问题一:用flinkcdc读取Oracle三万条数据,半个小时了还没完事,是什么情况啊?
用flinkcdc读取Oracle三万条数据,半个小时了还没完事,是什么情况啊? 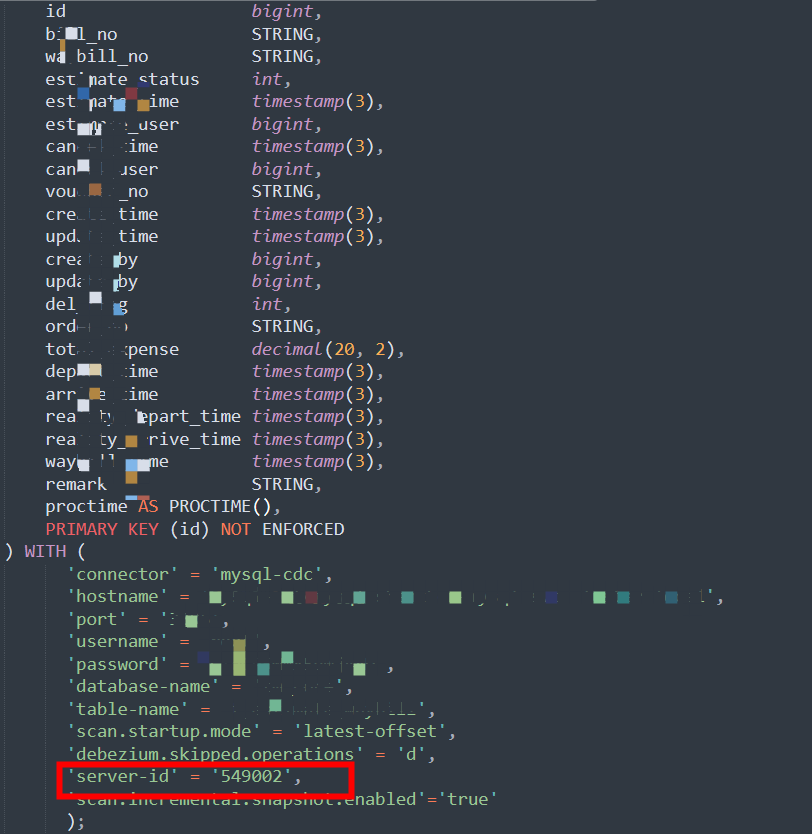
参考答案:
Flink CDC (Continuous Data Capture) 在读取Oracle数据库中的数据时出现耗时较长的情况,可能是由多种原因导致的。以下是可能导致性能瓶颈的一些常见因素:
1. Oracle Redo Log解析效率:
Flink CDC依赖于Debezium或者其他组件来解析Oracle的Redo Logs。如果Redo Log的生成速率很高,或者解析过程效率低下,可能会导致消费速度跟不上产生速度。
2. 数据库资源限制:
如果Oracle数据库本身性能较差,比如CPU、I/O、内存资源紧张,尤其是日志读取部分受到限制,会影响CDC工具的数据读取速度。
3. 网络延迟与带宽:
CDC工具从Oracle数据库读取数据并通过网络传输到下游系统(如Kafka)。如果网络状况不佳或带宽不足,会导致数据传输速度变慢。
4. Flink CDC配置问题:
Flink CDC的配置可能不合适,例如并行度设置过低、缓冲区大小不足、连接池配置不合理等,都会影响其性能表现。
5. 并发控制与锁竞争:
在读取数据过程中,如果涉及复杂的事务逻辑或者存在大量的锁竞争,也可能导致读取速度下降。
6. 表结构及索引优化:
如果所读取的表没有适当的索引或者表结构设计不利于高效读取,比如全表扫描频繁发生,也会降低读取速度。
7. 过滤条件和JOIN操作:
如果在Flink SQL中设置了复杂的过滤条件或进行了JOIN操作,这会增加计算复杂性,从而延长处理时间。
8. 故障恢复与checkpoint设置:
Flink的checkpoint间隔、状态大小、故障恢复策略等因素也可能影响整体的处理速度和稳定性。
针对以上可能的原因,你可以采取以下措施来排查和优化:
检查并调整Flink CDC的配置参数,提高并行度、增大缓冲区大小等。
查看Oracle数据库的性能指标,如资源利用率、I/O吞吐量、Redo Log生成速率等。
优化Oracle数据库的索引结构和表设计,减少不必要的IO和锁定。
确保网络环境稳定,带宽足够。
分析Flink作业的执行计划,查看是否有潜在的优化空间。
如果使用了Flink SQL,检查其中的过滤条件和JOIN操作是否可以简化或优化。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/579971
问题二:server-id是在flink-conf.yaml里面设置吗?
server-id是在flink-conf.yaml里面设置吗?
参考答案:
我用的是flinksql 直接在create table的时候设置的
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/579969
问题三:怎么用kafka接收flinkcdc的输出?
怎么用kafka接收flinkcdc的输出?
参考答案:
要使用Kafka接收Flink CDC的输出,首先需要确保你的环境中已经安装了MySQL、Kafka和Flink,并且他们的版本要能够相互兼容。然后,你需要从特定的地址下载Flink的依赖包,包括flink-sql-connector-kafka_2.11-1.13.5.jar等,并将这些包放在lib目录中。
接着,你可以使用Flink SQL来定义Kafka消费者,并指定要消费的主题和组ID。在Flink SQL中,可以使用CREATE TABLE语句来定义Kafka消费者,如下所示:
CREATE TABLE kafka_table ( id INT, name STRING, age INT ) WITH ( 'connector' = 'kafka', 'topic' = 'your_topic', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'testGroup', 'format' = 'json' );
在这个例子中,我们创建了一个名为kafka_table的表,该表将从名为'your_topic'的Kafka主题中读取数据。同时,我们指定了Kafka的引导服务器(bootstrap servers)为'localhost:9092',消费者组ID为'testGroup',并指定了数据的格式为JSON。
最后,你可以使用Flink SQL的INSERT INTO语句将Flink CDC的输出插入到Kafka表中,如下所示:
INSERT INTO kafka_table SELECT id, name, age FROM source_table;
在这个例子中,我们从名为source_table的源表中选择所有的字段,并将结果插入到kafka_table表中。这样,你就可以使用Kafka来接收Flink CDC的输出了。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/579968
问题四:Flink CDC这个整库同步到doris,好像和mysql有点区别?
Flink CDC这个整库同步到doris,好像和mysql有点区别?shou create db.table,要先use db 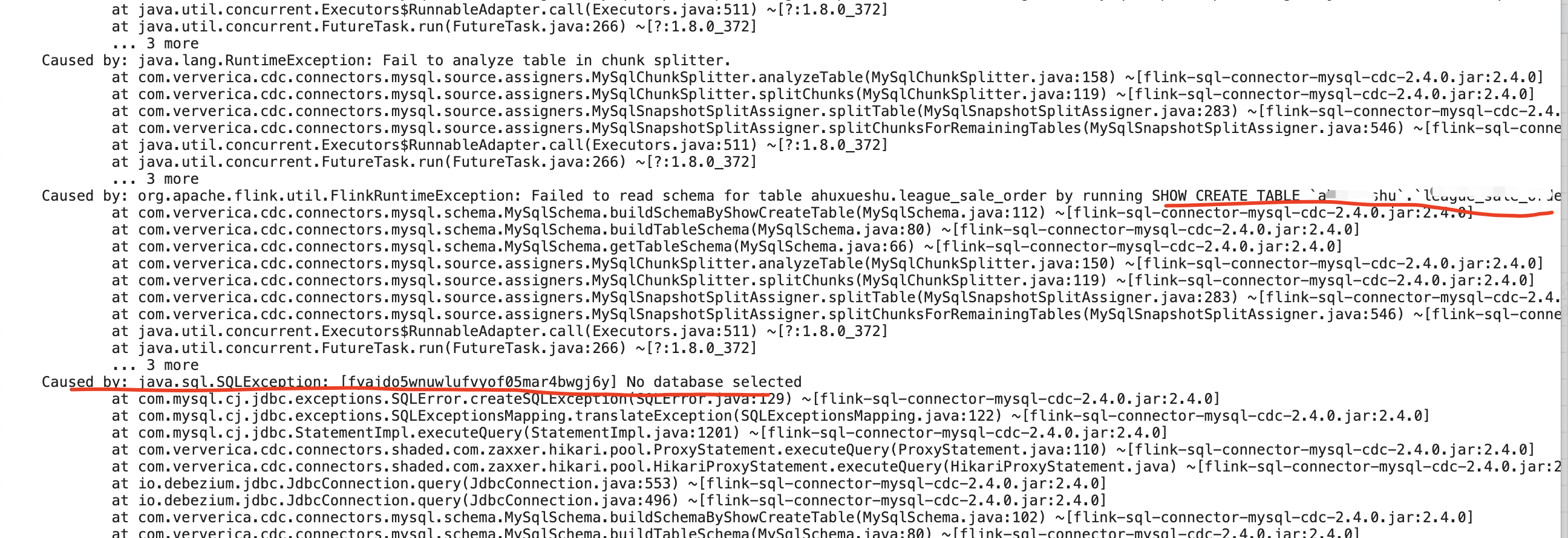
按照doris官方文档这个来的
参考答案:
我感觉你的这个配置写的有问题 
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/579967
问题五:Flink CDC怎么确定已经从全量阶段转为增量阶段了呢?
Flink CDC怎么确定已经从全量阶段转为增量阶段了呢?
参考答案:
currentEmitEventTimeLag指标有数据
关于本问题的更多回答可点击进行查看:
