
背景
日志服务采集到日志后,有时需要将日志投递至MaxCompute的表中进行存储与分析。本文主要向用户介绍将数据投递到MaxCompute完整流程,方便用户快速实现数据投递至MaxCompute。
投递流程
温馨提示:本文描述不做特殊说明,默认都是使用RAM账户登陆控制台。更多创建或获取RAM用户信息操作,请参见准备RAM用户。
一、创建角色
温馨提示:如果使用默认角色,可以跳过这一步。
1.登录RAM控制台。
2.在左侧导航栏,选择身份管理 > 角色。
3.在角色页面,单击创建角色。
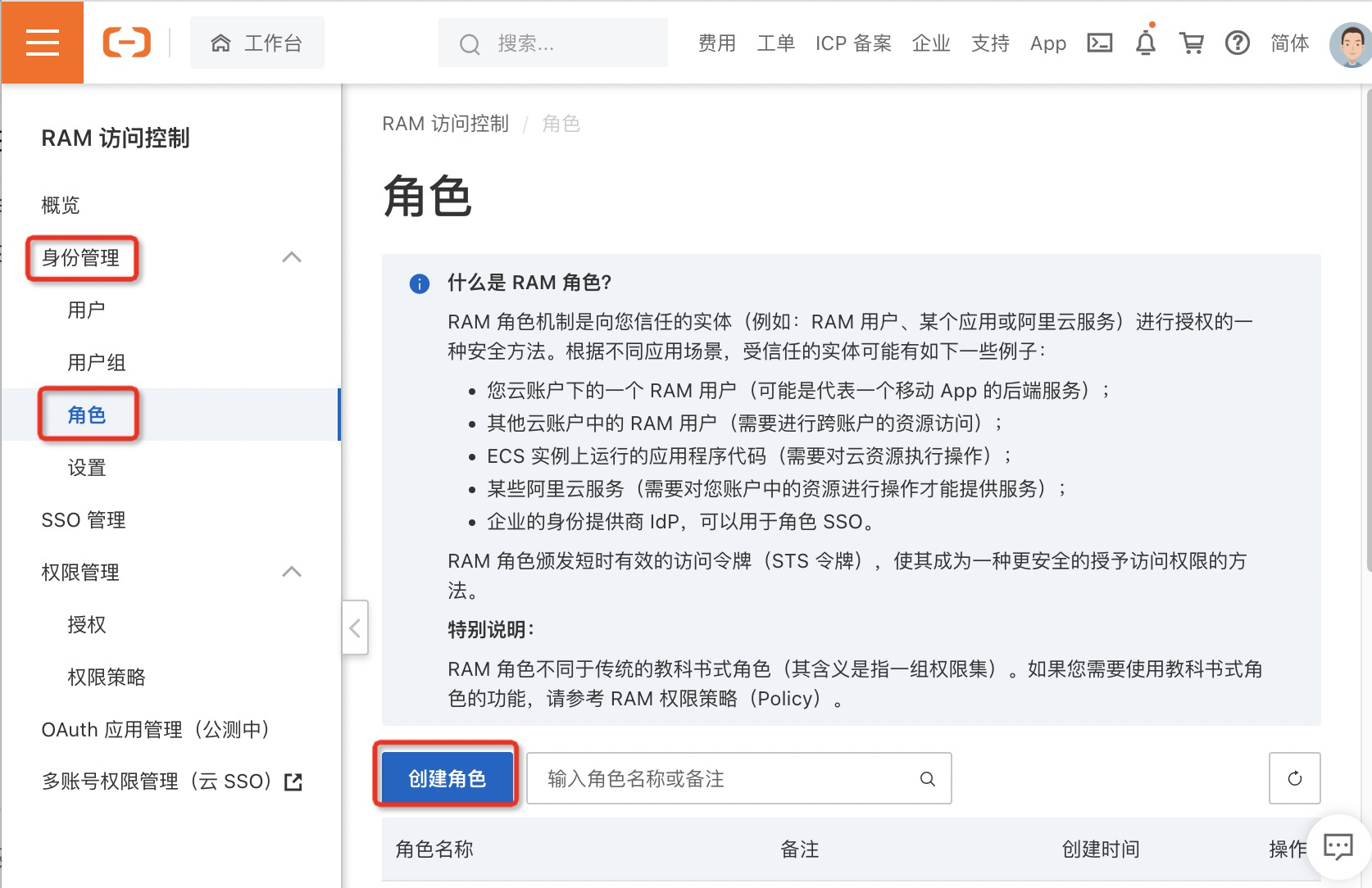
4.在创建角色面板,选择可信实体类型为阿里云服务,然后单击下一步。
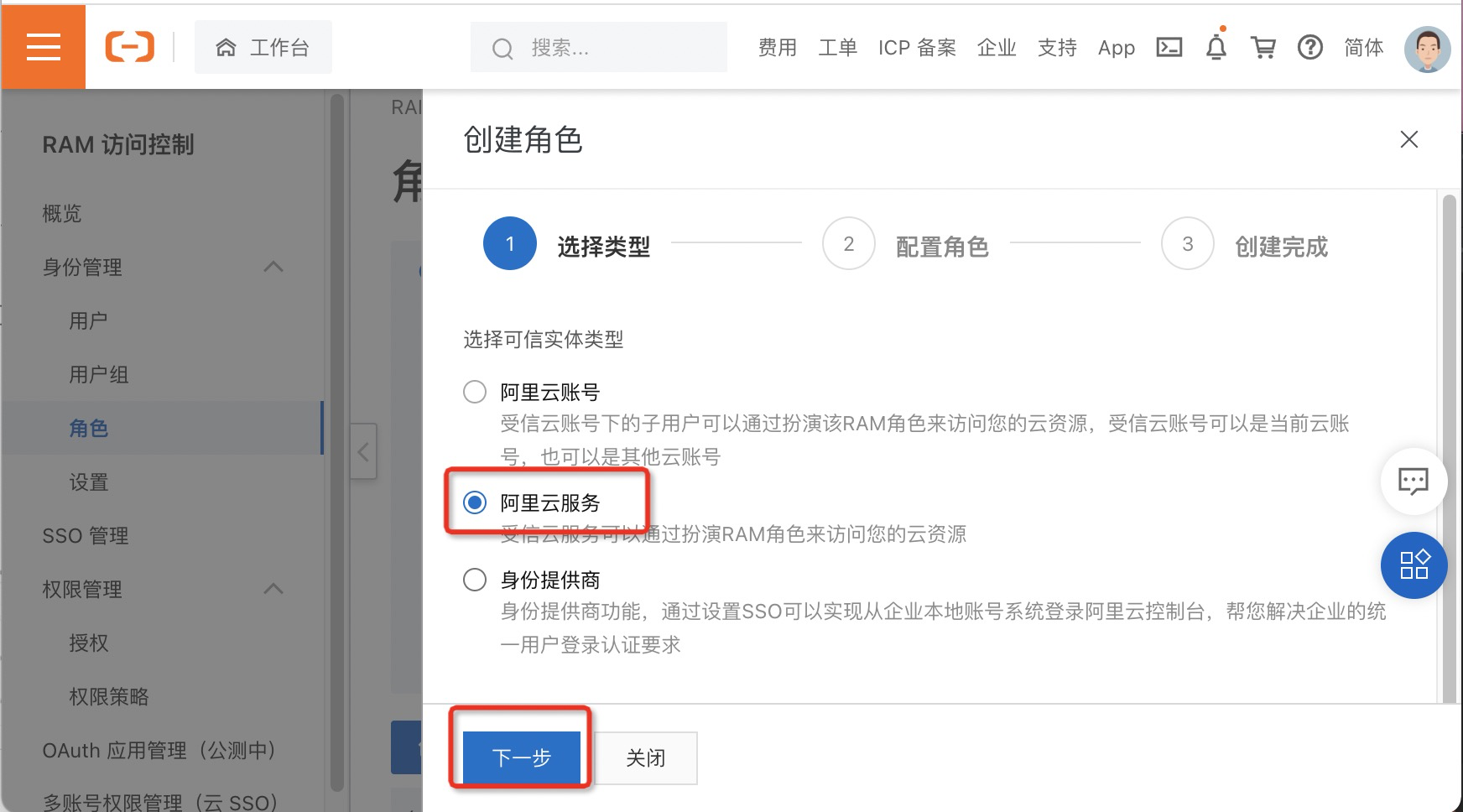
5.在配置角色配置向导中,配置如下内容,然后单击完成。
参数 |
说明 |
角色类型 |
选择普通角色类型。 |
角色名称 |
输入角色名称,例如aliyunlogreadrole。 |
备注 |
输入创建角色的备注信息。 |
选择受信服务 |
选择日志服务。 |
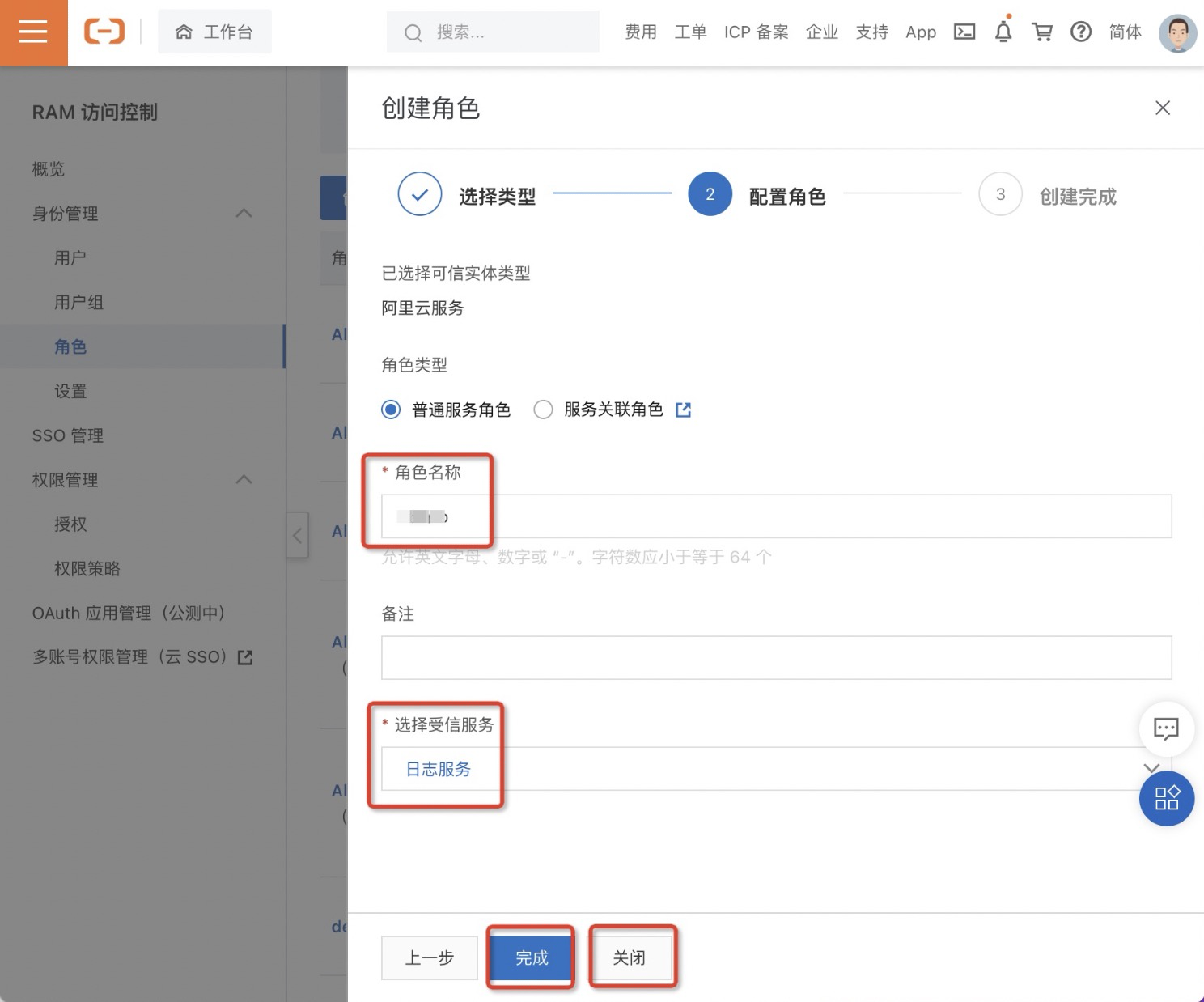
二、授予角色日志服务读权限
温馨提示:
- 如果使用默认角色AliyunLogDefaultRole,可以跳过这一步。
- 如果使用自定义创建RAM角色,该RAM角色此时无任何权限。您需要为该RAM角色授予系统策略或自定义策略,参考如下。
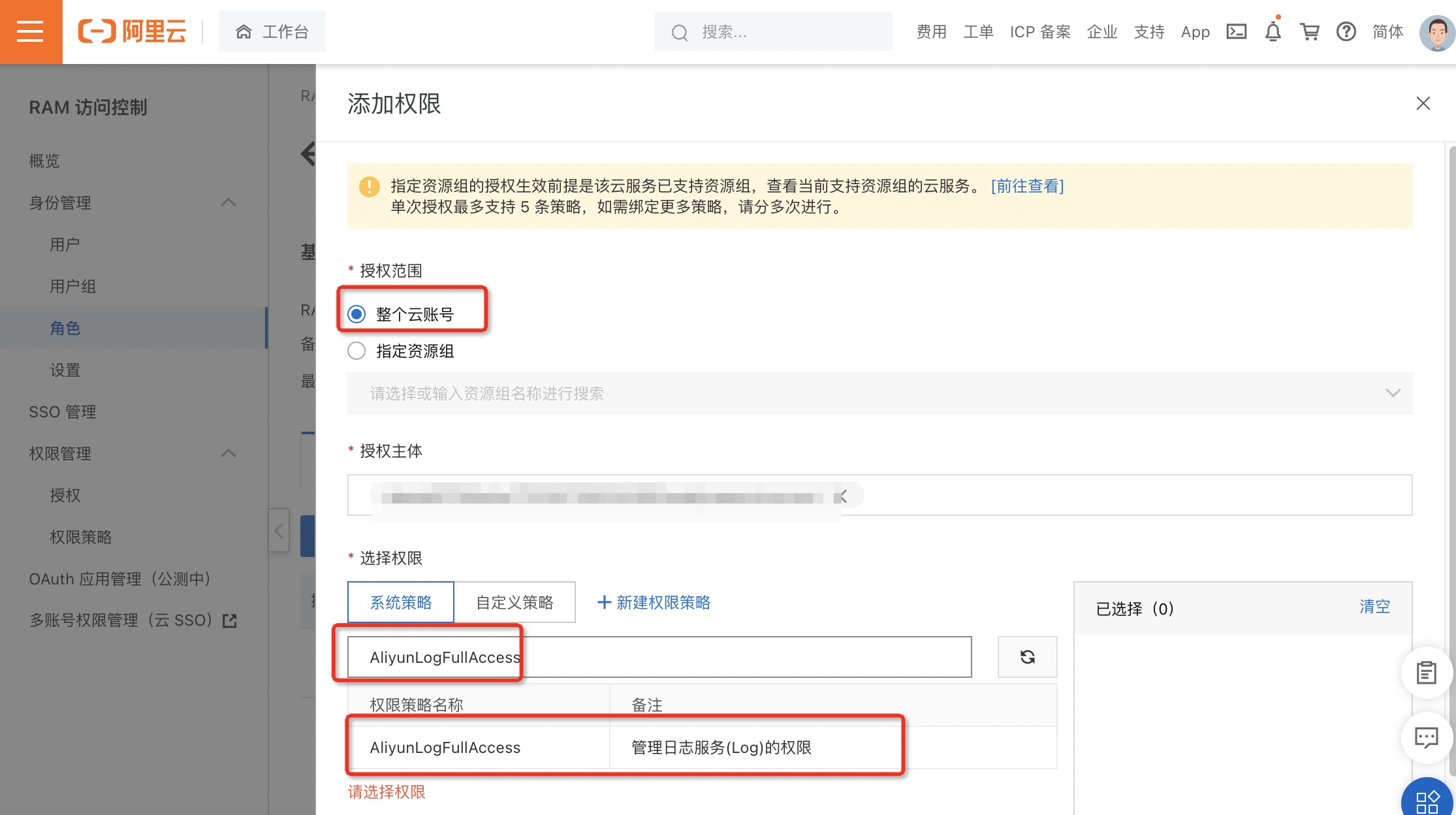
1.在角色页面,单击目标RAM角色操作列的添加权限。
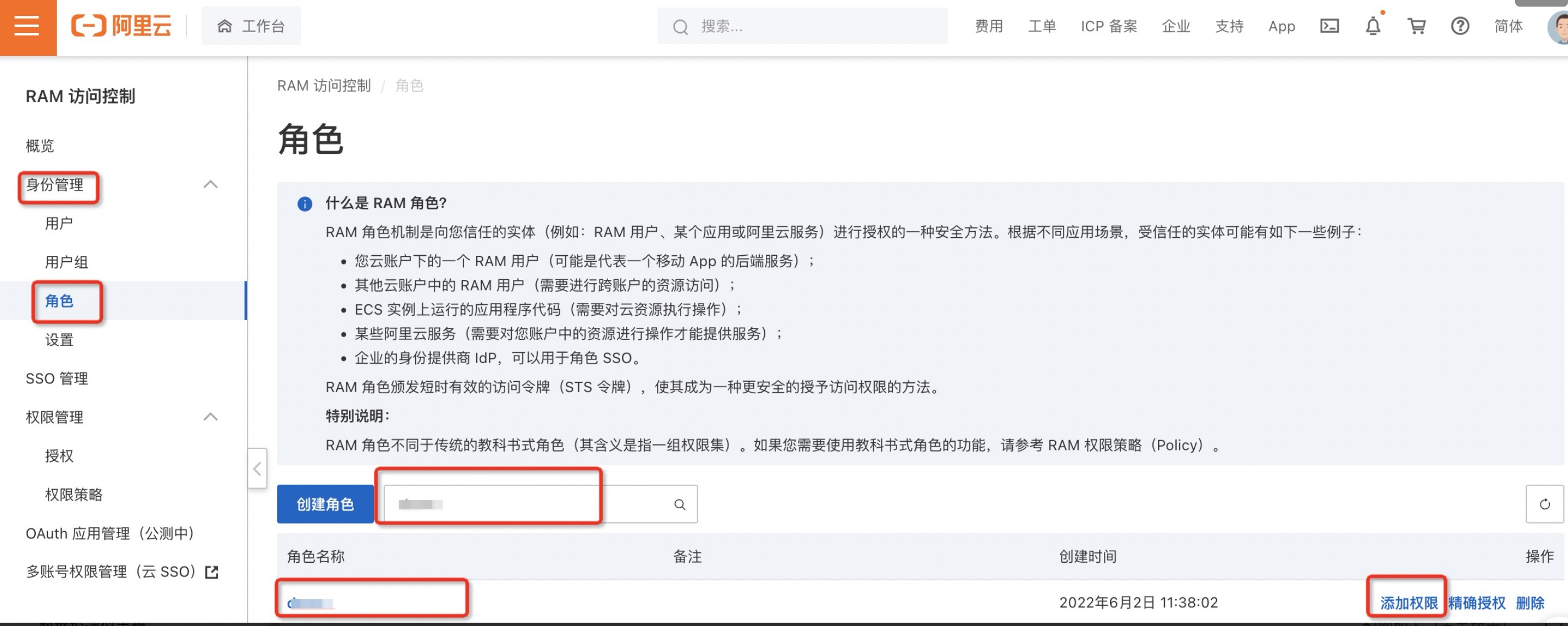
2.在添加权限页面,选中目标权限(如AliyunLogFullAccess)。
- 选择授权应用范围。
- 整个云账号:权限在当前阿里云账号内生效(推荐)。
- 指定资源组:权限在指定的资源组内生效。
- 输入授权主体。授权主体即需要授权的RAM角色名称,系统会自动填入当前的RAM角色。
- 选择AliyunLogFullAccess权限策略(AliyunLogFullAccess为管理日志服务的权限)。
3.确认授权结果,单击完成。
三、修改角色信任策略
说明:信任策略是来告知MaxCompute服务和sls服务可以信任该目标角色。
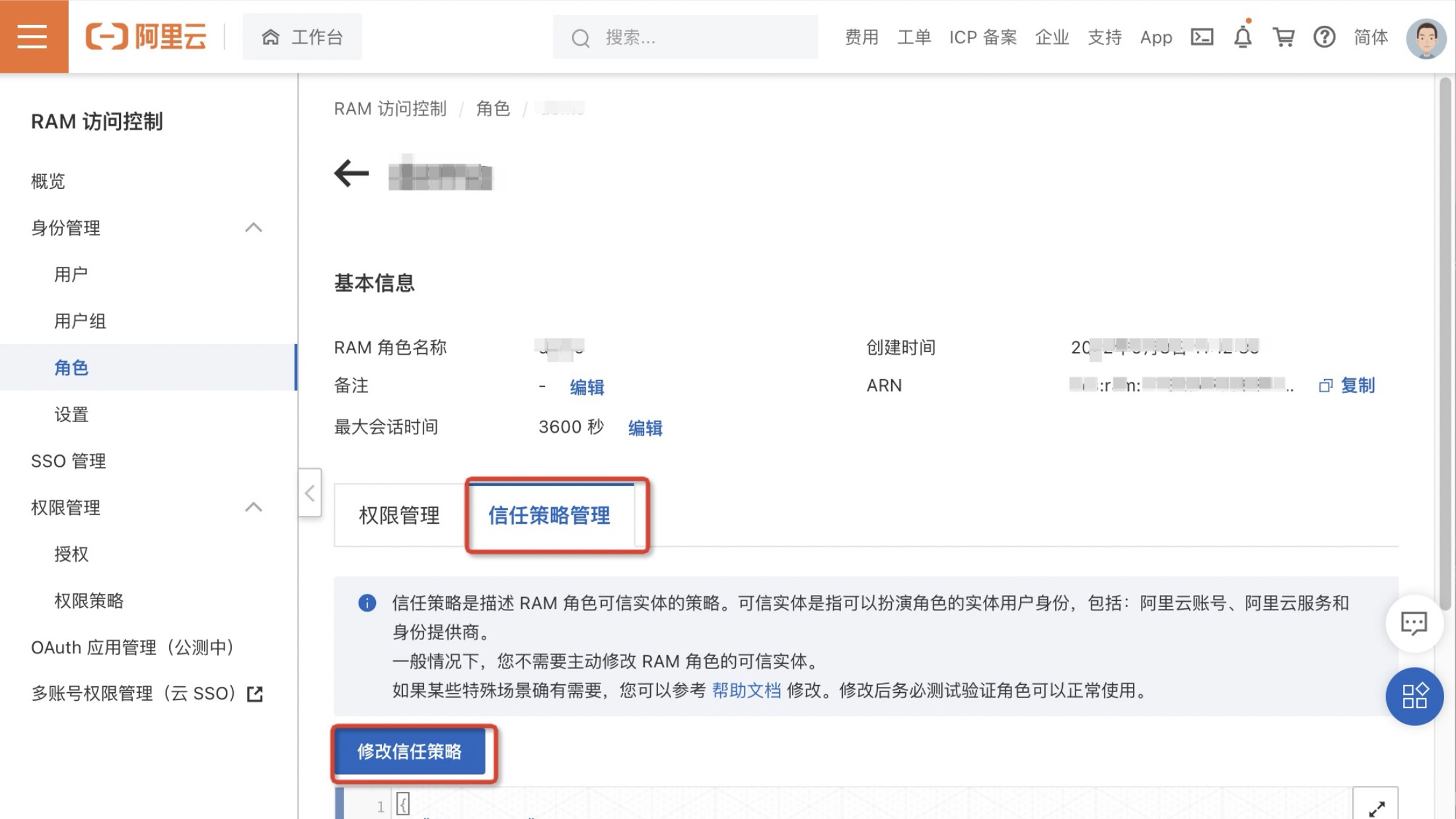
1.单击目标角色名称。
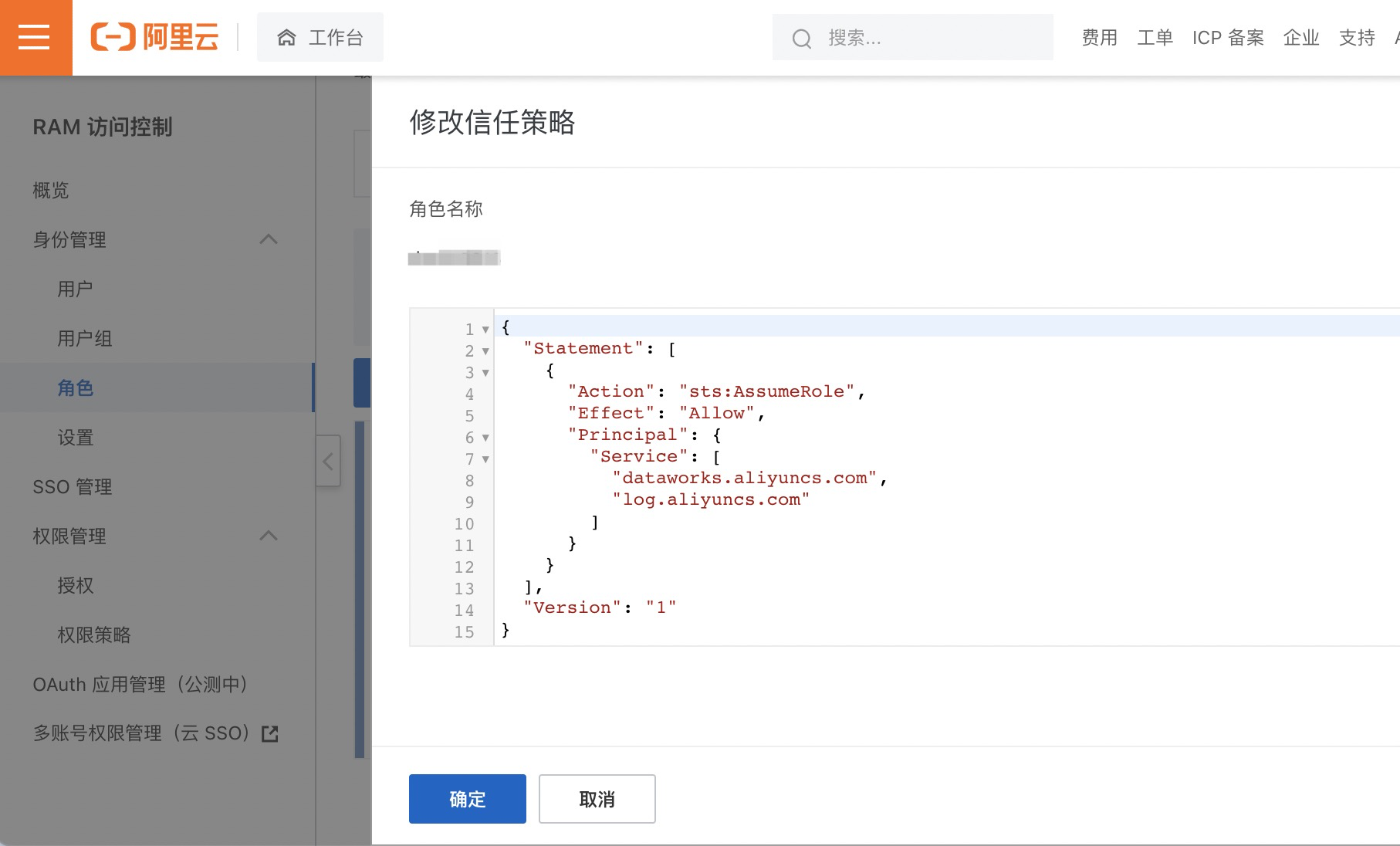
2.单击信任策略管理并修改其内容,添加"dataworks.aliyuncs.com"为授信服务如下。
{ "Statement": [ { "Action": "sts:AssumeRole", "Effect": "Allow", "Principal": { "Service": [ "log.aliyuncs.com", "dataworks.aliyuncs.com" ] } } ], "Version": "1"}
四、创建MaxCompute项目
温馨提示:如果已有MaxCompute项目,可以跳过这一步。
前提条件:
- 阿里云账号或RAM用户已开通DataWorks服务和MaxCompute服务,且位于同一地域。
- 如果您需要以RAM用户身份创建MaxCompute项目,请确认已获取RAM用户账号并已授予AliyunDataWorksFullAccess权限。更多创建或获取RAM用户信息操作,请参见准备RAM用户。
1.使用RAM账户登录DataWorks控制台。
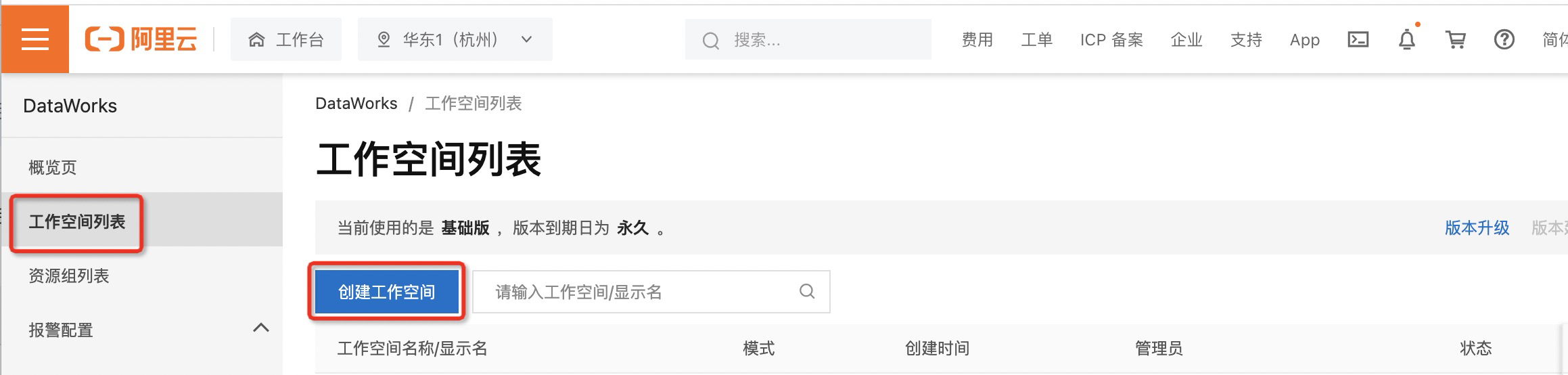
2.创建工作空间,创建工作空间完成后也会一并创建好MaxCompute项目
- 在左侧导航栏,单击工作空间列表,并切换至相应的地域后,单击创建工作空间。
- 在创建工作空间对话框,配置各项参数,单击下一步。更多参数信息请参见创建工作空间中第3步。
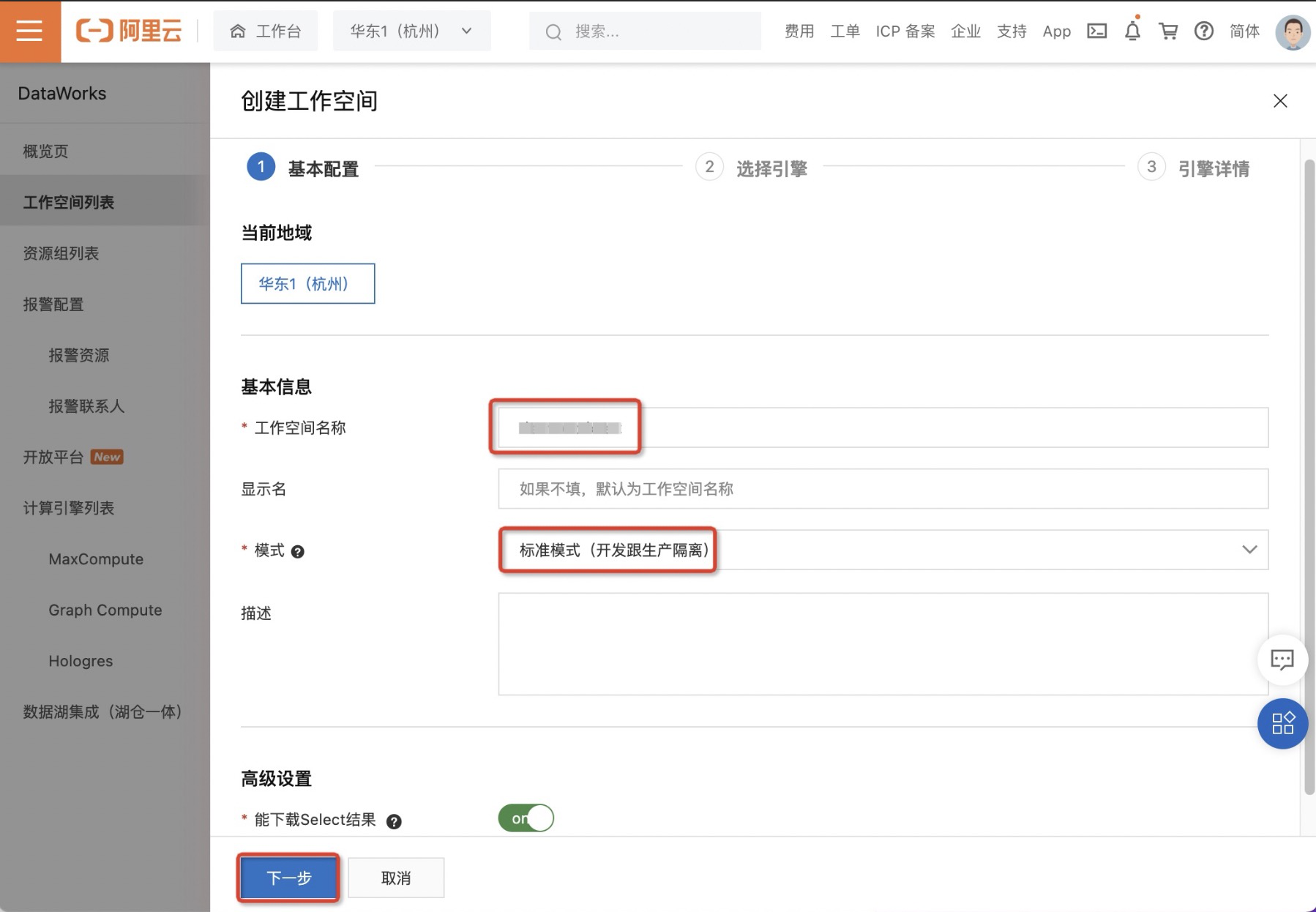
- 进入选择引擎页面,这里暂时选择计算引擎服务为MaxCompute,单击下一步。更多参数信息请参见创建工作空间中第4步。
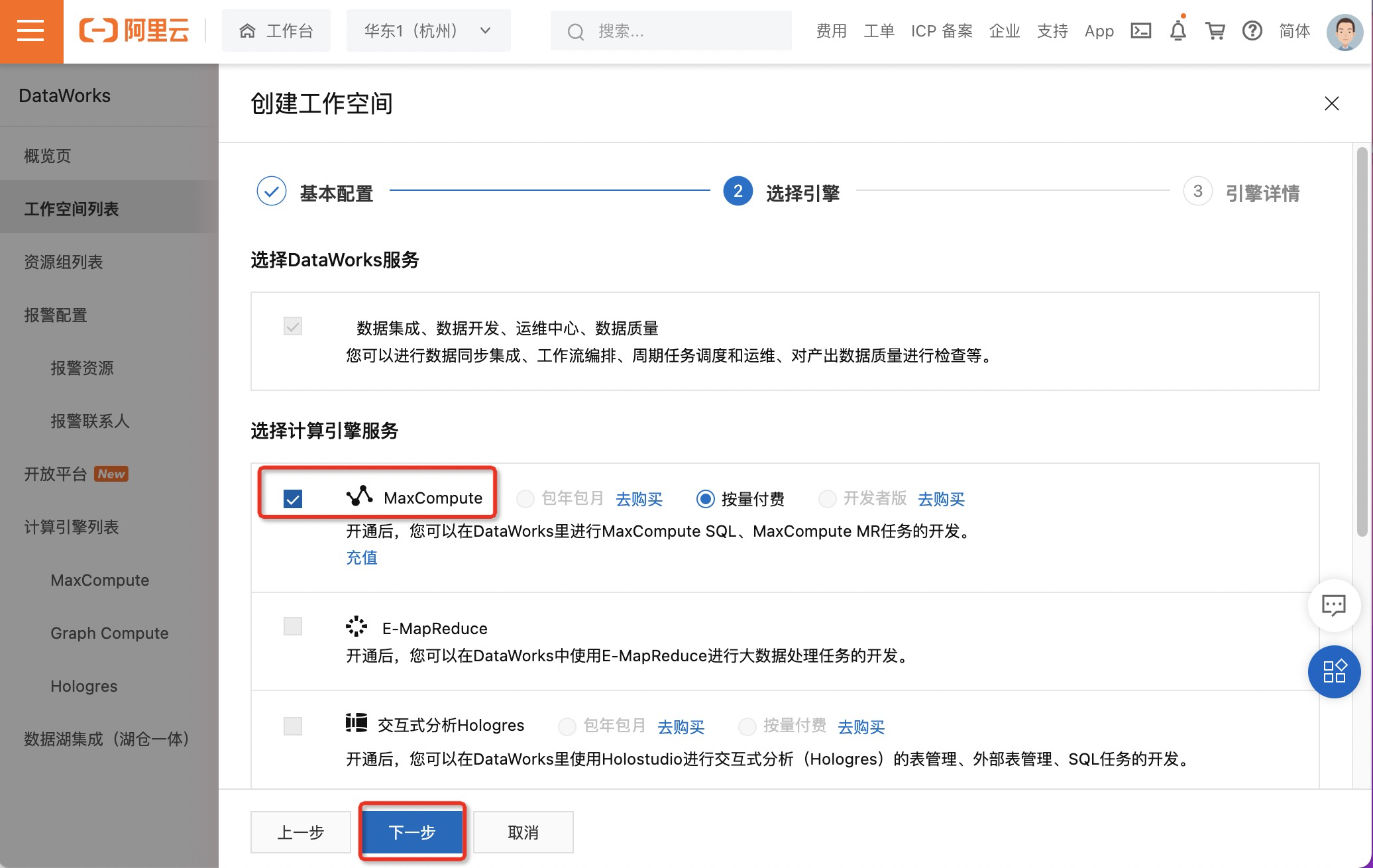
- 进入引擎详情页面,配置各项参数后,单击创建工作空间。更多参数信息请参见创建工作空间中第5步。
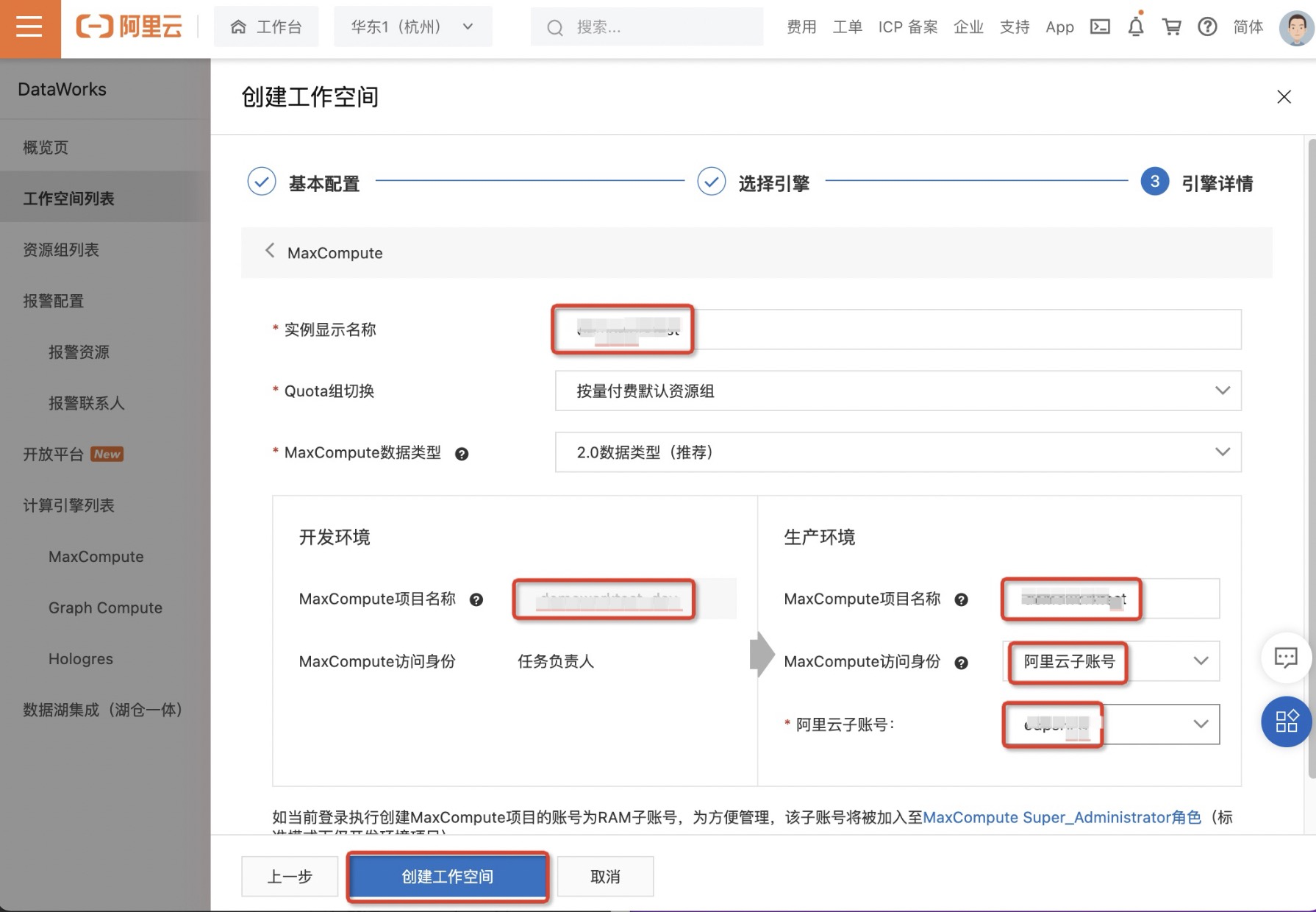
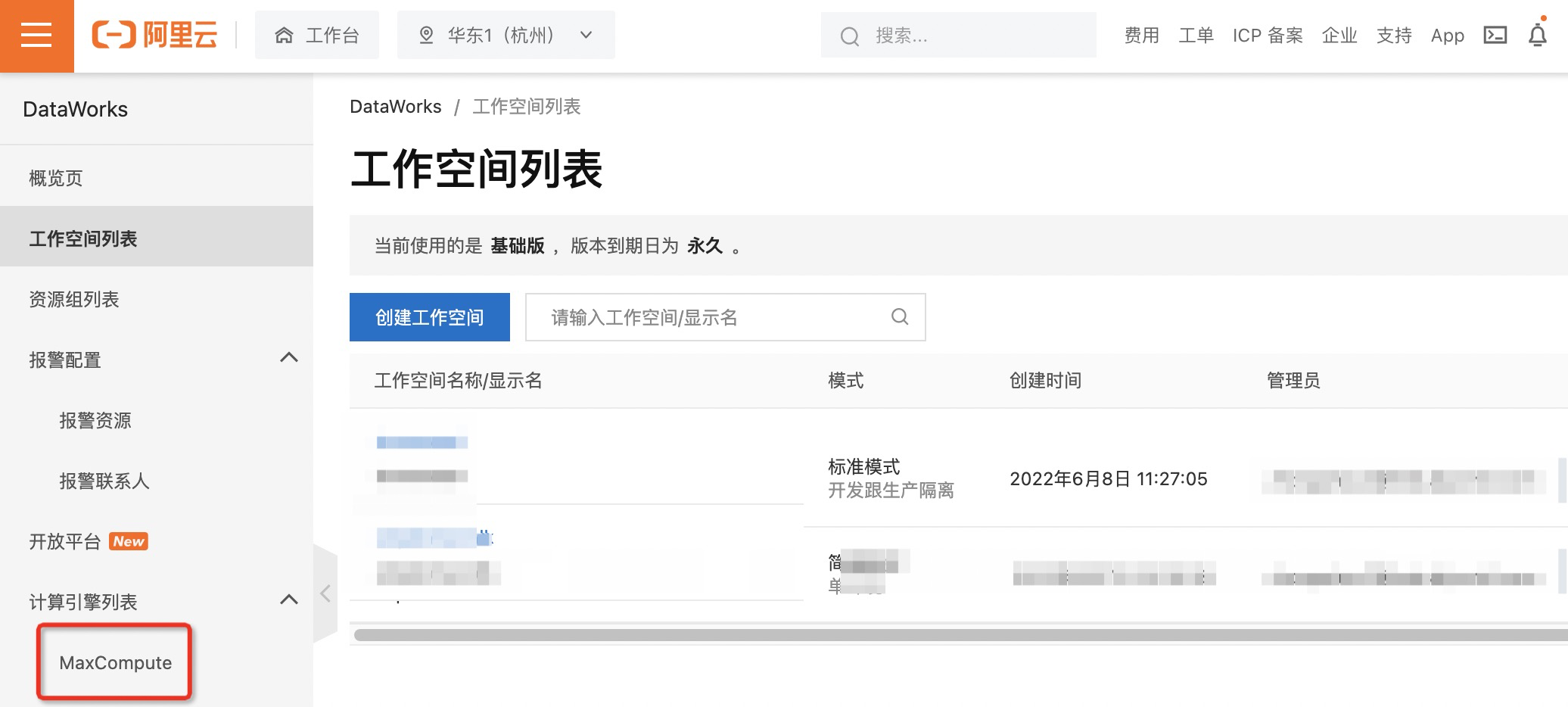
- 配置完成后,单击左侧导航栏MaxCompute即可进入Maxcompute项目管理页面看到所创建的Maxcompute项目。
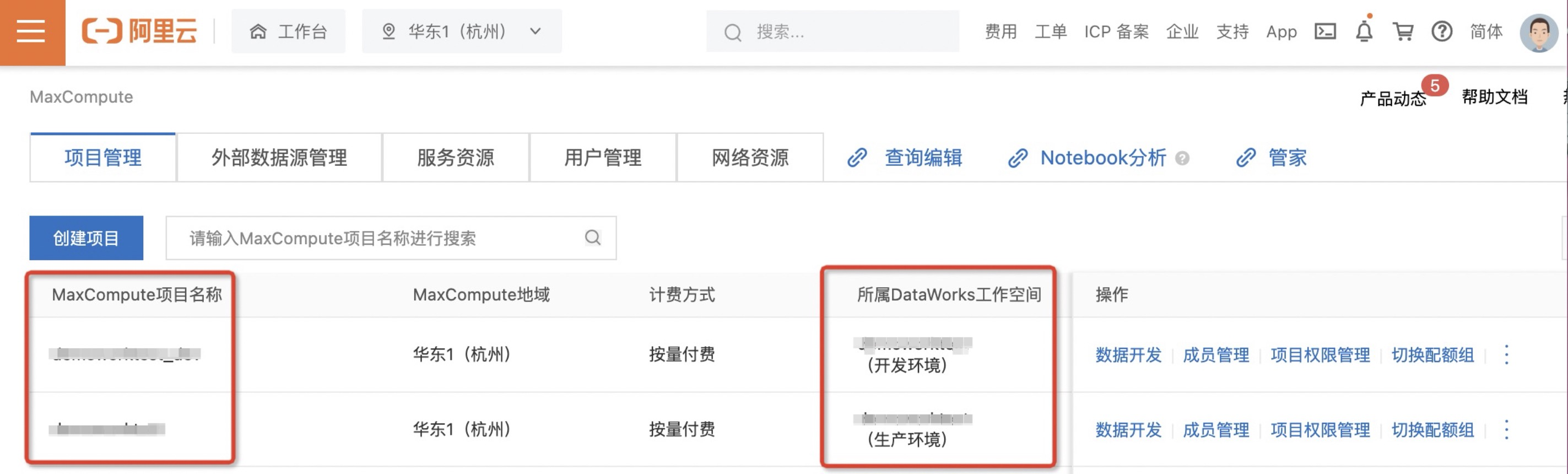
五、创建MaxCompute项目表
温馨提示:如果已有MaxCompute表,可以跳过这一步。
1.进入DataWorks控制台的工作空间列表页面,单击目标工作空间操作列的数据开发。
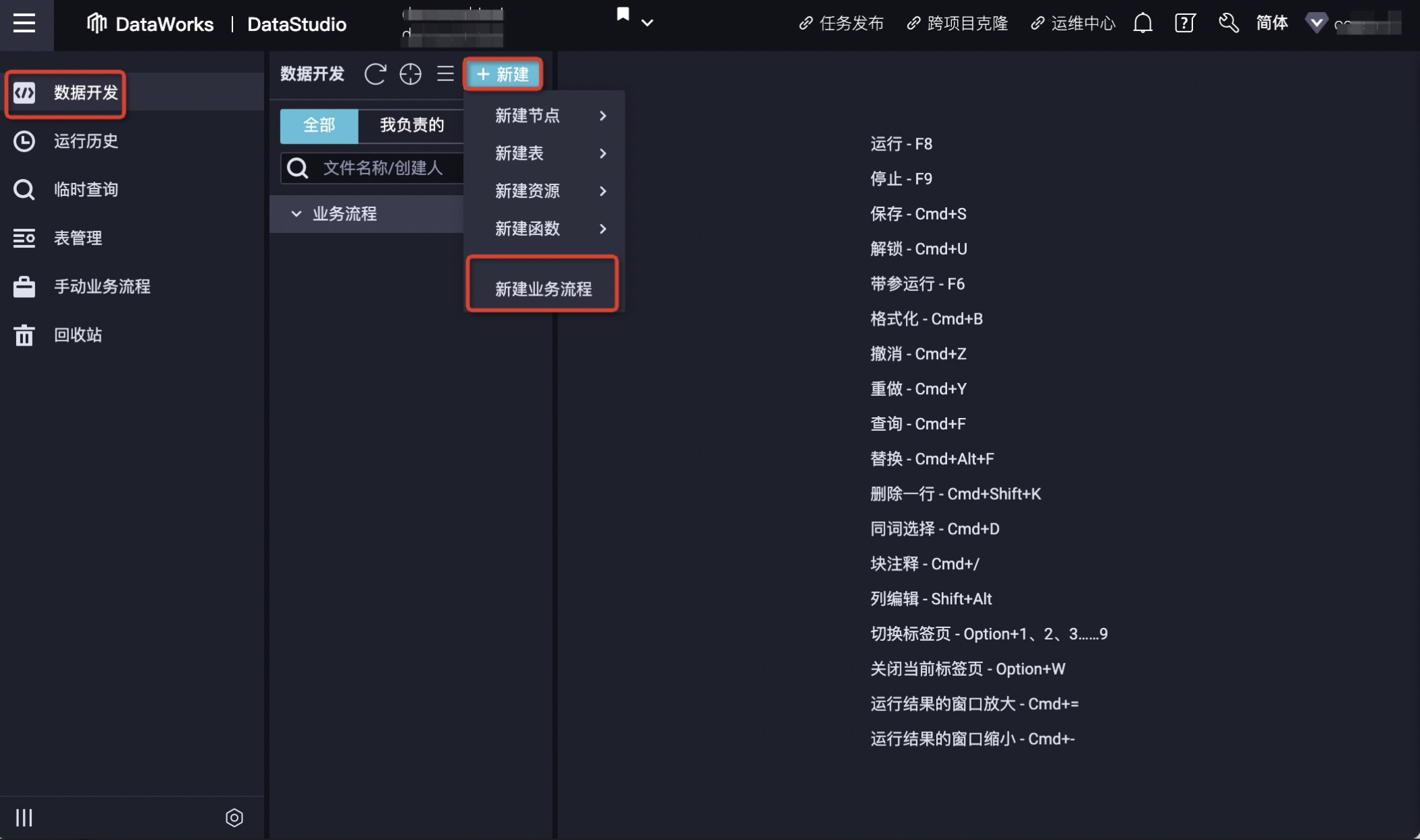
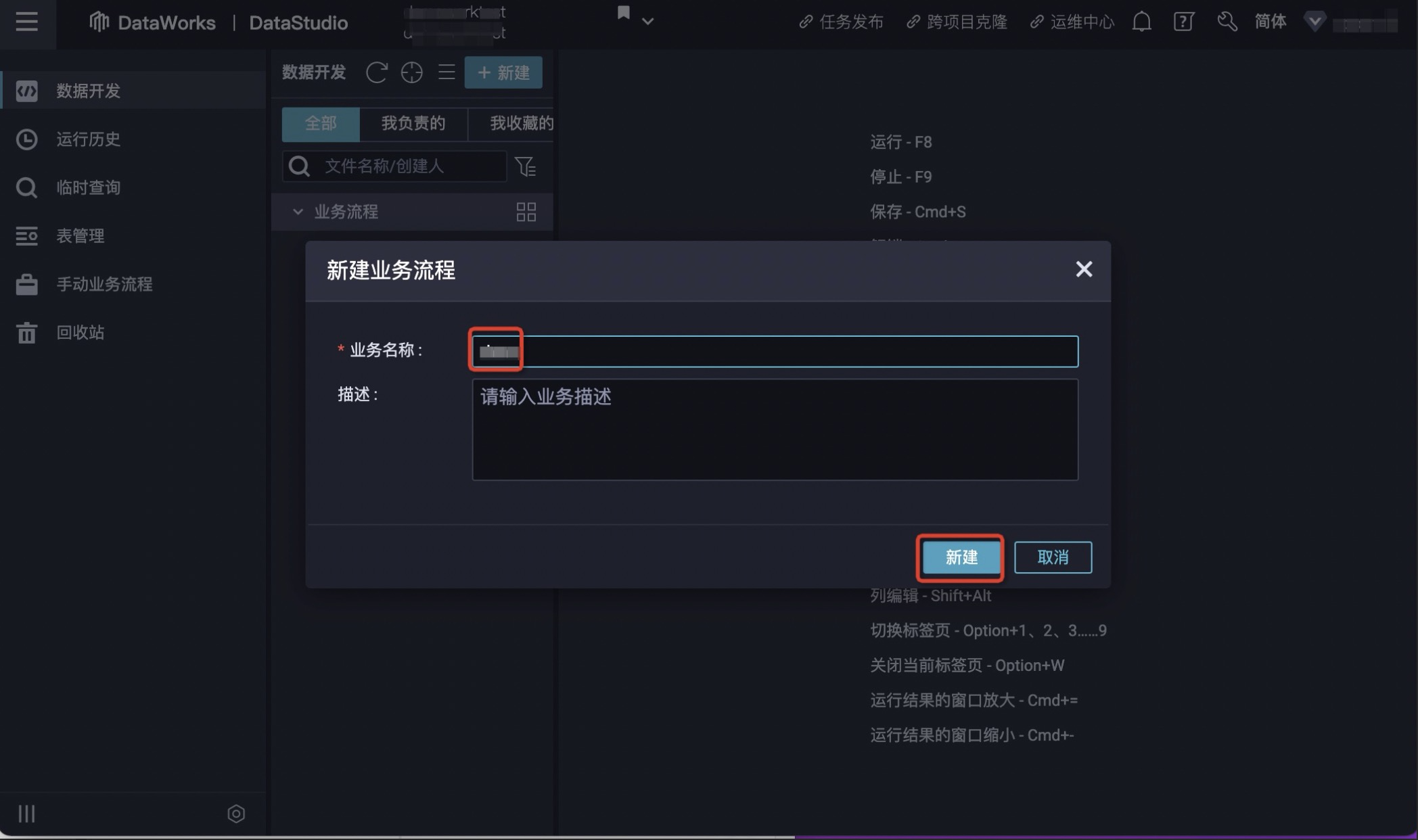
2.单击左侧数据开发> 鼠标悬停至+新建图标,单击新建业务流程,弹窗内输入业务名称。
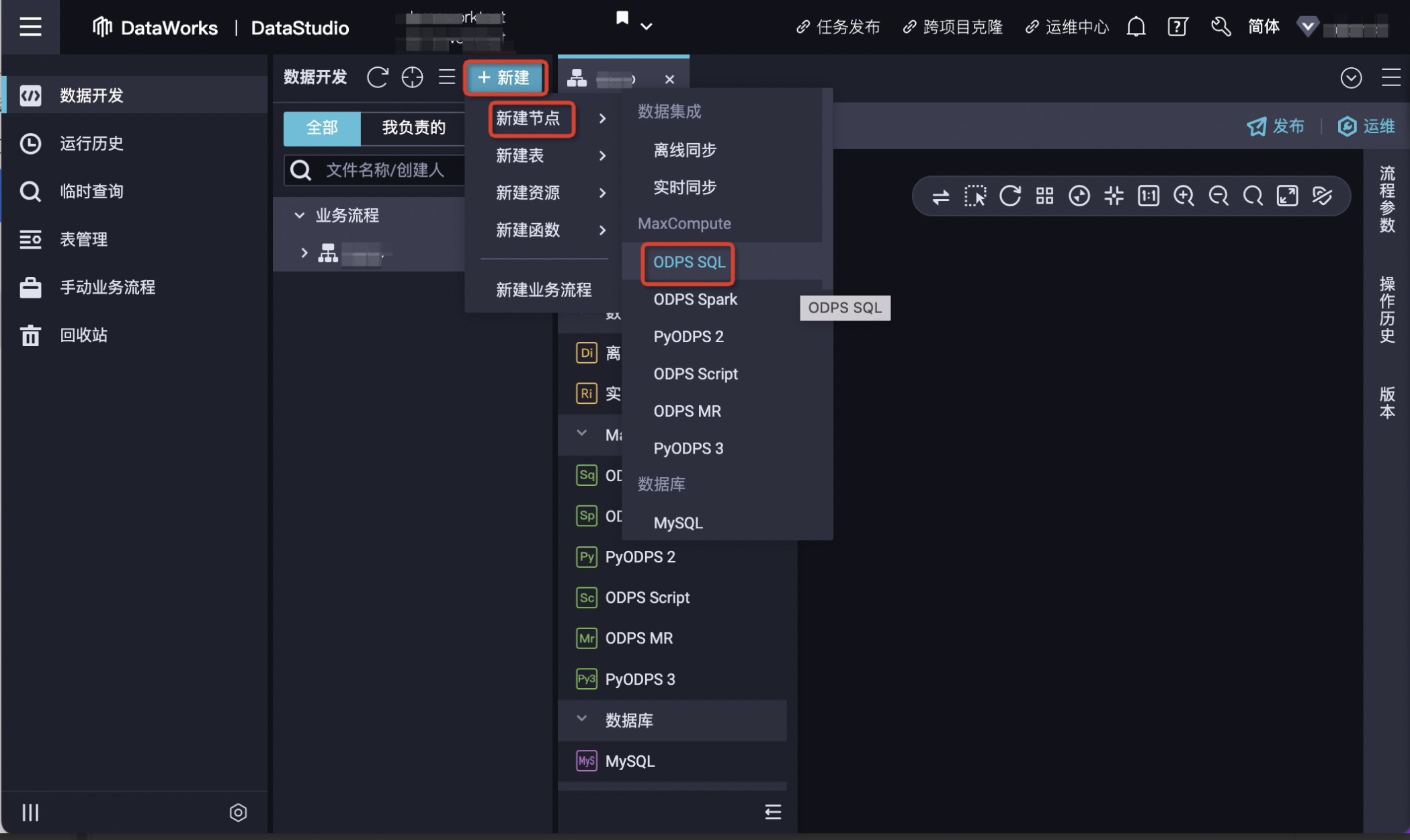
3.鼠标悬停至+新建图标,单击MaxCompute > ODPS SQL,弹窗内输入对应的节点类型、路径、名称。
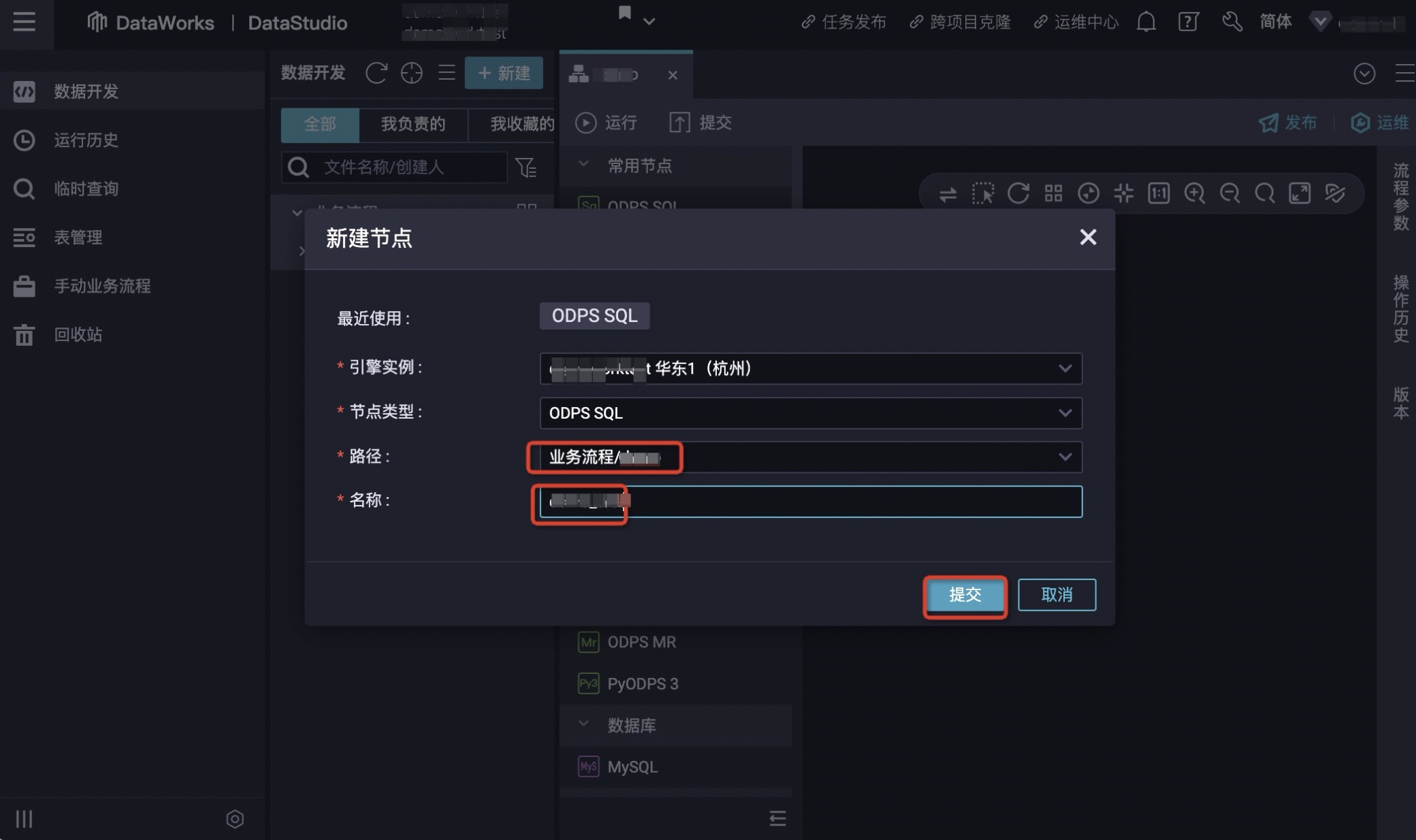
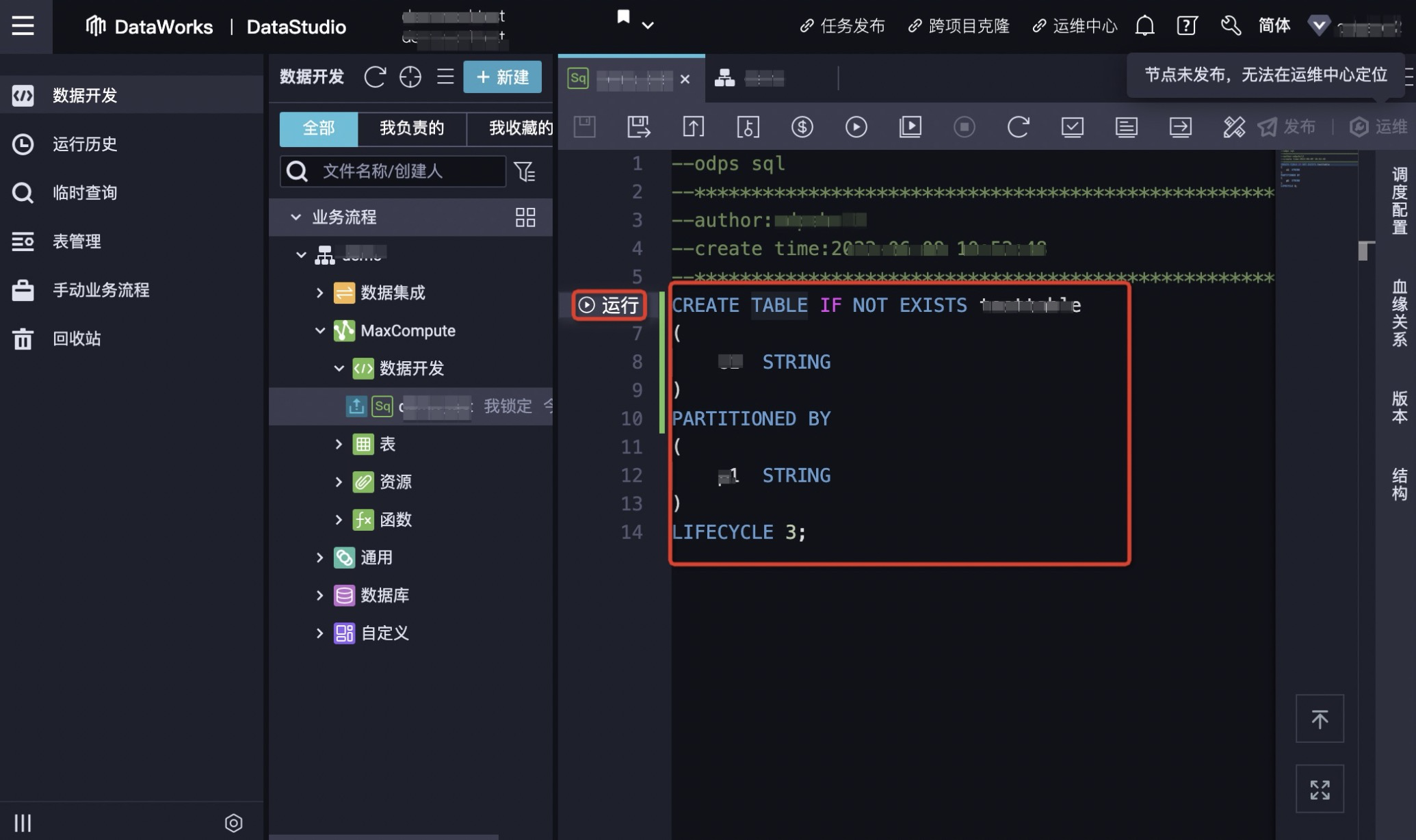
4.新建完节点后,即会跳出sql页面,输入sql语句单击运行即可进行表的创建。
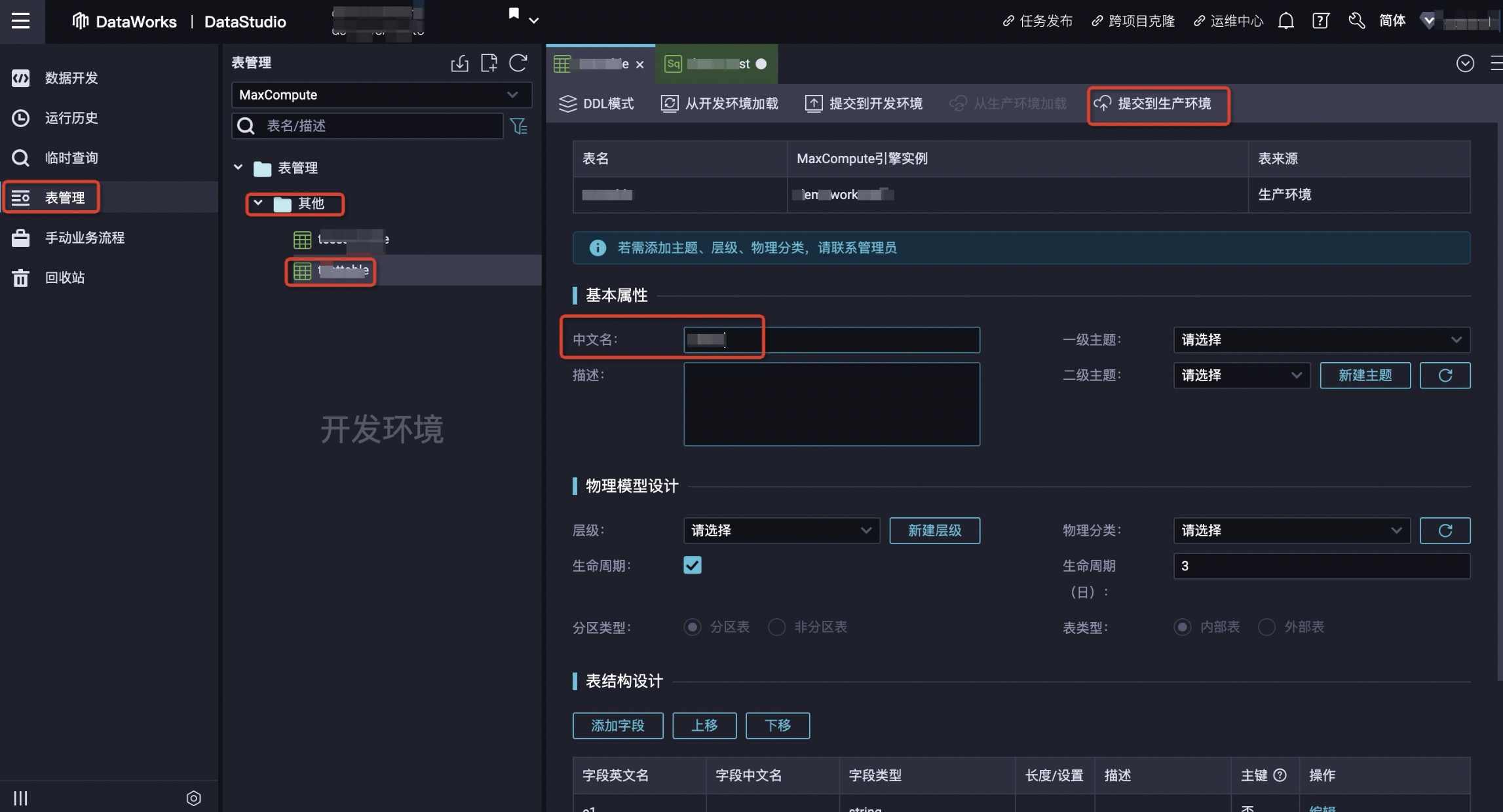
5.单击左侧表管理->其它,双击已创建的目标表即可进入表管理页面。
6.表管理页面中基本属性的中文名行输入自定义别名,然后单击提交到生产环境。
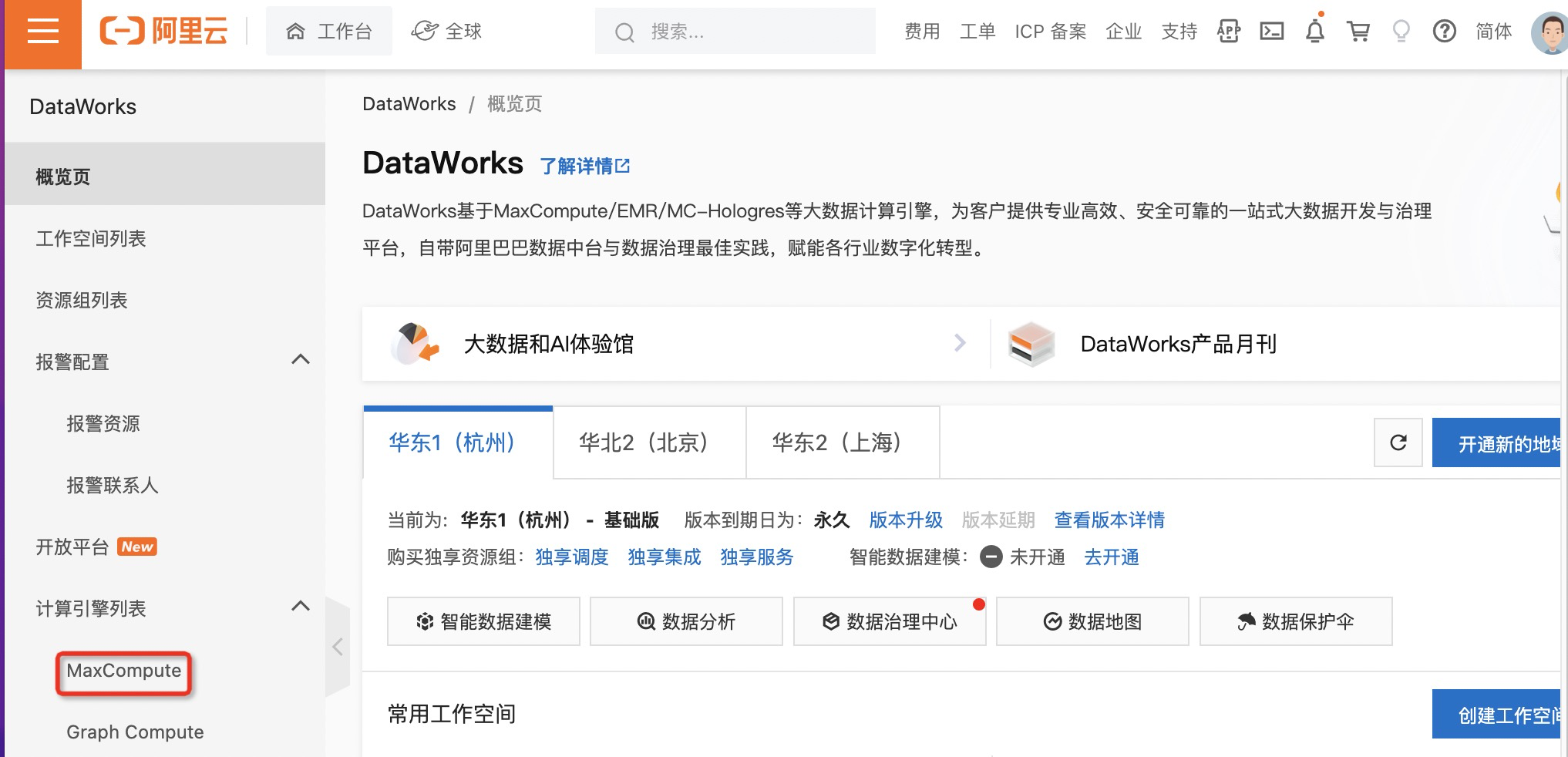
六、把角色添加到Maxcompute
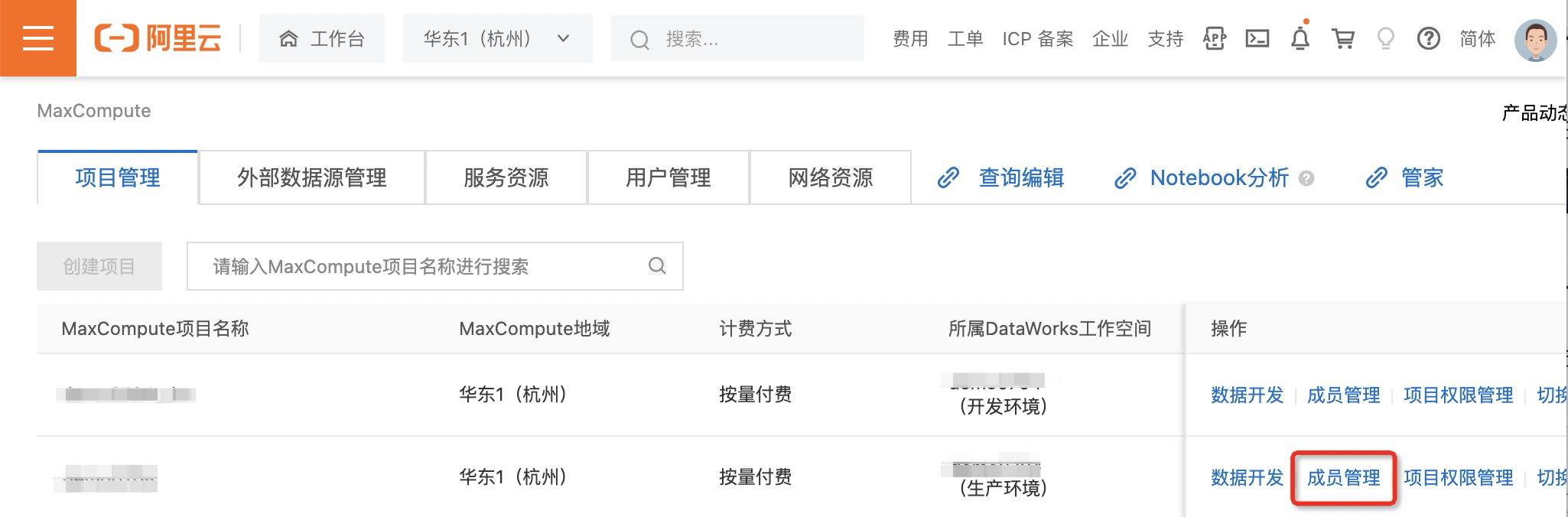
1.进入DataWorks控制台首页,单击左侧导航栏MaxCompute进入MaxCompute项目管理页。
2.在MaxCompute项目管理页,单击目标项目操作列成员管理。
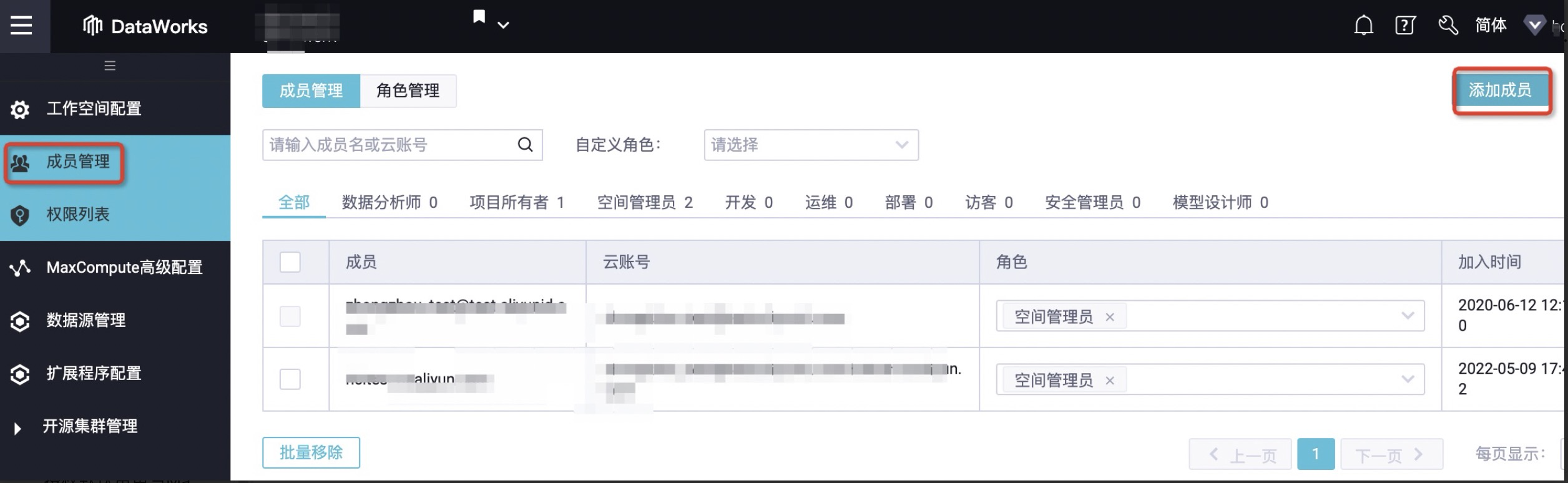
3.在成员管理页面,单击右上方的添加成员。
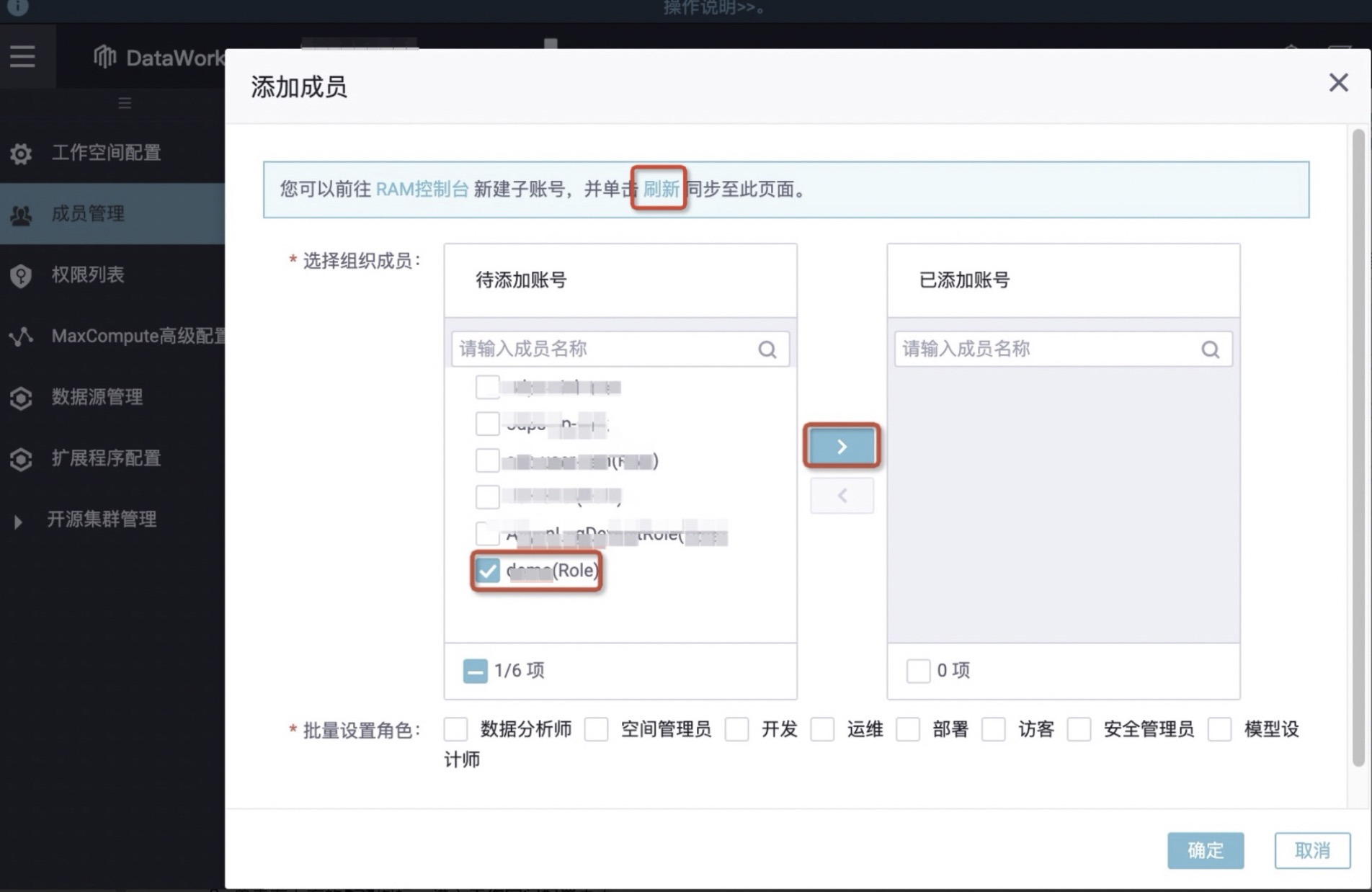
4.在添加成员对话框中,单击刷新,即可展示已创建的RAM角色。
5.在待添加账号处勾选需要添加的当前登录账号、自定义角色账号如demo,单击>,将其移动至已添加的账号中。
温馨提示:若多次刷新后,仍不能显示目标RAM角色,请参见上述第三步骤《修改角色信任策略》进行检查操作是正确。
6.选中需要授予的角色,单击确定。
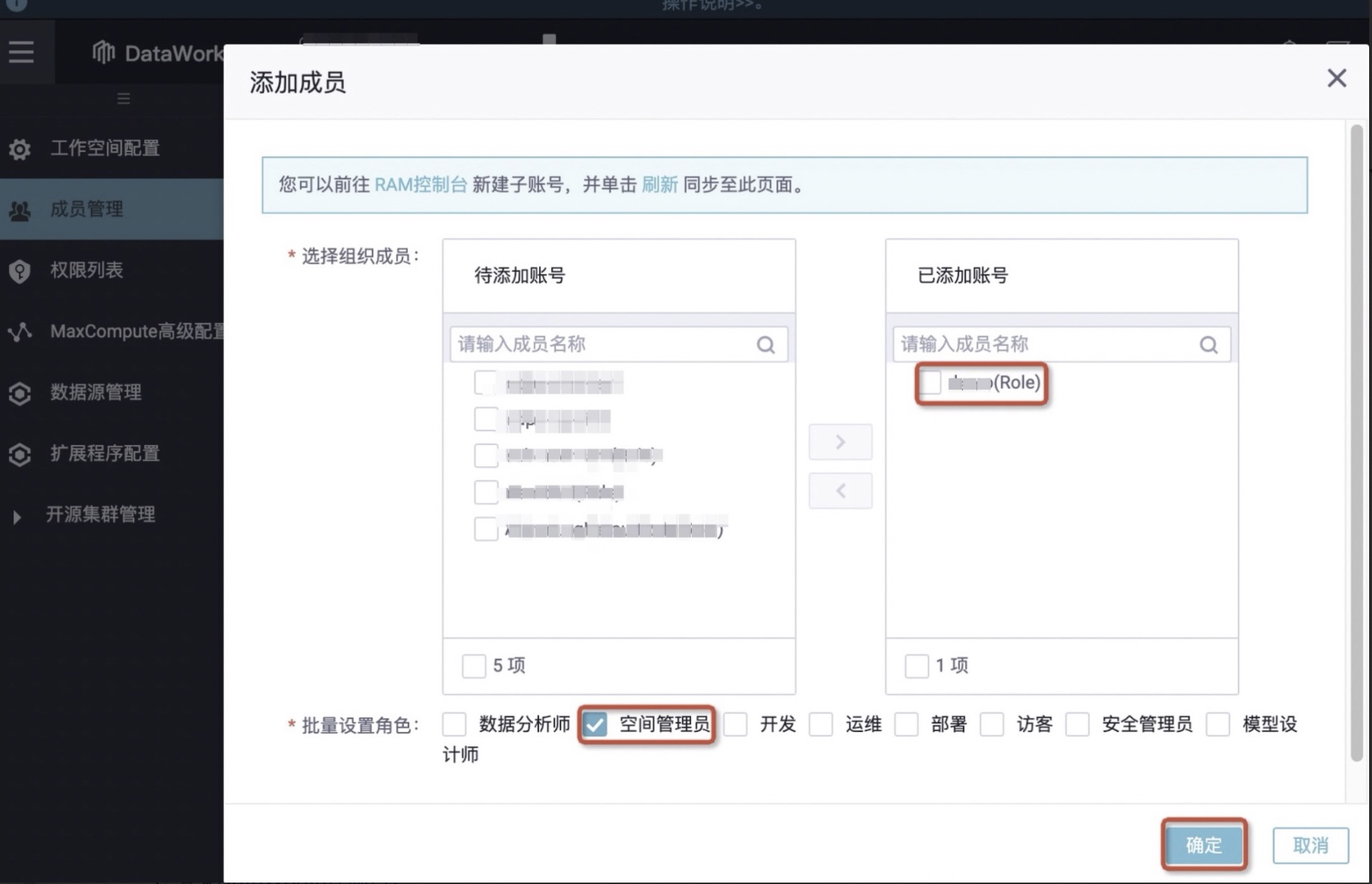
7.添加完成后,您可以在工作空间中列表中查看或修改已有的成员和对应角色,也可以从工作空间中删除非项目所有者角色的RAM用户。工作空间中成员对应角色更多信息请参见添加工作空间成员和角色第7步。
七、授予MaxCompute写入权限
1.单击目标工作空间操作列数据开发进入数据开发页面。
2.单击右上方的 图标,进入工作空间配置页面。
图标,进入工作空间配置页面。
3.在左侧导航栏,单击 后在MaxCompute 项目选择选项卡中选择生产环境下项目名称。
后在MaxCompute 项目选择选项卡中选择生产环境下项目名称。
4.单击自定义用户角色,进行MaxCompute生产项目授权。更多MaxCompute项目角色信息请参见添加工作空间成员和角色第7步。
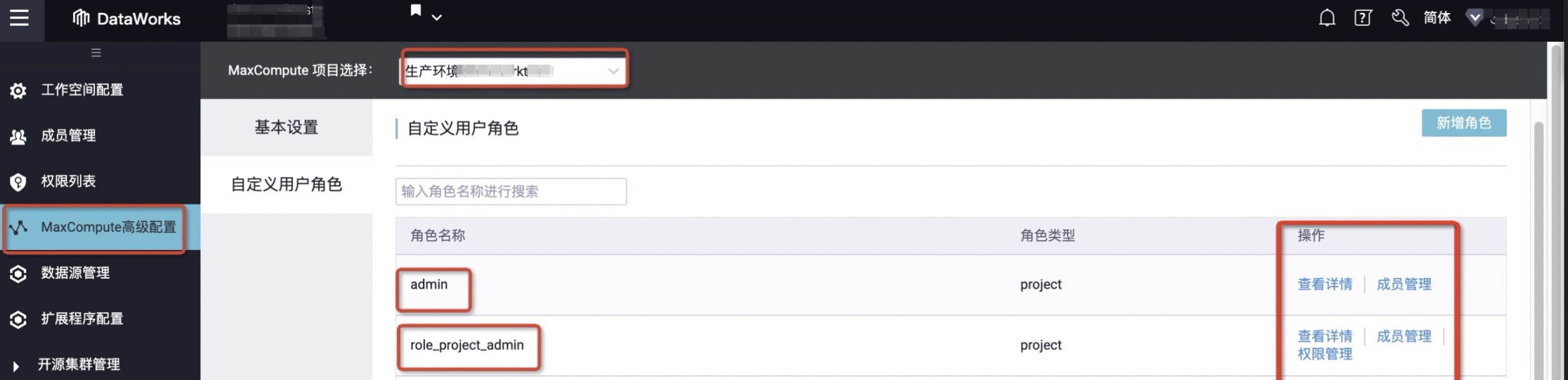
5.在角色名称为admin的操作列,单击成员管理后,在待添加账号处勾选当前操作账号(注意必须是当前操作账户)、目标RAM角色账号,单击>,将其移动至已添加的账号中并点击确定。
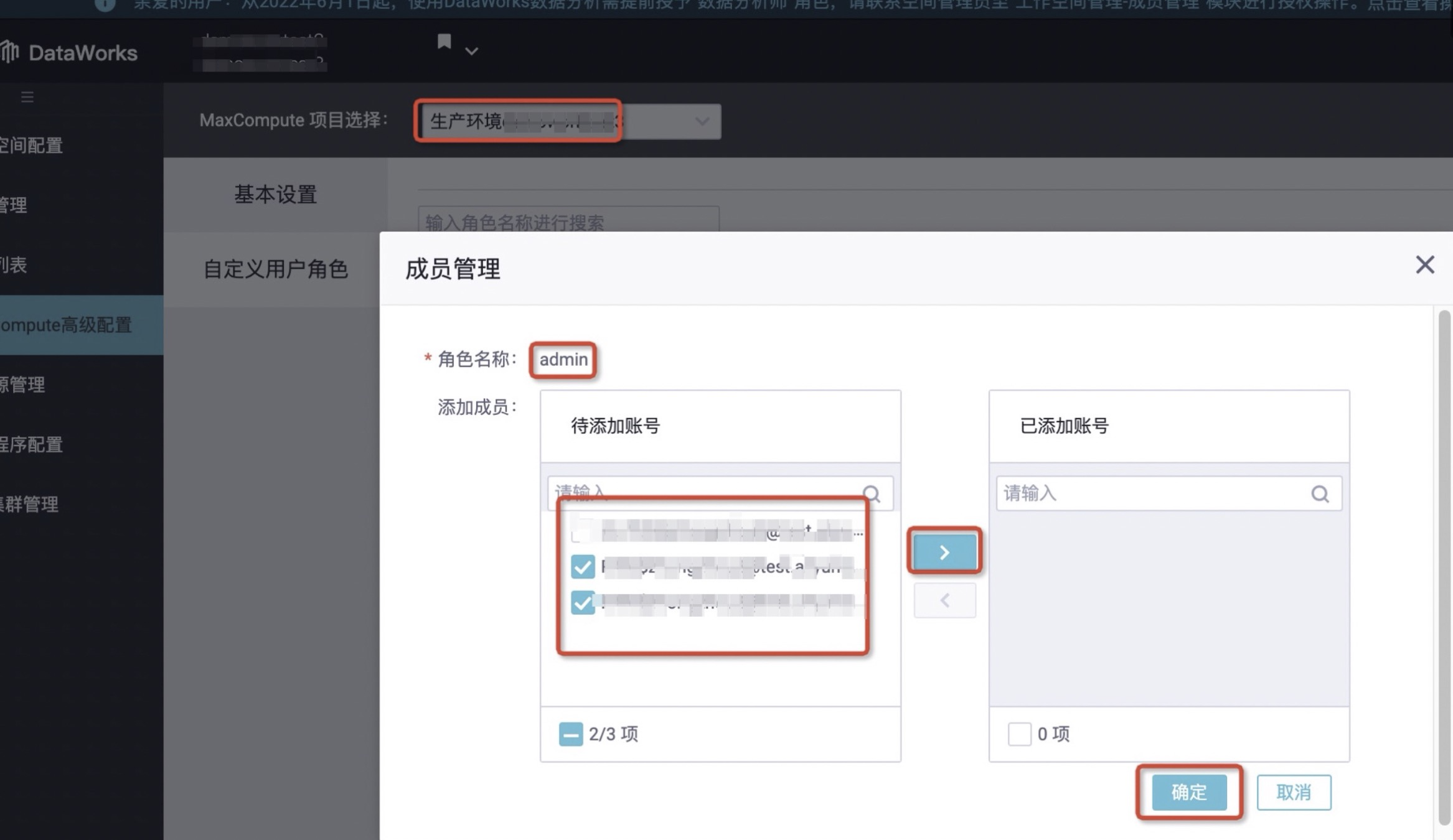
6.授予角色查看、修改、更新目标MaxCompute表的权限。
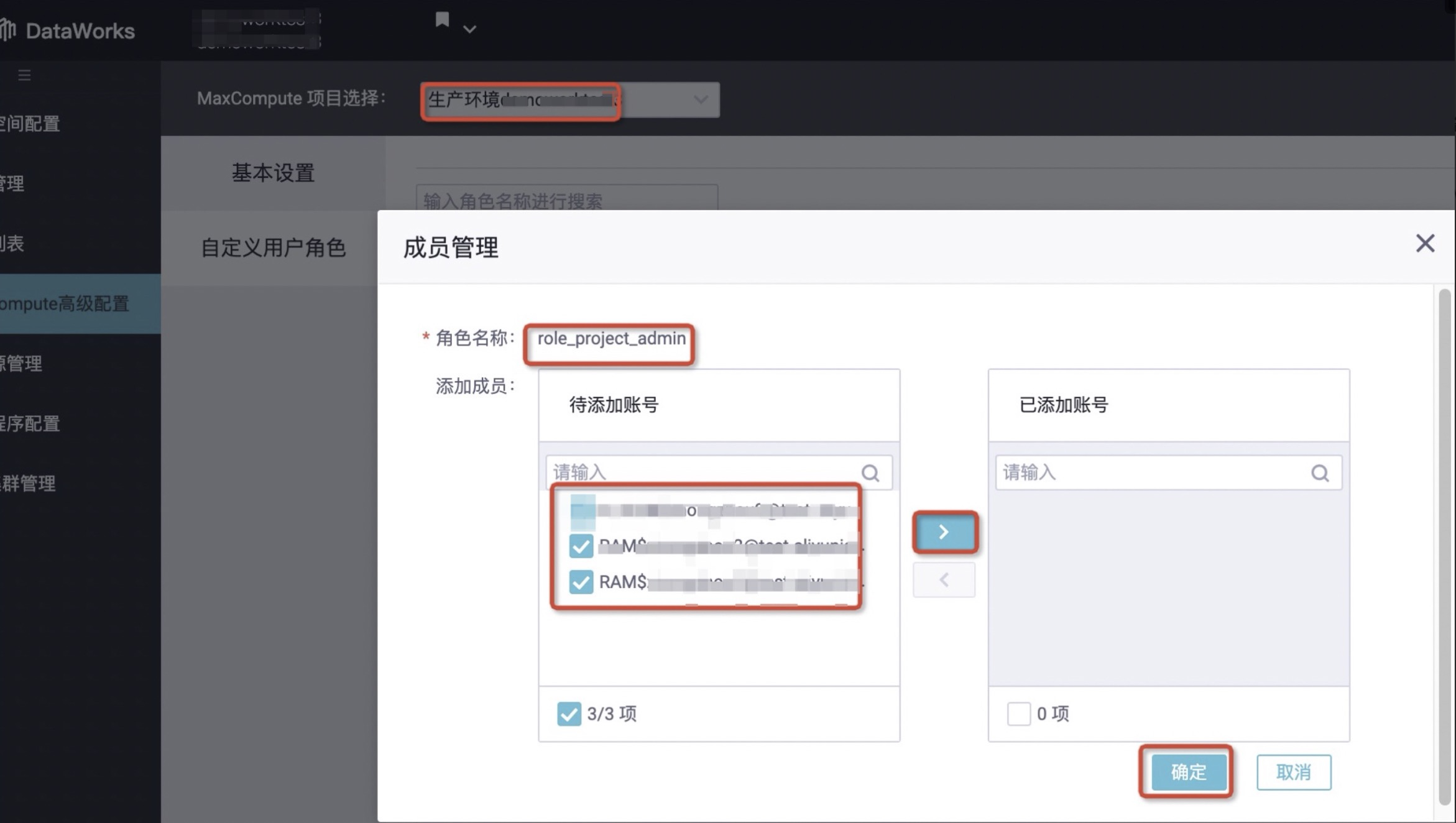
- 在角色名称为role_project_admin的操作列,单击成员管理,在待添加账号处勾选当前登录账号、目标RAM角色账号,单击>,将其移动至已添加的账号中并点击确定。
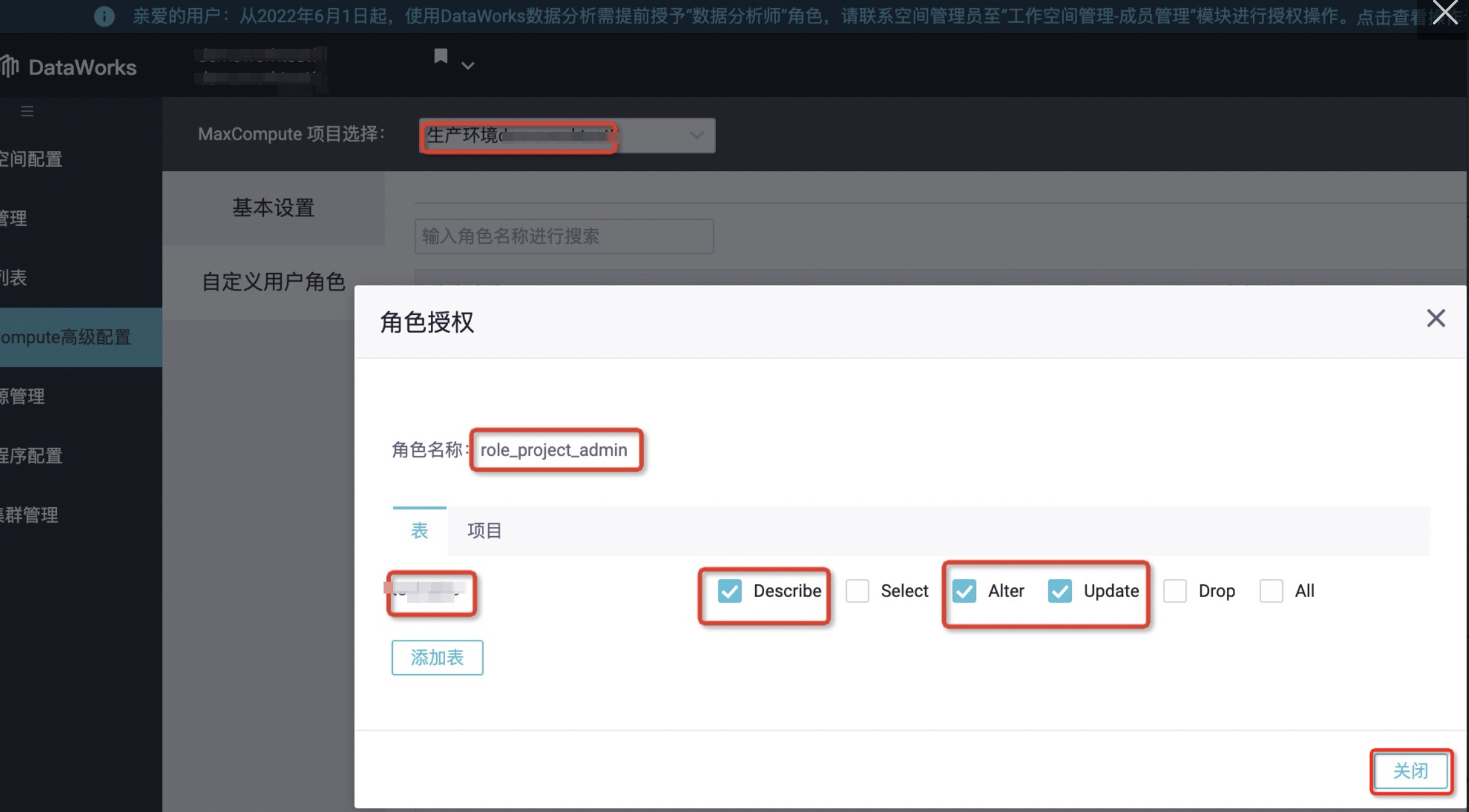
- 在角色名称为role_project_admin的操作列,单击权限管理,单击角色授权弹窗框中,单击表 > 添加表并添加已创建的MaxCompute表->选择选项卡Describe、Alter、Update > 关闭。
八、创建投递MaxCompute任务并验证投递是否成功
前提条件:
- 已创建Project和Logstore。具体操作,请请参见创建Project和Logstore。
- 已采集日志。具体操作,请参见数据采集。
- 已在MaxCompute中创建表。具体操作,请参见上述第五步创建MaxCompute项目表
1.登录日志服务控制台。
2.在Project列表区域,单击目标Project。
3.开始创建投递任务。
- 在日志存储 > 日志库页签中,单击目标Logstore左侧的>,选择数据处理 > 导出> MaxCompute(原ODPS)。
- 将鼠标悬浮在MaxCompute(原ODPS)上,单击+。
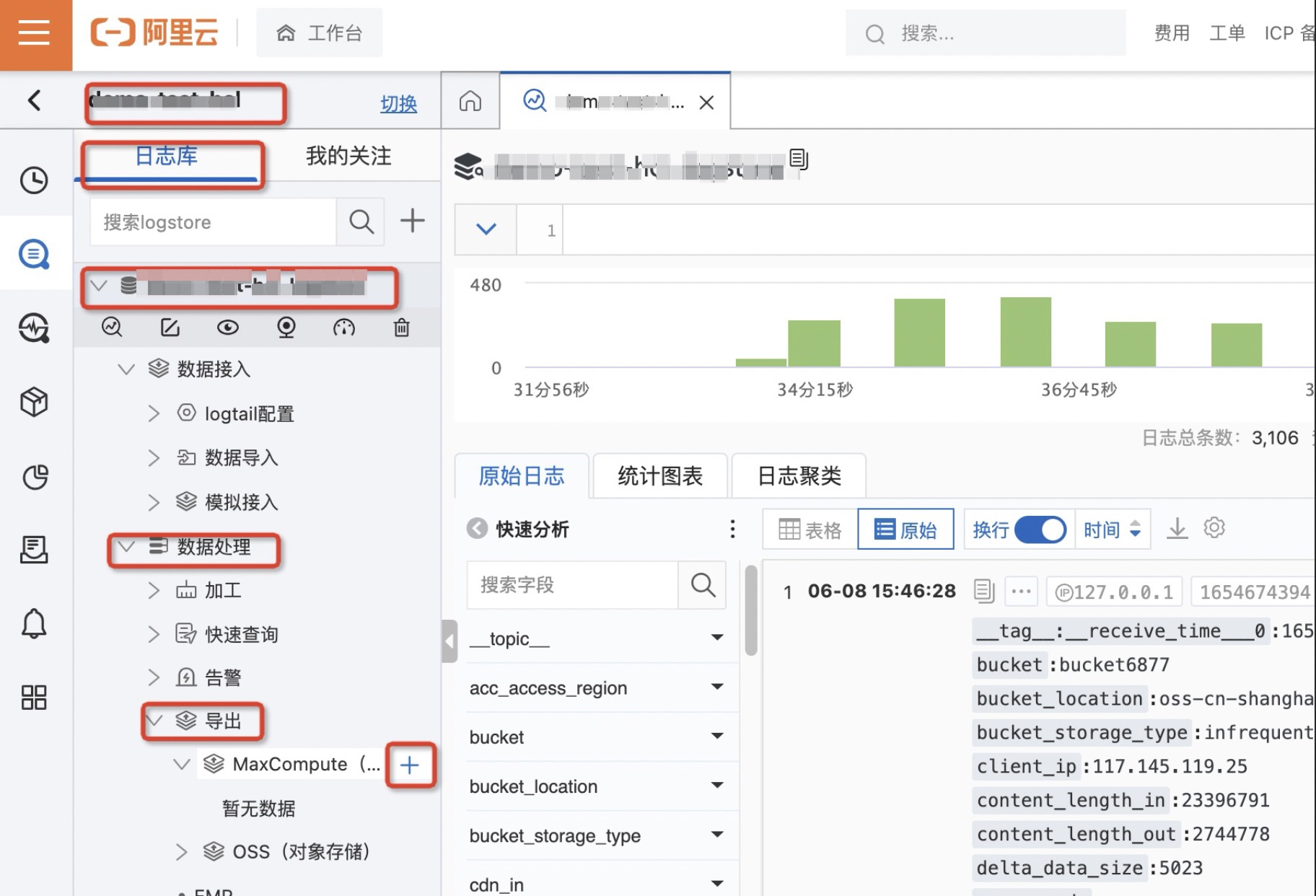
- 在MaxCompute投递功能面板中,配置如下参数,然后单击确定。
选择投递版本为新版(推荐),重要参数配置说明如下所示。
参数 |
说明 |
投递名称 |
投递任务的名称。 |
投递区域 |
目标MaxCompute表所在地域。 |
MaxCompute Endpoint |
MaxCompute地域对应的Endpoint,可以向MaxCompute发出除数据上传、下载外的所有请求。 |
Tunnel Endpoint |
MaxCompute地域对应的Tunnel Endpoint,有上传、下载数据的能力。 |
项目名 |
目标MaxCompute表所在的MaxCompute项目。 |
MaxCompute表名 |
目标MaxCompute表名称。 |
读日志服务授权 |
授予MaxCompute投递作业读取Logstore数据的权限,您可使用已完成授权的默认角色或自定义角色。 |
写入授权方式 |
您可以通过RAM用户的AccessKey或RAM角色,完成写MaxCompute的授权。 |
写MaxCompute授权 |
授予MaxCompute投递作业将数据写到MaxCompute表中的权限,您可使用已完成授权的默认角色或自定义角色。 |
MaxCompute普通列 |
左边输入框中填写与MaxCompute表列相映射的日志字段名称,右边为MaxCompute表的列名称。 说明:不允许使用同名字段。 |
MaxCompute分区列 |
左边输入框中填写与MaxCompute表分区列相映射的日志字段名称,右边为MaxCompute表分区列名称。 说明:分区字段不支持extract_others、extract_others_all。 |
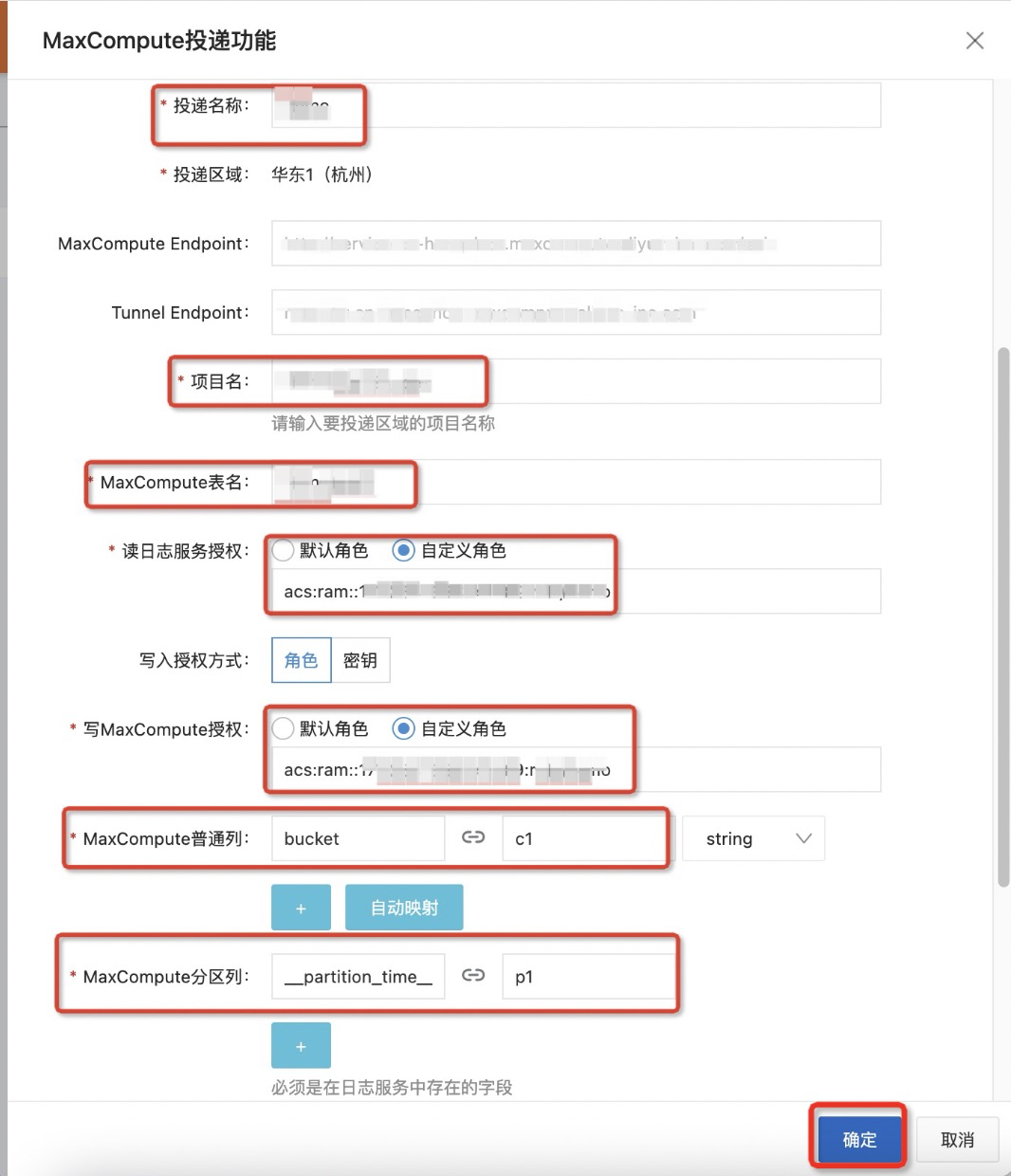
时间分区格式 |
时间分区格式。 |
时区选择 |
该时区用于格式化时间以及时间分区。 |
投递模式 |
支持实时投递和批投递。
|
开始时间范围 |
投递作业从该时间开始拉取Logstore中的数据。 |
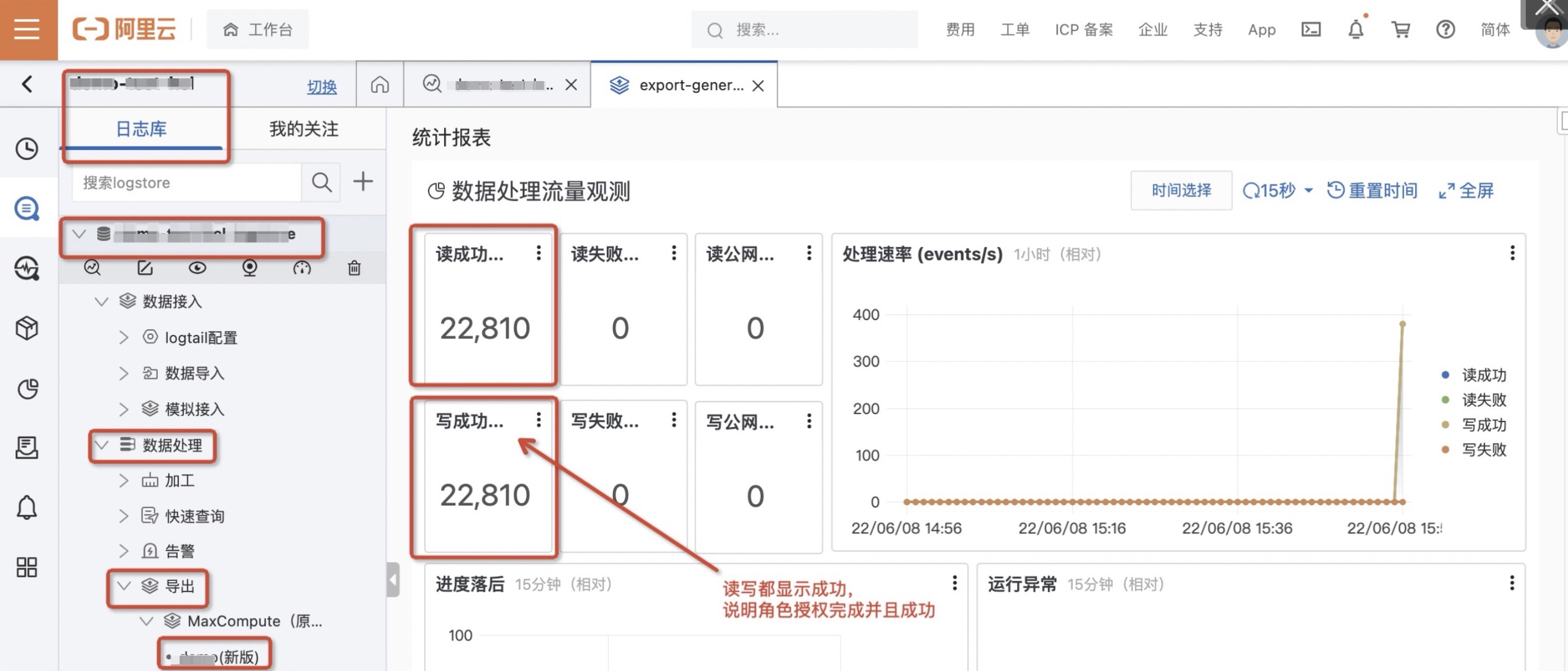
- 单击MaxCompute任务页面即可查看数据写入状态,如下参考图。
九、通过管理页面排查错误
- 登录日志服务控制台。
- 在Project列表区域,单击目标Project。
- 在日志存储 > 日志库页签中,单击目标Logstore左侧的>,选择数据处理 > 导出> MaxCompute(原ODPS)。
- 单击目标任务进入任务管理页面,如果页面没有显示内容,请通过步骤10开通投递日志。

5.通过管理页面运行异常表可及时排查错误,如下图点击信息列展开字样即可看到详细错误信息。

十、开通运行日志
说明:
开通作业运行日志后,您可以在指定Project下的internal-diagnostic_log Logstore中查看MaxCompute投递作业的运行日志与错误日志,其日志主题(__topic__)为etl_metrics。您也可以通过投递作业名称查询目标投递作业的运行日志与错误日志,对应的查询语句为job_name:作业名称,例如job_name:job-1646****946。
- 登录日志服务控制台。
- 在Project列表区域,单击目标Project。该Project为MaxCompute投递作业所在的Project。
- 在页面左上方,单击
 图标。
图标。

- 进入开通作业运行日志页面。
- 如果您开未通过该Project的详细日志,则在服务日志页签中,单击开通服务日志。
- 如果您已开通过该Project的详细日志,则在服务日志页签中,单击
 图标。
图标。


5.设置参数如下,然后单击确定。
参数 |
说明 |
作业运行日志 |
打开作业运行日志开关后,系统将在您指定的Project中自动创建一个名为internal-diagnostic_log的Logstore,用于存储Scheduled SQL、MaxCompute投递、OSS投递、数据导入等作业的运行日志与错误日志。 |
日志存储位置 |
开通作业运行日志功能后,需要选择日志的存储位置,即需要指定Project。可以设置为:
|

投递限制与常见问题
1.投递限制相关,具体请参见稳定性说明与使用限制。
2.投递过程中常见问题,具体请参见MaxCompute投递作业(新版)常见报错与问题。
