2.4 张量
学习目标:
- 知道常见的TensorFlow创建张量
- 知道常见的张量数学运算操作
- 说明numpy的数组与张量相同性
- 说明张量的两种形状改变特点
- 应用set_shape和tf.reshape山西爱你张量形状的修改
- 应用tf.matmul实现张量的矩阵运算修改
- 应用tf.cast实现张量的类型
2.4.1 张量(Tensor)
TensorFlow的张量就是一个N维数组,类型为tf.Tensor。
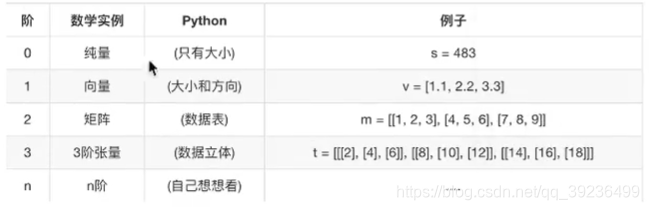
张量:在计算机当中如何存储?N维数组
标量:一个数字----0阶张量
向量:一维数组-----1阶张量
矩阵:二维数组------2阶张量
- type:数据类型
- shape:形状(阶)
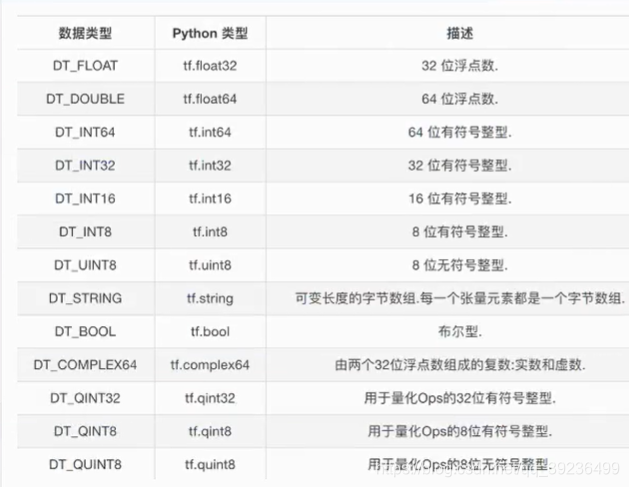
1 张量的类型
2 张量的阶
未指定类型时,默认类型:
- 整型:tf.int32
- 浮点型:tf.float32
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 去警告 def tensor_demo(): """ 张量的演示 :return: """ tensor1 = tf.constant(4.0) tensor2 = tf.constant([1,2,3,4]) # 未指定类型,默认类型 linear_squares = tf.constant([[4],[9],[16],[25]],dtype=tf.int32) print("tensor1:", tensor1) print("tensor2:", tensor2) print("linear_square:", linear_squares) return None if __name__ == "__main__": tensor_demo()
tensor1: Tensor("Const:0", shape=(), dtype=float32) tensor2: Tensor("Const_1:0", shape=(4,), dtype=int32) linear_square: Tensor("Const_2:0", shape=(4, 1), dtype=int32)
2.4.2 创建张量的指令
固定值张量
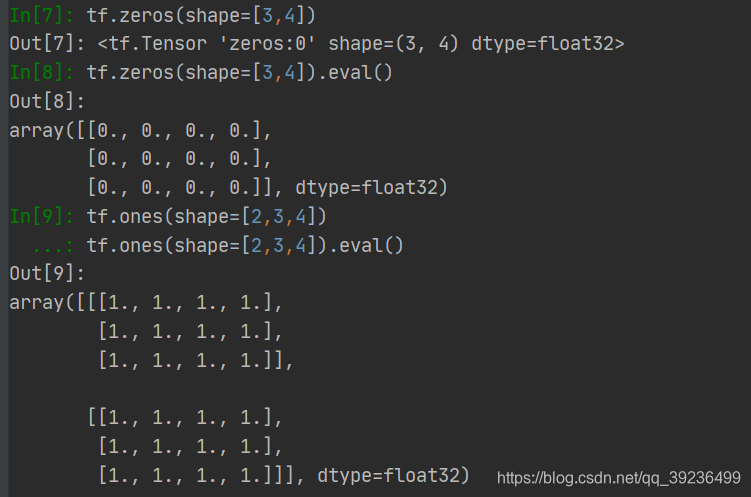
1 创建多个0
tf.zeros(shape, dtype=tf.float32, name=None)
2 创建多个1
tf.ones(shape, dtype=tf.float32, name=None)
3 创建常数张量
tf.constant(value, dtype=tf.float32, name='Const')
用.eval可以查看值
2.4.3 张量的变换
1 类型改变
- tf.string_to_number(string_tensor, out_type=None, name=None)
- tf.to_double(x, name=‘ToDouble’)
- tf.to_float(x, name=‘ToFloat’)
- tf.to_bfloat16(x, name=“ToBFloat16”)
- tf.to_int32(x, name=‘Tolnt32’)
- tf.to_int64(x, name=‘Tolnt64’)
- tf.cast(x, dtype, name=None),通用类型转换
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 去警告 def tensor_demo(): """ 张量的演示 :return: """ tensor1 = tf.constant(4.0) tensor2 = tf.constant([1,2,3,4]) # 未指定类型,默认类型 linear_squares = tf.constant([[4],[9],[16],[25]],dtype=tf.int32) print("tensor1:", tensor1) print("tensor2:", tensor2) print("linear_square:", linear_squares) print("----------------") # 张量类型的修改:不会改变原始的Tensor l_cast = tf.cast(linear_squares, dtype=tf.float32) print("linear_square_after:", linear_squares) print('l_cast:', l_cast) return None if __name__ == "__main__": tensor_demo()
tensor1: Tensor("Const:0", shape=(), dtype=float32) tensor2: Tensor("Const_1:0", shape=(4,), dtype=int32) linear_square: Tensor("Const_2:0", shape=(4, 1), dtype=int32) ---------------- linear_square_after: Tensor("Const_2:0", shape=(4, 1), dtype=int32) l_cast: Tensor("Cast:0", shape=(4, 1), dtype=float32)
2 形状改变
tensorflow的张量具有两种形状变换,动态形状和静态形状
- tf.reshape:改变动态形状
- tf.set_shape:改变静态形状
- 静态形状:初始创建张量时的形状
- 动态形状:
什么情况下可以改变静态形状:只有在形状还没有完全固定下来的情况下;转换形状的时候,只能一维到一维,二维到二维,而不能跨维度改变形状
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 去警告 def tensor_demo(): """ 张量的演示 :return: """ tensor1 = tf.constant(4.0) tensor2 = tf.constant([1,2,3,4]) # 未指定类型,默认类型 linear_squares = tf.constant([[4],[9],[16],[25]],dtype=tf.int32) print("tensor1:", tensor1) print("tensor2:", tensor2) print("linear_square:", linear_squares) print("----------------") # 张量类型的修改:不会改变原始的Tensor l_cast = tf.cast(linear_squares, dtype=tf.float32) print("linear_square_after:", linear_squares) print('l_cast:', l_cast) print('------------------') # 更新、改变静态形状 # 定义占位符 a_p = tf.placeholder(dtype=tf.float32, shape=[None, None]) # 形状没有完全固定下来的静态形状 b_p = tf.placeholder(dtype=tf.float32, shape=[None, 10]) c_p = tf.placeholder(dtype=tf.float32, shape=[3, 2]) print("a_p:", a_p) print("b_p:", b_p) print("c_p:", c_p) print("-----------------------") # 更新形状未确定的部分 a_p.set_shape([2,3]) b_p.set_shape([2,10]) print("a_p:", a_p) print("b_p:", b_p) print('-------------') # 动态形状修改 a_p_reshape = tf.reshape(a_p, shape=[2, 3, 1]) print("a_p:", a_p) print("a_p_reshape:", a_p_reshape) c_p_reshape = tf.reshape(c_p, shape=[2, 3, 1]) # 必须保持改变前后元素的数量一致 print("c_p:", c_p) print("c_p_reshape:", c_p_reshape) return None if __name__ == "__main__": tensor_demo()
tensor1: Tensor("Const:0", shape=(), dtype=float32) tensor2: Tensor("Const_1:0", shape=(4,), dtype=int32) linear_square: Tensor("Const_2:0", shape=(4, 1), dtype=int32) ---------------- linear_square_after: Tensor("Const_2:0", shape=(4, 1), dtype=int32) l_cast: Tensor("Cast:0", shape=(4, 1), dtype=float32) ------------------ a_p: Tensor("Placeholder:0", shape=(?, ?), dtype=float32) b_p: Tensor("Placeholder_1:0", shape=(?, 10), dtype=float32) c_p: Tensor("Placeholder_2:0", shape=(3, 2), dtype=float32) ----------------------- a_p: Tensor("Placeholder:0", shape=(2, 3), dtype=float32) b_p: Tensor("Placeholder_1:0", shape=(2, 10), dtype=float32) ------------- a_p: Tensor("Placeholder:0", shape=(2, 3), dtype=float32) a_p_reshape: Tensor("Reshape:0", shape=(2, 3, 1), dtype=float32) c_p: Tensor("Placeholder_2:0", shape=(3, 2), dtype=float32) c_p_reshape: Tensor("Reshape_1:0", shape=(2, 3, 1), dtype=float32)
2.4.4 张量的数学运算
- 算术运算符
- 基本数学函数
- 矩阵运算
- reduce操作
- 序列索引操作
2.5 变量OP
学习目标:
- 说明变量op的特殊作用
- 说明变量op的trainable参数的作用
- 应用global_variables_initializer实现变量op的初始化
变量的特点:
- 存储持久化
- 可修改值
- 可指定被训练
2.5.1 创建变量
tf.Variable(initia_value=None, trainable=True, collections=None, name=None)
- initial_value:初始化的值
- trainable:是否被训练
- collections:新变量将添加到列出的图的集合中collections,默认为[GraphKeys.GLOBAL_VARIABLES],如果trainable是True变量也被添加到图形集合GraphKeys.TRAINABLE_VARIABLES
变量需要显示初始化,才能运行值
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 去警告 def variable_demo(): """ 变量的演示 :return: """ # 创建变量 a = tf.Variable(initial_value=50) b = tf.Variable(initial_value=40) c = tf.add(a, b) print("a:", a) print("b", b) print("c", c) print('----------------------') # 初始化变量 init = tf.global_variables_initializer() # 开启会话 with tf.Session() as sess: # 运行初始化 sess.run(init) a_value, b_value, c_value = sess.run([a,b,c]) print("a_value:", a_value) print("b_value", b_value) print("c_value", c_value) return None if __name__ == "__main__": variable_demo()
a: <tf.Variable 'Variable:0' shape=() dtype=int32_ref> b <tf.Variable 'Variable_1:0' shape=() dtype=int32_ref> c Tensor("Add:0", shape=(), dtype=int32) ---------------------- a_value: 50 b_value 40 c_value 90
2.5.2 使用tf.variable_scope()修改变量的命名空间
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 去警告 def variable_demo(): """ 变量的演示 :return: """ # 创建变量 with tf.variable_scope("my_scope"): a = tf.Variable(initial_value=50) b = tf.Variable(initial_value=40) with tf.variable_scope("your_scope"): c = tf.add(a, b) print("a:", a) print("b", b) print("c", c) print('----------------------') # 初始化变量 init = tf.global_variables_initializer() # 开启会话 with tf.Session() as sess: # 运行初始化 sess.run(init) a_value, b_value, c_value = sess.run([a,b,c]) print("a_value:", a_value) print("b_value", b_value) print("c_value", c_value) return None if __name__ == "__main__": variable_demo()
a: <tf.Variable 'my_scope/Variable:0' shape=() dtype=int32_ref> b <tf.Variable 'my_scope/Variable_1:0' shape=() dtype=int32_ref> c Tensor("your_scope/Add:0", shape=(), dtype=int32) ---------------------- a_value: 50 b_value 40 c_value 90
2.6 高级API
2.6.1 其他基础API
1 tf.app
这个模块相当于为TensorFlow进行的脚本提供一个main函数入口,可以定义脚本运行的flags
2 tf.image
TensorFlow的图像处理操作。主要是一些颜色变换、变形和图像的编码和解码
3 tf.gfile
这个模块提供了一组文件操作函数
4 tf.summary
用来生成TensorBoard可用的统计日志,目前Summary主要提供了4种类型:
audio、image、histogram、scalar
5 tf.python_io
用来读写TFRecords文件
6 tf.train
这个模块提供了一些训练器,与tf.nn结合起来,实现一些网络的优化计算
7 tf.nn
这个模块提供了一些构建神经网络的底层函数。TensorFlow构建网络的核心模块,其中包含了添加各种层的函数,比如添加卷积层、池化层等。
2.6.2 高级API
1 tf.keras
Kears本来是一个独立的深度学习库,tensorflow将其学习过来,增加这部分模块在于快速构建模型
2 tf.layers
高级API,以便高级的概念层来定义一个模型。类似tf.kears
3 tf.contrib
tf.contrib.layers提供够将计算图中的网络层、正则化、摘要操作,是构建计算图的高级操作,但是tf.contrib包含不稳定和实验代码,有可能以后API会改变
4 tf.estimator
一个estimator相当于model + training + evaluate 的合体。在模块中,已经实现了几种简单的分类器和回归其,包括:Baseline,learning 和 DNN。这里的DNN的网络,只是全连接网络,没有提供卷积之类的
2.7 案例:实现线性回归
学习目标:
- 应用op的name参数实现op的名字修改
- 应用variable_scope实现图程序作用域的添加
- 应用scalar或histogram实现张良志的跟踪显示
- 应用merge_all实现张量值的合并
- 应用add_summary实现张量值的写入文件
- 应用tf.train.saver实现TensorFlow的模型保存以及加载
- 应用tf.app.flags实现命令行参数添加和使用
- 应用reduce_mean、square实现均方误差计算
- 应用tf.train.GradientDescentOptimizer实现有梯度下降优化器创建
- 应用minimize函数优化损失
- 知道梯度爆炸以及常见解决技巧
2.7.2 案例:实现线性回归的训练
1)构建模型
2)构建损失函数:均方误差
3)优化损失:梯度下降
准备真实数据:
x:特征值,形状:(100,1)
y_true:目标值 (100,1)
y_true = 0.8x + 0.7 ,100个样本
假设满足: y =kx + b
流程分析:
(100,1) * (1,1) = (100,1) y_predict = x * weight(1,1) + bias(1,1) 1)构建模型 y_predict = tf.matmul(x, weights) + bias 2)构造损失函数 error = tf.reduce_mean(tf.square(y_predict - y_true)) 3)优化损失:梯度下降优化器 optimizer = tf.train.GrandientDescentOptimizer(learning_rate=0.01).minimize(error)
运算:
- 矩阵运算:tf.matmu(x,w)
- 平方:tf.square(error)
- 均方:tf.reduce_mean(error)
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 去警告 def linear_regression(): """ 实现线性回归 :return: """ # 1)准备数据 X = tf.random_normal(shape=[100, 1]) # 形状:100行1列 y_true = tf.matmul(X, [[0.8]]) + 0.7 # y_true = 0.8x + 0.7 # 2)构造模型 # 定义模型参数,用变量 weights = tf.Variable(initial_value=tf.random_normal(shape=[1, 1])) bias = tf.Variable(initial_value=tf.random_normal(shape=[1, 1])) y_predict = tf.matmul(X, weights) + bias # 3)构造损失函数 error = tf.reduce_mean(tf.square(y_predict - y_true)) # 4)优化损失 optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) # 显式地初始化变量 init = tf.global_variables_initializer() # 开启会话 with tf.Session() as sess: # 初始化变量 sess.run(init) # 查看初始化模型参数之后的值 print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval())) # 开始训练 for i in range(200): sess.run(optimizer) print("第%d训练后模型参数为:权重%f,偏置%f,损失为%f" % (i+1, weights.eval(), bias.eval(), error.eval())) return None if __name__ == "__main__": linear_regression()
... 第195训练后模型参数为:权重0.784588,偏置0.704202,损失为0.000298 第196训练后模型参数为:权重0.784881,偏置0.704130,损失为0.000259 第197训练后模型参数为:权重0.785245,偏置0.704024,损失为0.000256 第198训练后模型参数为:权重0.785542,偏置0.703911,损失为0.000219 第199训练后模型参数为:权重0.785778,偏置0.703855,损失为0.000218 第200训练后模型参数为:权重0.786084,偏置0.703762,损失为0.000211
5 学习率的设置、步数的设置与梯度爆炸
- 学习率越大,训练
2.7.3 增加其他功能
- 变量TensorBoard显示
- 增加命名空间
- 模型保存于加载
- 命令行参数设置
1 增加变量显示
目的:在TensorBoard当中观察模型的参数、损失值等变量值的变化

1)创建事件文件
2)收集变量
3)合并变量
4)每次迭代运行合并变量
5)每次迭代将summary事件写入事件文件
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 去警告 def linear_regression(): """ 实现线性回归 :return: """ # 1)准备数据 X = tf.random_normal(shape=[100, 1]) # 形状:100行1列 y_true = tf.matmul(X, [[0.8]]) + 0.7 # y_true = 0.8x + 0.7 # 2)构造模型 # 定义模型参数,用变量 weights = tf.Variable(initial_value=tf.random_normal(shape=[1, 1])) bias = tf.Variable(initial_value=tf.random_normal(shape=[1, 1])) y_predict = tf.matmul(X, weights) + bias # 3)构造损失函数 error = tf.reduce_mean(tf.square(y_predict - y_true)) # 4)优化损失 optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) # 2)收集变量 tf.summary.scalar("error", error) tf.summary.histogram("weights", weights) tf.summary.histogram("bias", bias) # 3)合并变量 merged = tf.summary.merge_all() # 显式地初始化变量 init = tf.global_variables_initializer() # 开启会话 with tf.Session() as sess: # 初始化变量 sess.run(init) # 1)创建事件文件 file_writer = tf.summary.FileWriter('logs', graph=sess.graph) # 查看初始化模型参数之后的值 print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval())) # 开始训练 for i in range(100): sess.run(optimizer) print("第%d训练后模型参数为:权重%f,偏置%f,损失为%f" % (i+1, weights.eval(), bias.eval(), error.eval())) # 运行合并变量操作 summary = sess.run(merged) # 每次迭代后的变量写入事件 file_writer.add_summary(summary, i) return None if __name__ == "__main__": linear_regression()
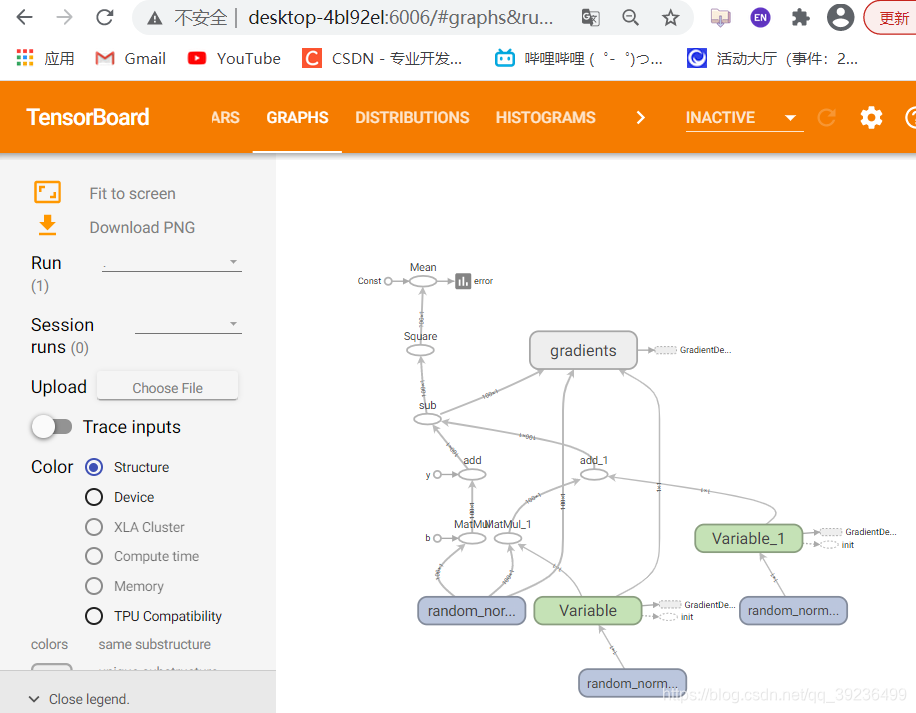
2 增加命名空间
使得代码结构更加信息,TensorBoard图结构更加清楚
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 去警告 def linear_regression(): """ 实现线性回归 :return: """ with tf.variable_scope("prepare_data"): # 1)准备数据 X = tf.random_normal(shape=[100, 1], name='feature') # 形状:100行1列 y_true = tf.matmul(X, [[0.8]]) + 0.7 # y_true = 0.8x + 0.7 with tf.variable_scope("create_model"): # 2)构造模型 # 定义模型参数,用变量 weights = tf.Variable(initial_value=tf.random_normal(shape=[1, 1]), name="Weights") bias = tf.Variable(initial_value=tf.random_normal(shape=[1, 1]), name="Bias") y_predict = tf.matmul(X, weights) + bias with tf.variable_scope("loss_function"): # 3)构造损失函数 error = tf.reduce_mean(tf.square(y_predict - y_true)) with tf.variable_scope("optimizer"): # 4)优化损失 optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) # 2)收集变量 tf.summary.scalar("error", error) tf.summary.histogram("weights", weights) tf.summary.histogram("bias", bias) # 3)合并变量 merged = tf.summary.merge_all() # 显式地初始化变量 init = tf.global_variables_initializer() # 开启会话 with tf.Session() as sess: # 初始化变量 sess.run(init) # 1)创建事件文件 file_writer = tf.summary.FileWriter('logs', graph=sess.graph) # 查看初始化模型参数之后的值 print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval())) # 开始训练 for i in range(100): sess.run(optimizer) print("第%d训练后模型参数为:权重%f,偏置%f,损失为%f" % (i+1, weights.eval(), bias.eval(), error.eval())) # 运行合并变量操作 summary = sess.run(merged) # 每次迭代后的变量写入事件 file_writer.add_summary(summary, i) return None if __name__ == "__main__": linear_regression()
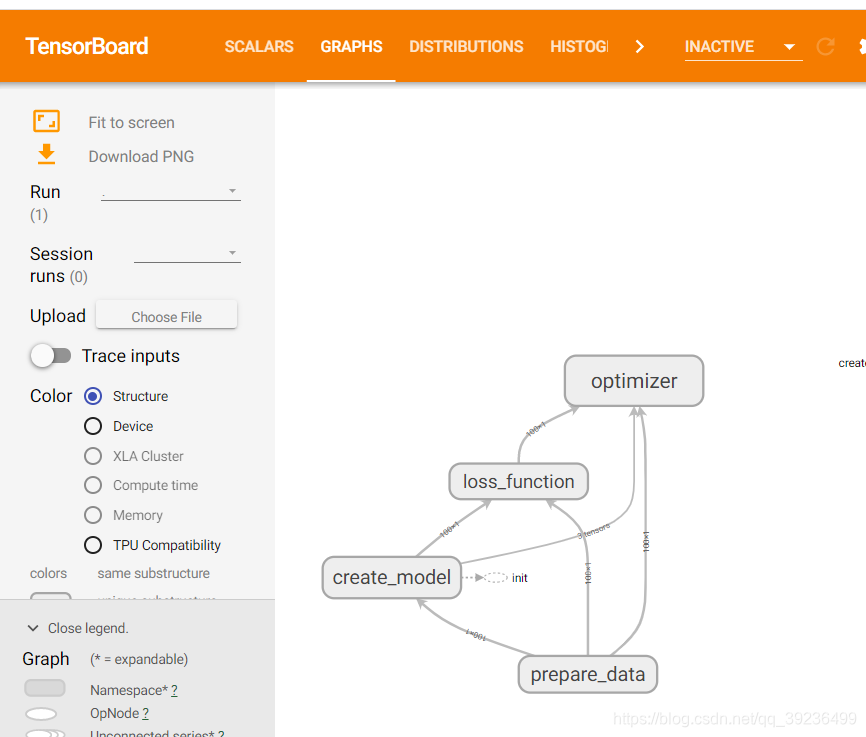
3 模型的保存与加载

步骤:
1)实例化Saver
2)保存:saver.save(sess, path)
3)加载:saver.restore(sess, path)
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 去警告 def linear_regression(): """ 实现线性回归 :return: """ with tf.variable_scope("prepare_data"): # 1)准备数据 X = tf.random_normal(shape=[100, 1], name='feature') # 形状:100行1列 y_true = tf.matmul(X, [[0.8]]) + 0.7 # y_true = 0.8x + 0.7 with tf.variable_scope("create_model"): # 2)构造模型 # 定义模型参数,用变量 weights = tf.Variable(initial_value=tf.random_normal(shape=[1, 1]), name="Weights") bias = tf.Variable(initial_value=tf.random_normal(shape=[1, 1]), name="Bias") y_predict = tf.matmul(X, weights) + bias with tf.variable_scope("loss_function"): # 3)构造损失函数 error = tf.reduce_mean(tf.square(y_predict - y_true)) with tf.variable_scope("optimizer"): # 4)优化损失 optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(error) # 2)收集变量 tf.summary.scalar("error", error) tf.summary.histogram("weights", weights) tf.summary.histogram("bias", bias) # 3)合并变量 merged = tf.summary.merge_all() # 创建Saver对象 saver = tf.train.Saver() # 显式地初始化变量 init = tf.global_variables_initializer() # 开启会话 with tf.Session() as sess: # 初始化变量 sess.run(init) # 1)创建事件文件 file_writer = tf.summary.FileWriter('logs', graph=sess.graph) # 查看初始化模型参数之后的值 print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval())) # # 开始训练 # for i in range(100): # sess.run(optimizer) # print("第%d训练后模型参数为:权重%f,偏置%f,损失为%f" % # (i+1, weights.eval(), bias.eval(), error.eval())) # # # 运行合并变量操作 # summary = sess.run(merged) # # 每次迭代后的变量写入事件 # file_writer.add_summary(summary, i) # # # 保存模型 # if i % 10 == 0: # saver.save(sess, "model/my_Linear.ckpt") # 加载模型 if os.path.exists("model/checkpoint"): saver.restore(sess, "model/my_Linear.ckpt") print("训练后模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval())) return None if __name__ == "__main__": linear_regression()
训练前模型参数为:权重-0.726173,偏置-1.391275,损失为6.139051 训练后模型参数为:权重0.800000,偏置0.700000,损失为0.000000
4 命令行参数设置

import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 去警告 # 1)定义命令行参数 tf.app.flags.DEFINE_integer("max_step", 100, "训练模型的步数") tf.app.flags.DEFINE_string("model_dir", "Unknown", "模型保存的路径+模型的名字") # 2)简化变量名 FLAGS = tf.app.flags.FLAGS def command_demo(): """ 命令行参数演示 :return: """ print("max_step:", FLAGS.max_step) print("model_dir:", FLAGS.model_dir) return None if __name__ == "__main__": command_demo()




import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 去警告 def main(argv): print(argv) print("code start") return None if __name__ == "__main__": tf.app.run() # 自动运行main函数 #command_demo()
['D:/programming_software/pycharm/PycharmProjects/deep_learning/day01_deeplearning.py'] code start
总结