版本,它具有真实汽车许多属性,当然并不意味着要完全替代原始版本。模型汽车可能看起来很真实,在实验的时候很有用。

就像我们可以制造一个更小、更简单的汽车一样,我们也可以制造一个更小、更简单的人类语言模型。我们使用“大型语言模型”这个术语,因为这些模型从需要使用的内存(显存)量的角度来看是非常大的。目前生产中最大的模型,例如ChatGPT、GPT-3和GPT-4,非常庞大,需要运行在数据中心服务器上的超级计算机才能创建和运行。
四、什么是神经网络
有很多方法可以通过数据来学习一个模型,其中神经网络就是其中一种方法。这种技术大致基于人脑的结构,人脑由一系列互相连接的神经元组成,神经元之间传递电信号,使我们能够完成各种任务。神经网络的基本概念在20世纪40年代就已经被发明了,如何训练神经网络的基本概念则是在20世纪80年代发明的,当时神经网络非常低效,直到2017年左右计算机硬件升级,我们才可以大规模地使用它们。
但是,个人比较喜欢用电路的隐喻来模拟神经网络。通过电阻、电流经过电线的流动,我们可以模拟神经网络的工作。
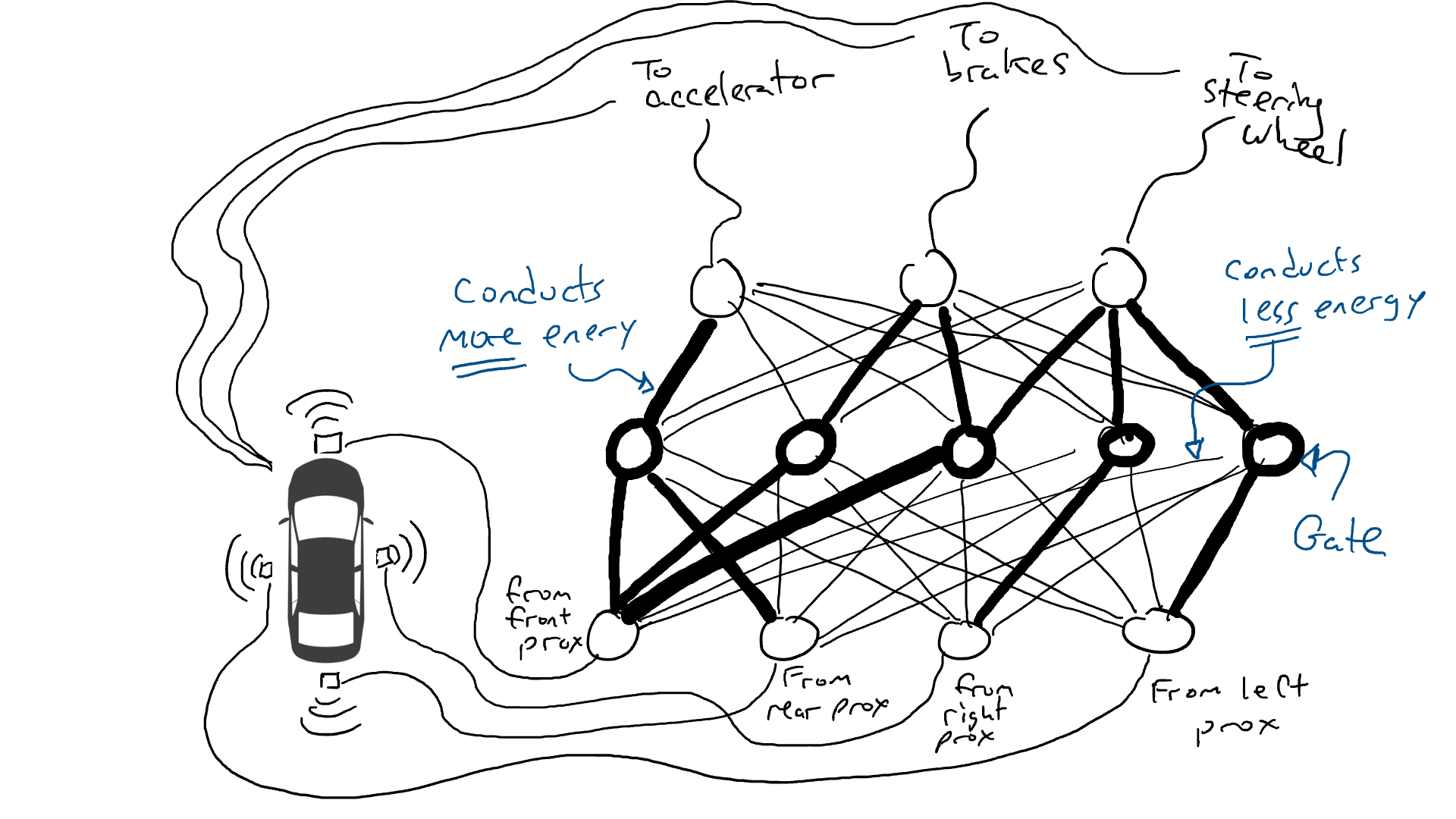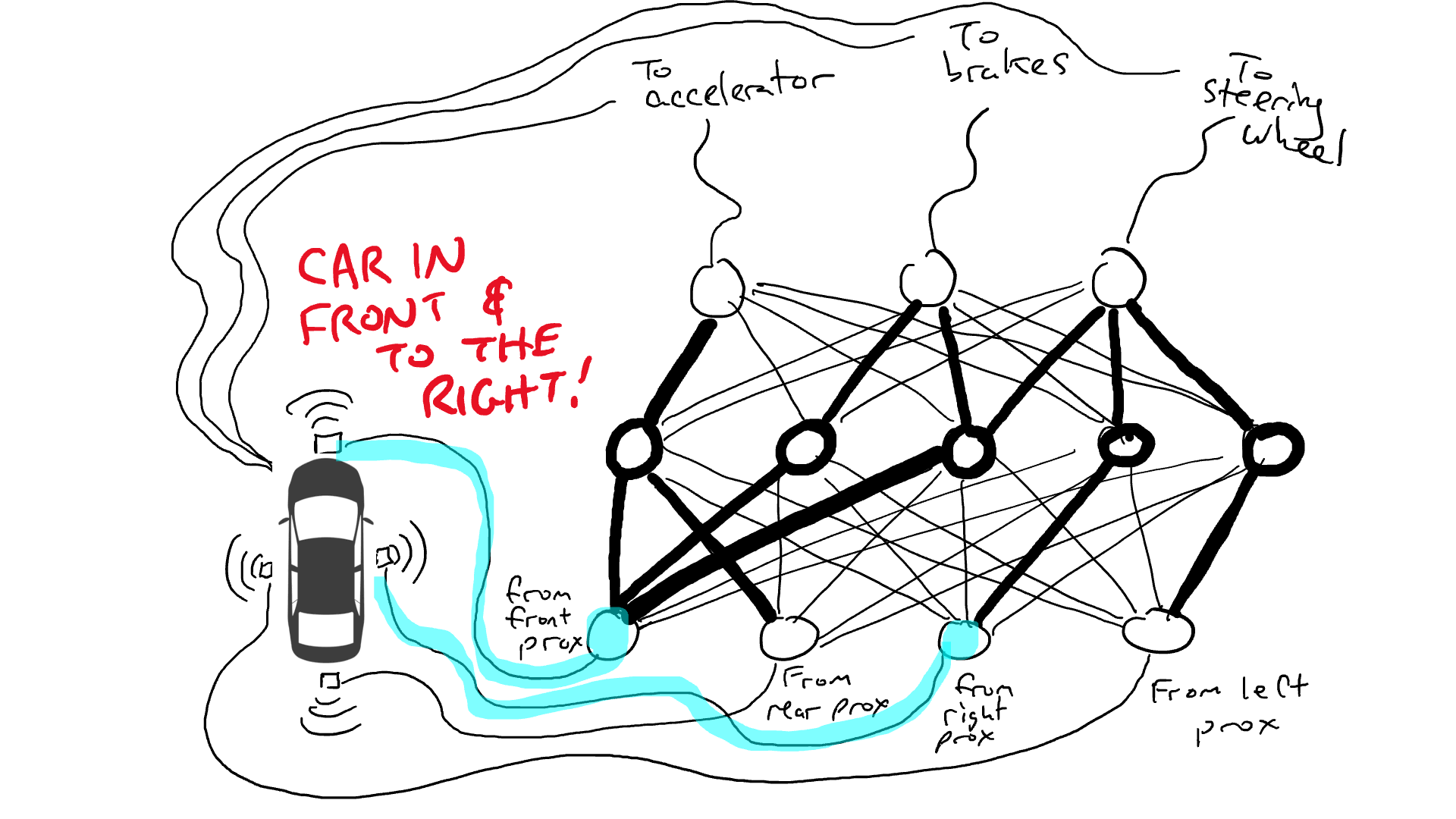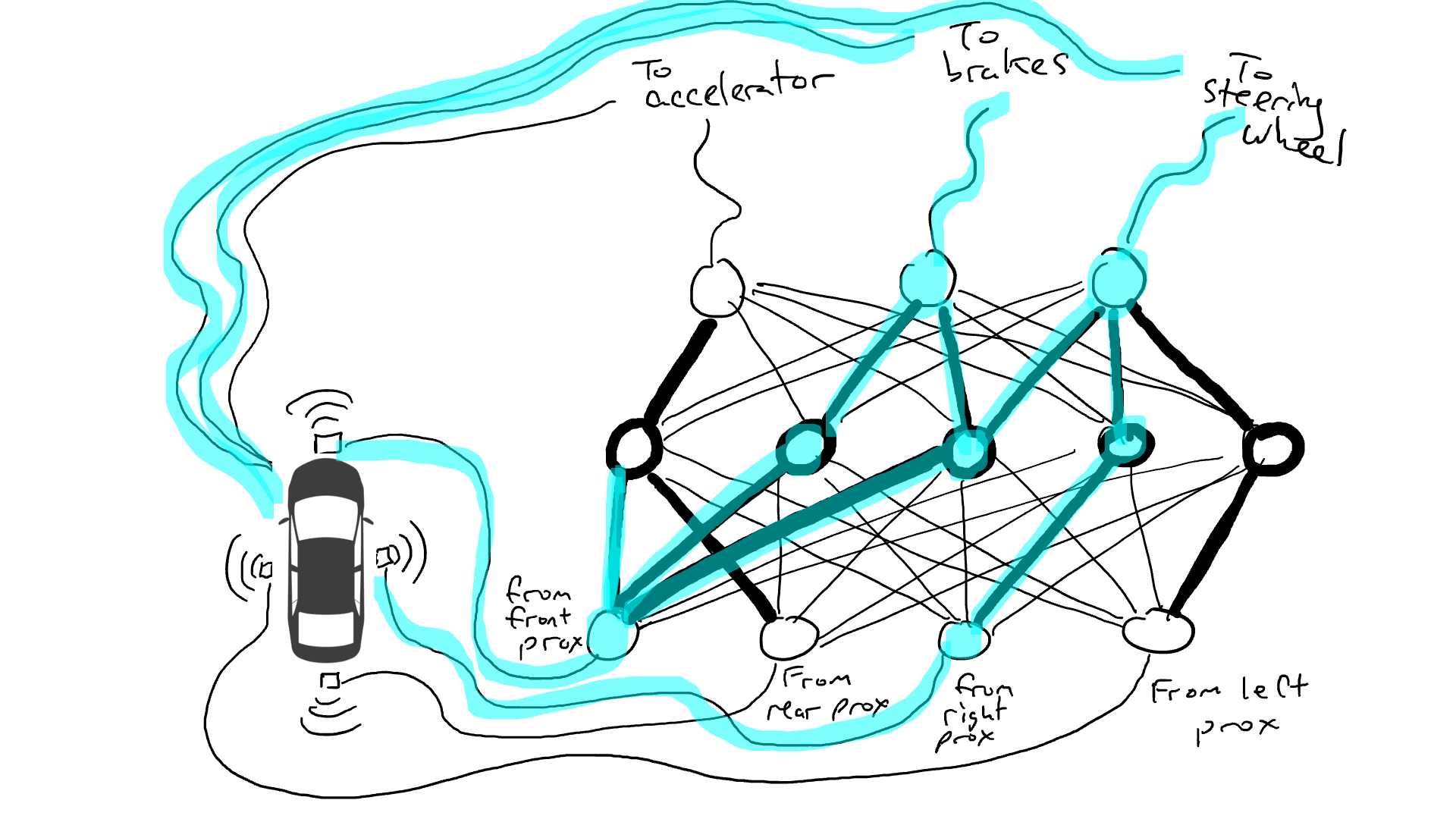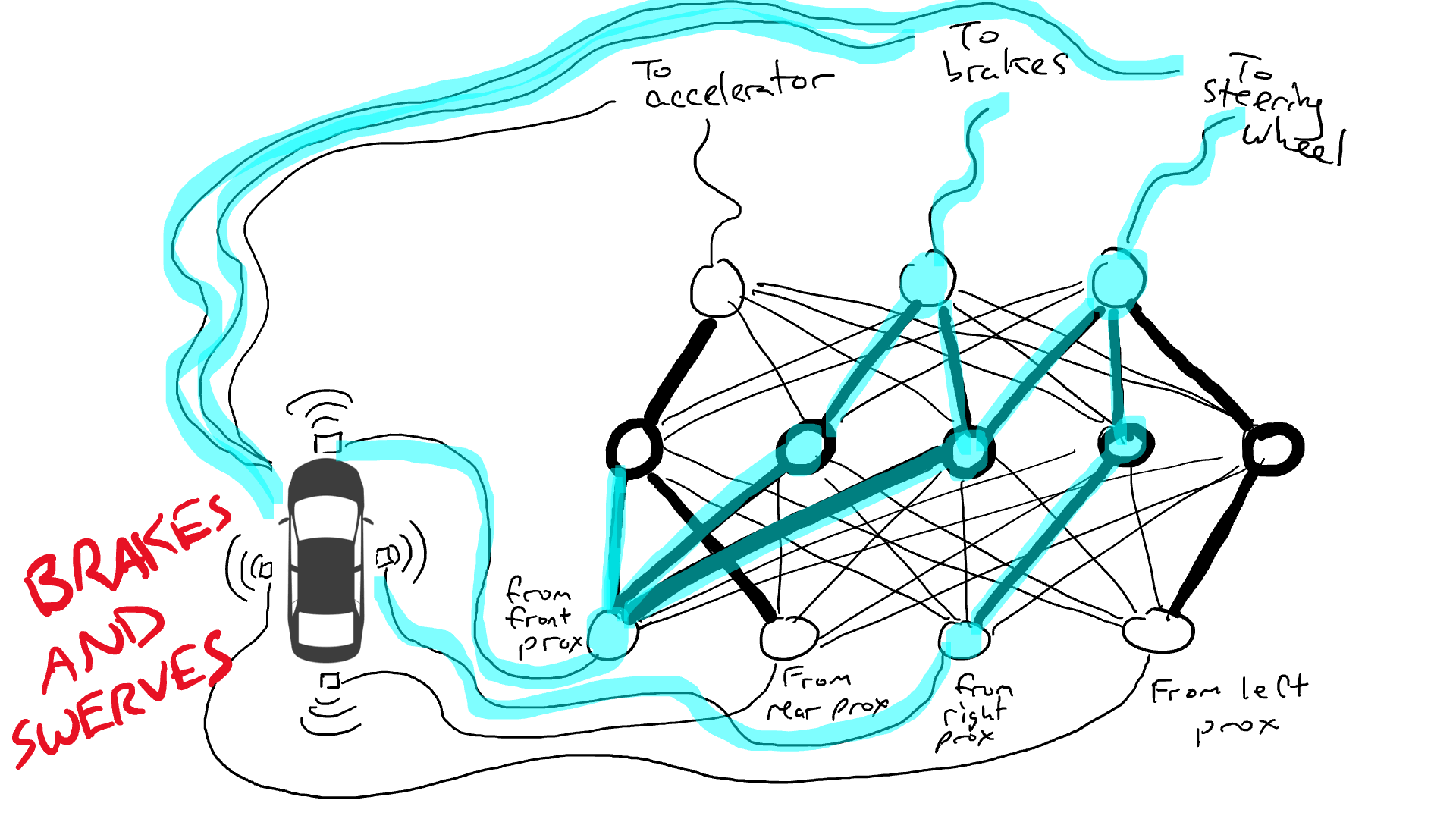
想象一下我们想要制作一辆可以在高速公路上行驶的自动驾驶汽车。我们在车的前、后和两侧装上了距离传感器。当有物体接近时,距离传感器会报告一个值为1的数值,而当附近没有可检测的物体时,传感器会报告一个值为0的数值。
我们还安装了机器人操作方向盘,踩刹车和加速。当油门接收到1的数值时,它使用最大的加速度,而0的数值意味着没有加速。同样,发送给制动机构的数值为1意味着紧急刹车,而0则意味着没有制动。转向机构接受-1到+1之间的数值,负数表示向左转,正数表示向右转,而0表示保持直线行驶。
当然我们必须记录驾驶的数据。当前方的道路清晰时,你会加速。当前方有汽车时,你会减速。当一辆汽车从左侧靠得太近时,你会向右转向并变换车道,当然,前提是右侧没有车。这个过程非常复杂,需要根据不同的传感器信息组合进行不同的操作(向左或向右转,加速或减速,制动),因此需要将每个传感器都连接到每个机器人机构上。

当你开车上路时会发生什么?电流从所有传感器流向所有机器人执行器,车辆同时向左转、向右转、加速和刹车。会形成一团乱麻。
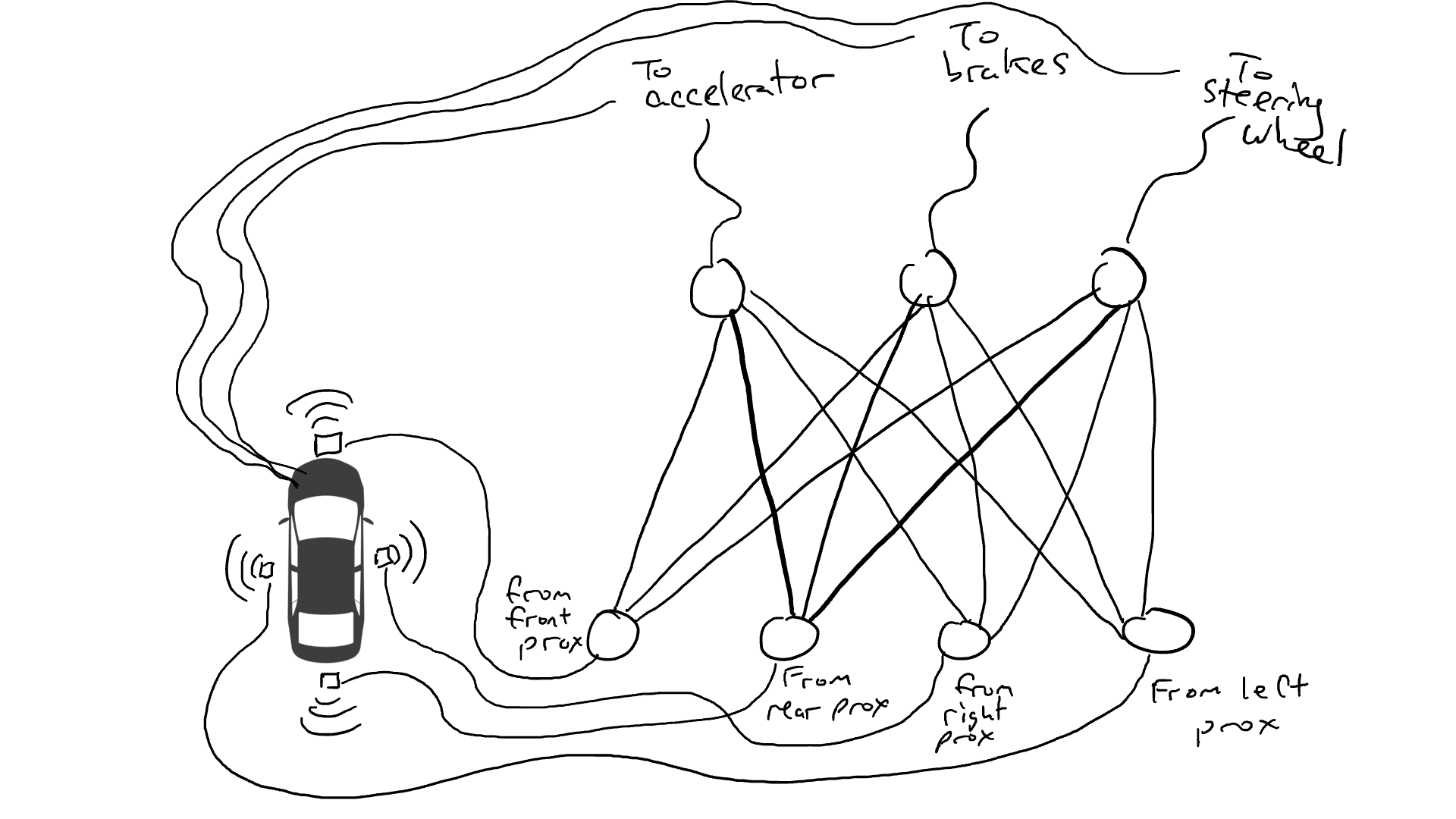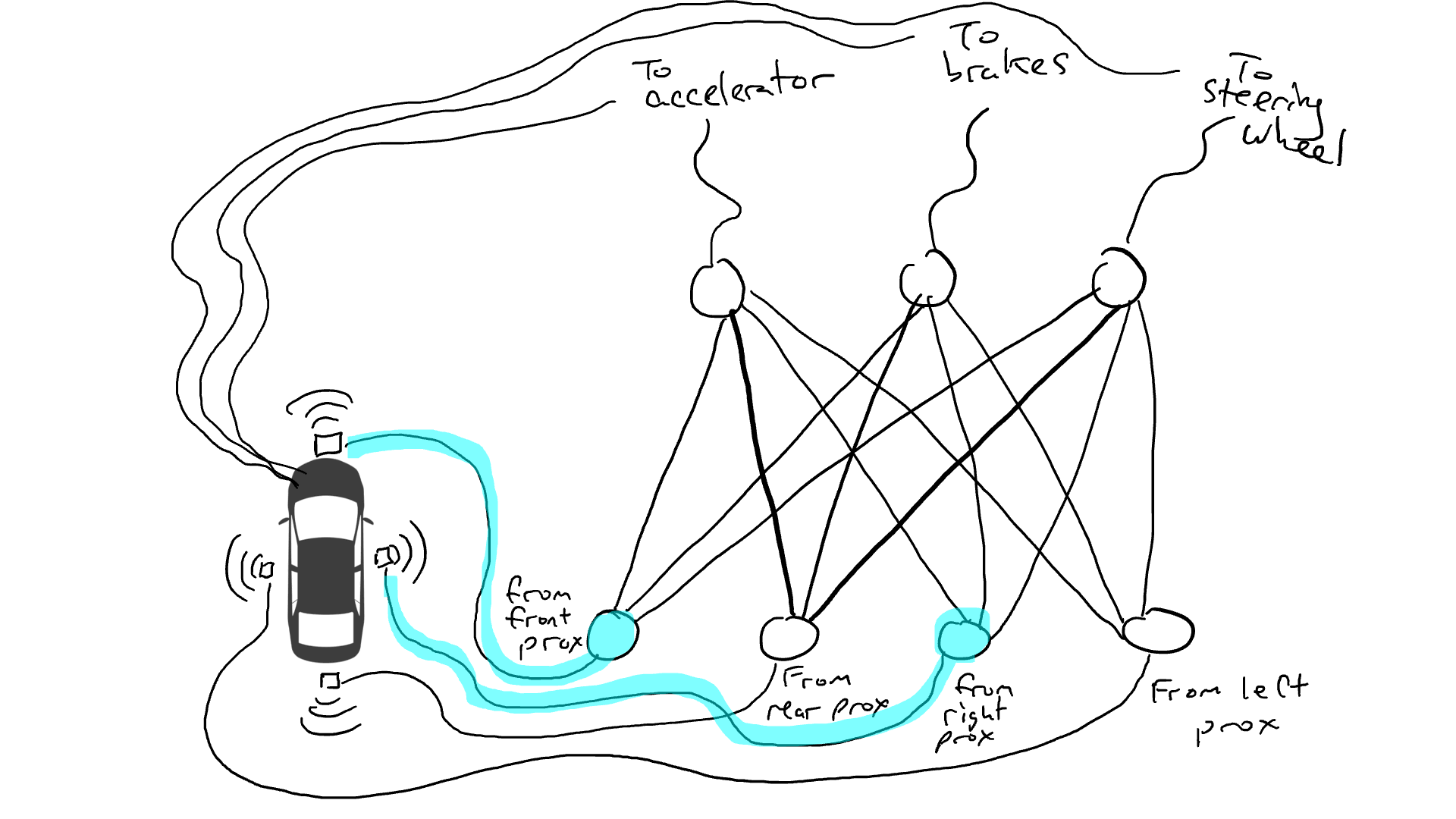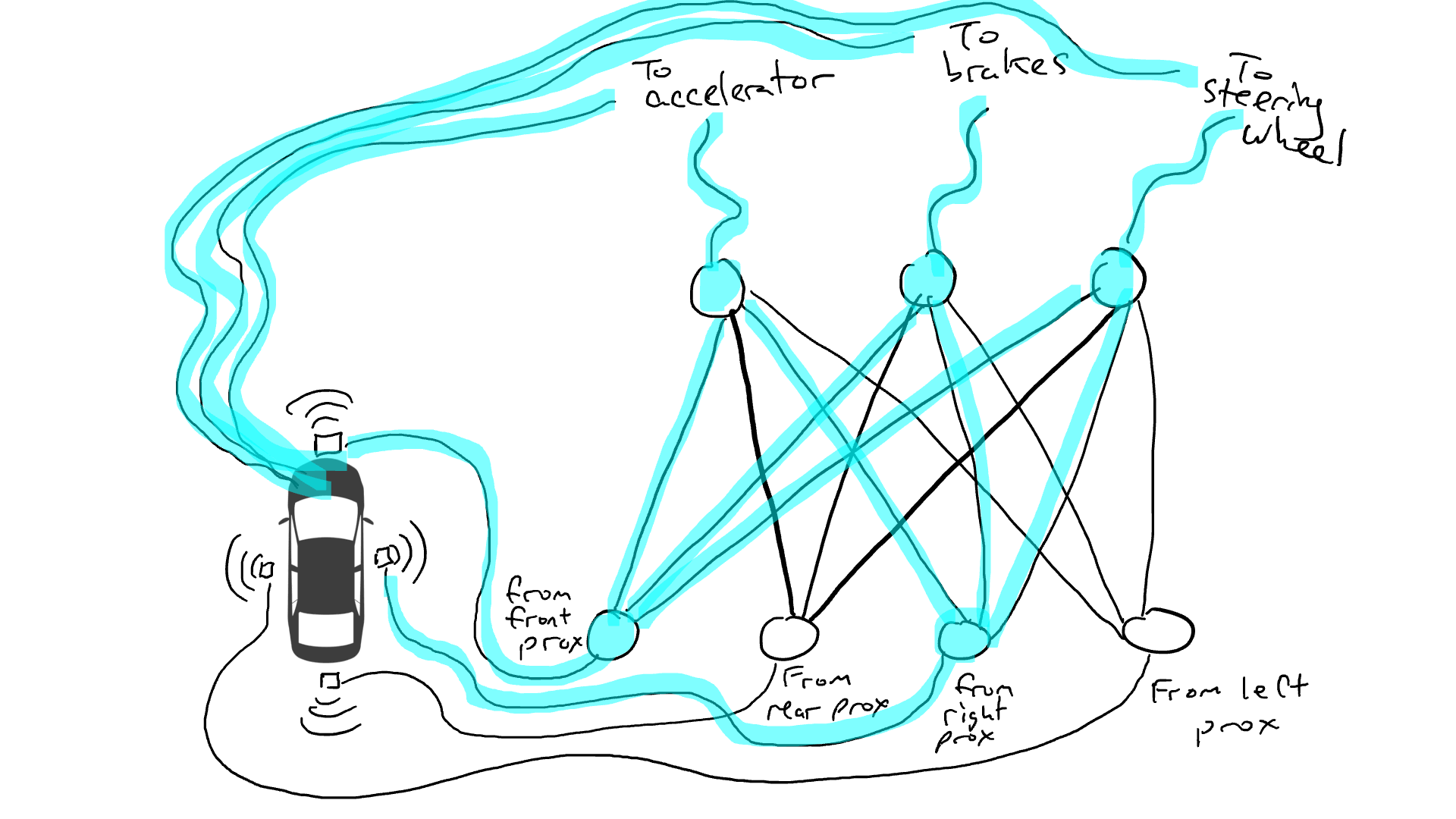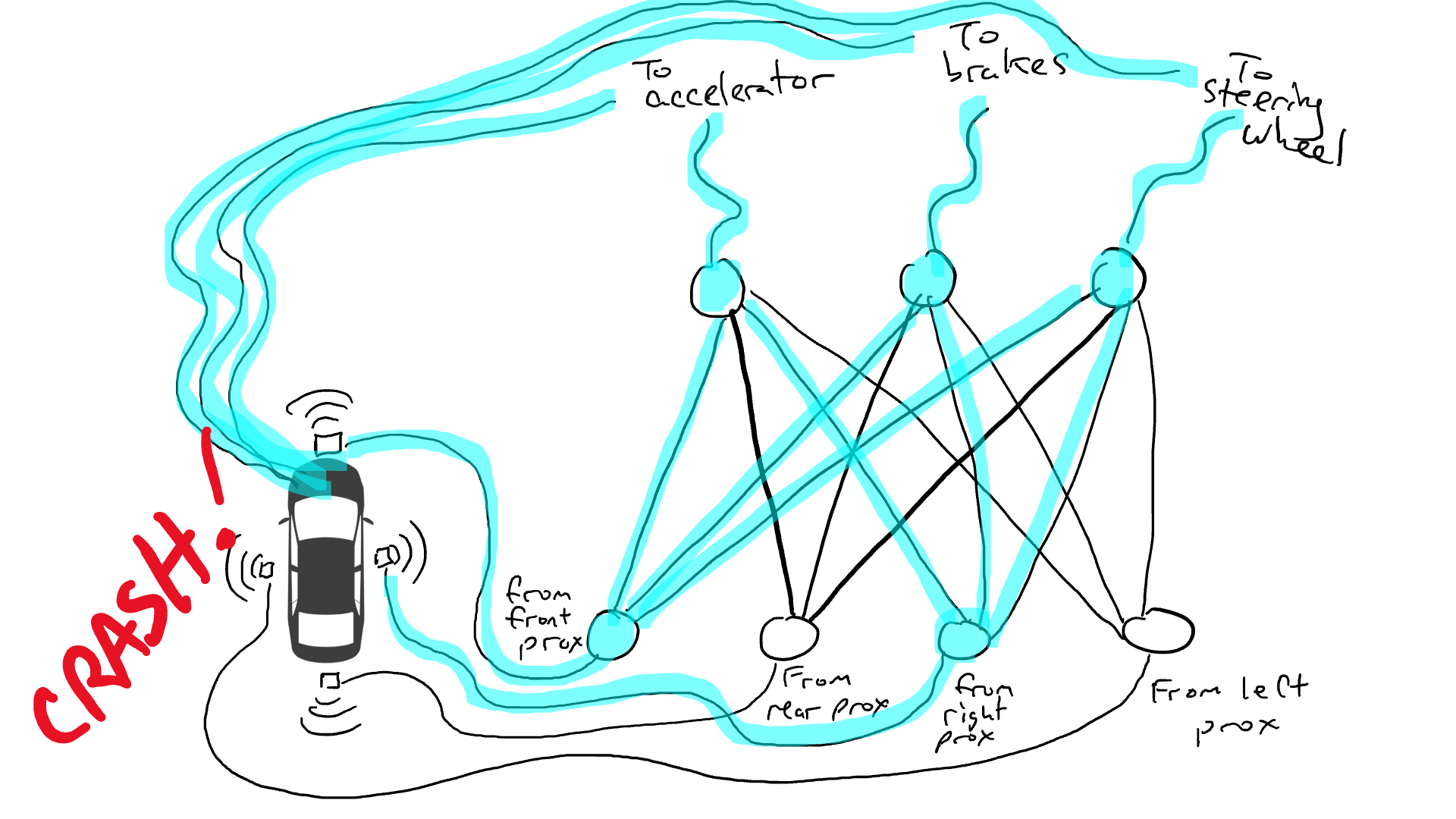
拿出电阻器并开始将它们放在电路的不同部分,以便电流可以在某些传感器和某些机械臂之间更自由地流动。例如,我们希望电流能够从前方接近传感器更自由地流向刹车而不是转向机构。我们还安装了称为门的元件,直到足够的电荷积累以触发开关之前,电流才会停止流动(只有在前方和后方的接近传感器都报告高数字时才允许电流流动),或者仅在输入电强度较低时向前发送电能(当前方接近传感器报告低值时向加速器发送更多电力)。
但是我们应该在哪里放置这些电阻器和门呢?我也不知道。随机地将它们放在各个位置。然后再试一次。也许这次汽车开得更好,这意味着它有时会在数据表明最好刹车和转向等时刹车和转向,但它并不是每次都正确。而有些事情它做得更糟糕(在数据表明有时需要刹车时它加速了)。因此,我们不断地随机尝试不同的电阻器和门的组合。最终,我们会偶然发现一个足够好的组合,那么我们宣布成功。比如下面这个组合:

(实际上,我们不会添加或删除门,但我们会修改门,使其可以以较低的能量从下方激活,或者需要更多的能量从下方输出,或者只有在下方有非常少的能量时才释放大量的能量。机器学习是纯粹主义者,可能会对这种描述感到不舒服。技术上,这是通过调整门上的偏置来完成的,这通常不会在此类图示中显示,但从电路隐喻的角度来看,它可以被认为是一个插入直接连到电源的线缆,可以像所有其他线缆一样进行修改。)
随意尝试并不好。一个名为反向传播的算法在改变电路配置方面具有相当不错的猜测能力。算法的细节并不重要,只需知道它会微调调整电路以使其行为更接近于数据所建议的行为,经过成千上万次的微调,最终可以得到与数据相符的结果。
我们称电阻器和门为参数,因为实际上它们无处不在,而反向传播算法所做的是宣布每个电阻器更强或更弱。因此,如果我们知道电路的布局和参数值,整个电路可以在其他汽车上复制。
敬请观看《一种轻松且客观介绍大模型方式,避免过度解读》第二篇




