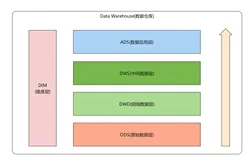
一、数据仓库的分层架构
数据仓库的数据来源于不同的源数据,并提供多样的数据应用,数据自下而上流入数据仓库后向上层开放应用,而数据仓库只是中间集成化数据管理的一个平台。
1,源数据层(ODS)
操作性数据(Operational Data Store) ,是作为数据库到数据仓库的一种过渡,ODS的数据结构一般与数据来源保持一致,可以增加字段用来进行数据管理,存储的历史数据只是只读的,提供业务系统查询使用, 而且ODS的数据周期一般比较短。ODS的数据为后一步的数据处理做准备。
2,数据仓库层(DW)
数据仓库(Data Warehouse),是数据的归宿,这里保持这所有的从ODS到来的数据,并长期保存,而且这些数据不会被修改,DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。
3,数据应用层(DA 或 APP)
数据应用(Data Application),为了特定的应用目的或应用范围,而从数据仓库中独立出来的一部分数据,也可称为部门数据或主题数据,该数据面向应用。如根据报表、专题分析需求而计算生成的数据。
(1)明细层DWD(Data Warehouse Detail)
存储明细数据,此数据是最细粒度的事实数据。该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。
(2)中间层DWM(Data WareHouse Middle)
存储中间数据,为数据统计需要创建的中间表数据,此数据一般是对多个维度的聚合数据,此层数据通常来源于DWD层的数据。
(3)业务层DWS(Data WareHouse Service)
存储宽表数据,此层数据是针对某个业务领域的聚合数据,业务层的数据通常来源与此层,为什么叫宽表,主要是为了业务层的需要在这一层将业务相关的所有数据统一汇集起来进行存储,方便业务层获取。此层数据通常来源与DWD和DWM层的数据。
4,维表层(Dimension)
维表层主要包含两部分数据:
(1)高基数维度数据:
一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
(2)低基数维度数据:
一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万。
二、数据库与数据仓库的主要区别
数据仓库是指从业务数据中创建信息数据库,并针对决策和分析进行优化。数据库是数据管理的有效技术,是由一批数据构成的有序集合,这些数据被存放在结构化的数据表里。数据表之间相互关联,反映客观事物间的本质联系。数据库能有效地帮助一个组织或企业科学地管理各类信息资源。
1、数据库是面向事务的设计,数据仓库是面向主题设计的。
2、数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
3、数据库设计是尽量避免冗余,数据仓库在设计是有意引入冗余,一般采用符合范式的规则来设计。针对某一业务应用进行设计,符合业务应用,但是不符合分析。数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计,采用反范式的方式来设计。
4、数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
三、数据仓库的系统设计流程
1、确定分析所依赖的源数据。
2、通过ETL将源数据采集到数据仓库。
3、数据按照数据仓库提供的主体结构进行存储。
4、根据各部门的业务分析要求创建数据集市(数据仓库的子集)。
5、决策分析、报表等应用系统从数据仓库查询数据、分析数据。
6、用户通过应用系统查询分析结果、报表。
四、OLAP和OLTP的区别
OLAP:(Online transaction processing):在线/联机事务处理。典型的OLTP类操作都比较简单,主要是对数据库中的数据进行增删改查,操作主体一般是产品的用户。
OLTP:(Online analytical processing):指联机分析处理。通过分析数据库中的数据来得出一些结论性的东西。比如给老总们看的报表,用于进行市场开拓的用户行为统计,不同维度的汇总分析结果等等。操作主体一般是运营、销售和市场等团队人员。

五、OLAP和OLTP统一使用
有个趋势是将OLTP和OLAP相融合,在同一个系统中同时提供TP和AP 2种服务,即HTAP产品,国内的数据库创业公司PingCAP的TiDB即是其中的佼佼者。
但由于两者服务类型相差甚大,完全融合是很难的,如何解决AP业务对要求更高实时性和稳定性的TP业务带来影响,如何同时提供2种服务且2种服务与业界其他系统相比具备足够竞争力,这些都是很大的挑战。
在目前的HTAP系统中,一般通过存储层的数据多副本来进行针对AP和TP业务的不同方式的优化,使用多个副本来以行存方式更好满足TP业务,通过增加一个副本来以列存方式为AP业务提供服务。
在存储系统上,配置独立的计算/查询系统,分别满足TP和AP不同的要求。比如TP系统很重要的一个特点就是事务的ACID,而AP系统更加关心分布式并行查询能力。
六、总结
传统的数据仓库集成处理架构是ETL,利用ETL平台的能力,E=从源数据库抽取数据,L=将数据清洗(不符合规则的数据)、转化(对表按照业务需求进行不同维度、不同颗粒度、不同业务规则计算进行统计),T=将加工好的表以增量、全量、不同时间加载到数据仓库。
数据仓库系统的作用能实现跨业务条线、跨系统的数据整合,为管理分析和业务决策提供统一的数据支持。数据仓库能够从根本上帮助你把公司的运营数据转化成为高价值的可以获取的信息(或知识),并且在恰当的时候通过恰当的方式把恰当的信息传递给恰当的人。
数据库和数据仓库的关系是依赖互补的,一般以数据仓库作为基础,既从数据仓库中抽取出详细数据的一个子集并经过必要的聚集存储到OLAP存储中供数据分析工具读取。