问题一:Flink CDC进行多表的数据 全量+增量 同步,报错日志如下?
Flink CDC进行多表的数据 全量+增量 同步,测试发现表数量为23个时还能正常运行(有部分任务失败会自动重启成功),在往上(比如24,25,26张表)就不能成功了(有部分任务失败且自动重启也不成功)。报错日志如下。我提交任务的运行语句如下.:
./bin/flink run-application --target kubernetes-application -Dkubernetes.cluster-id=cluster231122ba -Dtaskmanager.network.memory.buffer-debloat.enabled=true -Dtaskmanager.network.memory.buffer-debloat.target=3s -Dtaskmanager.memory.process.size=7000m -Dtaskmanager.numberOfTaskSlots=1 -Dkubernetes.container.image.ref=swr.cn-north-4.myhuaweicloud.com/commons/toll_pro_02:1.17.1 -Dkubernetes.container.image.pull-secrets=regcred3 -Dkubernetes.namespace=flink -Dkubernetes.jobmanager.service-account=flink-service-account -Dkubernetes.rest-service.exposed.type=NodePort --pyModule ls_card_blacklist_28 --pyFiles /opt/python_codes/ls_card_blacklist_32.py?
参考回答:
从报错日志来看,问题可能出在任务数量过多导致的资源不足。当表的数量达到24、25、26张时,任务失败且自动重启也不成功。为了解决这个问题,你可以尝试以下方法:
- 增加Flink集群的资源,例如增加TaskManager的数量或者提高每个TaskManager的内存和CPU资源。
- 优化你的Flink CDC程序,减少任务数量。例如,你可以将多个表的数据合并到一个任务中进行同步,以减少任务数量。
- 调整Flink CDC的配置参数,例如增加
taskmanager.numberOfTaskSlots的值,以便为更多的任务分配资源。 - 检查你的数据库连接配置,确保可以正常连接到所有需要同步的表。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/577328
问题二:Flink CDC2.4.1 同步mysql报错这个,这个可以是因为什么原因啊?
Flink CDC2.4.1 同步mysql报错这个,已经引了mysql-connector-java 8.0的包,这个可以是因为什么原因啊?Caused by: javax.net.ssl.SSLException: Unsupported record version Unknown-0.0cdc里面还会用到jdbc吗?
参考回答:
这个错误可能是由于MySQL Connector/J版本不兼容导致的。请确保您使用的MySQL Connector/J版本与Flink CDC 2.4.1兼容。建议您使用MySQL Connector/J 8.0或更高版本。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/577325
问题三:flinkcdc连接sqlserver,提示【已超过了锁请求超时时段】,这是什么原因?
flinkcdc连接sqlserver,提示【已超过了锁请求超时时段】,但直接用jdbc连这个库是可以用的,这是什么原因?
参考回答:
这个问题可能是由于Flink CDC在连接SQL Server时,请求锁的超时时间设置过短导致的。您可以尝试增加Flink CDC连接SQL Server时的锁请求超时时间来解决该问题。
具体来说,您可以在Flink CDC的JDBC URL中添加lockTimeout参数来设置锁请求超时时间。例如:
jdbc:sqlserver://localhost:1433;databaseName=mydb;user=myuser;password=mypassword;lockTimeout=60000
在这个例子中,我们将锁请求超时时间设置为60秒(60000毫秒)。您可以根据实际情况调整这个值。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/577322
问题四:Flink CDC中File is not a valid field name 遇到过没?
Flink CDC中File is not a valid field name 遇到过没?Oracle同步,全改成大写了还是有问题,任务同步一段时间就会报错
参考回答:
在Flink CDC中,如果遇到"File is not a valid field name"的错误,通常是在Flink CDC中,如果遇到"File is not a valid field name"的错误,通常是因为源表中存在一个名为"file"的字段,而该字段在目标系统中不存在或名称不同。
对于Oracle同步的情况,即使将所有字段名都改成大写,仍然可能会出现问题。这是因为Oracle数据库中的表结构和字段名是区分大小写的,因此需要确保源表和目标表中的字段名完全一致,包括大小写。
为了解决这个问题,您可以尝试以下步骤:
- 检查源表和目标表中的字段名是否完全一致,包括大小写。可以使用SQL查询语句来查看表结构,例如:
SELECT column_name, data_type FROM user_tab_columns WHERE table_name = 'source_table'; SELECT column_name, data_type FROM user_tab_columns WHERE table_name = 'target_table';
- 如果发现字段名不一致,可以修改目标表的结构,将字段名改为与源表一致的名称和大小写。可以使用ALTER TABLE语句来修改表结构,例如:
ALTER TABLE target_table RENAME COLUMN old_field_name TO new_field_name;
- 修改Flink CDC作业的配置,确保源表和目标表中的字段名一致。可以在Flink CDC作业的配置文件中指定源表和目标表的字段映射关系,例如:
"source": { "topic": "oracle-source-topic", "username": "your-username", "password": "your-password", "connection-url": "jdbc:oracle:thin:@localhost:1521:orcl", "table-name": "source_table", "schema-registry-url": "http://localhost:8081", "key-converter": "io.debezium.relational.history.FileDatabaseHistory.KeyConverter", "value-converter": "io.debezium.relational.history.FileDatabaseHistory.ValueConverter", "column-mappings": [ { "source": "old_field_name", "target": "new_field_name" } ] }, "sink": { "topic": "oracle-sink-topic", "username": "your-username", "password": "your-password", "connection-url": "jdbc:oracle:thin:@localhost:1521:orcl", "table-name": "target_table", "schema-registry-url": "http://localhost:8081", "key-converter": "io.debezium.relational.history.FileDatabaseHistory.KeyConverter", "value-converter": "io.debezium.relational.history.FileDatabaseHistory.ValueConverter", "column-mappings": [ { "source": "new_field_name", "target": "new_field_name" } ] }
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/577316
问题五:Flink CDC有没有遇到过Completed Job List任务数不全的问题?
Flink CDC有没有遇到过Completed Job List任务数不全的问题? 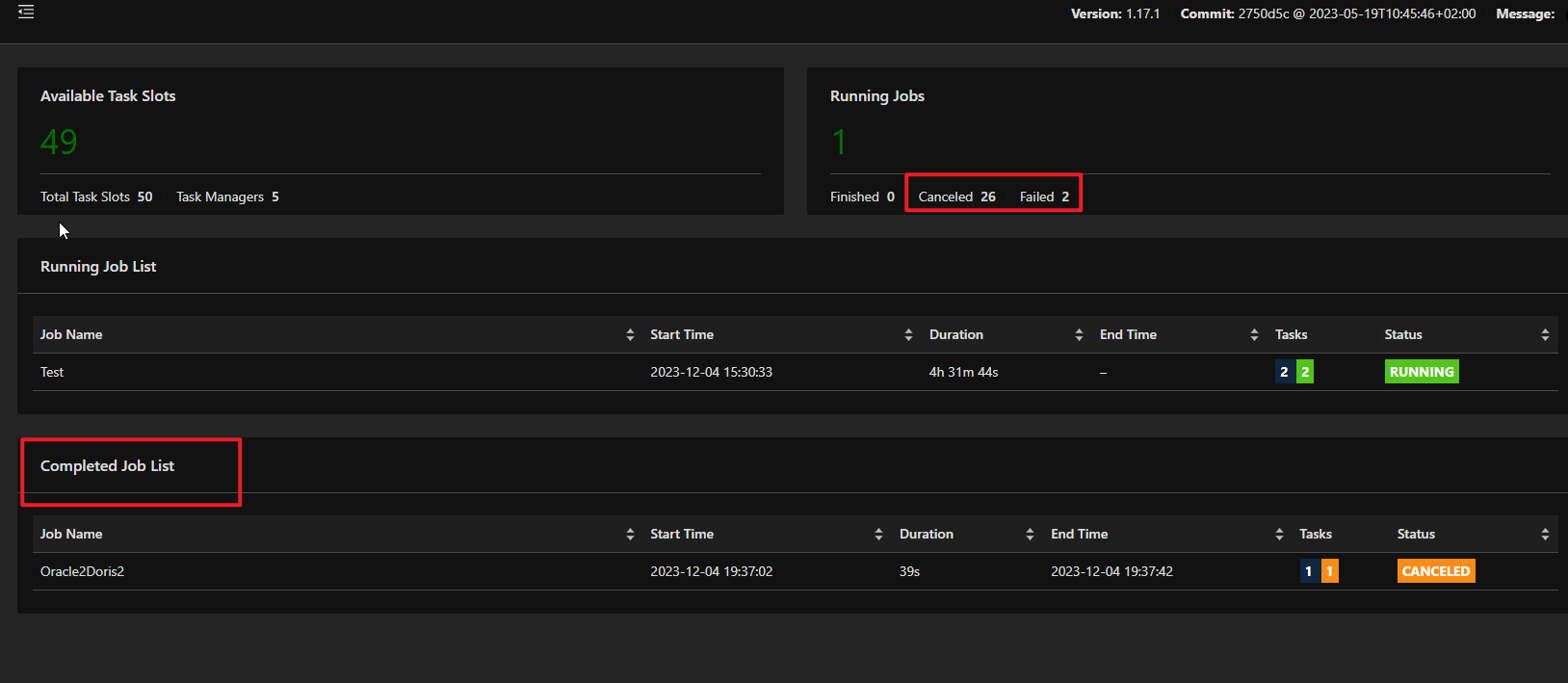
参考回答:
对于Flink CDC的Completed Job List任务数不全的问题,目前并没有明确的相关信息。如果你在使用Flink CDC时遇到了这个问题,可能需要结合具体的任务配置和运行情况进行分析和排查。同时,如果遇到任务升级时动态加新表(全量+增量)的问题,目前的一个临时解决方案是把任务分成了全量(initial_only)和增量两个任务,在全量任务导完数据后再恢复增量任务。
关于本问题的更多回答可点击原文查看:
