问题一:DataWorks数据分析模块,sql查询只能查dev环境吗?
DataWorks数据分析模块,sql查询只能查dev环境吗? 
参考回答:
不是的,在DataWorks中,数据分析模块允许您查询多个环境的数据。不过默认情况下,数据分析模块只能看到名为“default”的环境的数据,这通常是development (开发) 环境的数据。如果您想要查询其他环境的数据,可以在SQL查询语句中指定环境。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570896
问题二:DataWorks现在有一个mysql数据表,数据量非常大,数据会不断更新,有什么比较好的同步方式?
DataWorks现在有一个mysql数据表,数据量非常大,数据会不断更新,有什么比较好的同步方式?
参考回答:
建议是使用数据集成主站的 一次性全量 实时增量的任务https://help.aliyun.com/zh/dataworks/user-guide/synchronize-data-to-maxcompute-in-real-time?spm=a2c4g.11186623.0.0.5a5541a07WYN9r
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570894
问题三:DataWorks创建shell节点,调用python资源示例是什么?
DataWorks创建shell节点,调用python资源示例是什么?
参考回答:
shell 调用python,Q1:shell调用odpssql
A1:使用shell调用sql,请注意 accessid 、accesskey 和 endpoint 的替换,详细调用方法如下: /opt/taobao/tbdpapp/odpswrapper/odpsconsole/bin/odpscmd -u accessid -p accesskey --project=testproject --endpoint=http://service.odps.aliyun.com/api -e "sql"
Q2:shell调用独享资源组调用python3
A2:##@resource_reference{"python3.py"}
/home/tops/bin/python3 python3.py
(前提是已新建并提交python资源)
Q3:shell调用独享资源组调用python2
A3:##@resource_reference{"python2.py"}
python python2.py
(前提是已新建并提交python资源)
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570893
问题四:DataWorks能不能找技术测试一下,然后dataworks读取oss数据的例子?
DataWorks能不能找技术测试一下,日志服务投递到OSS(使用上图json格式),然后dataworks读取oss数据的例子? 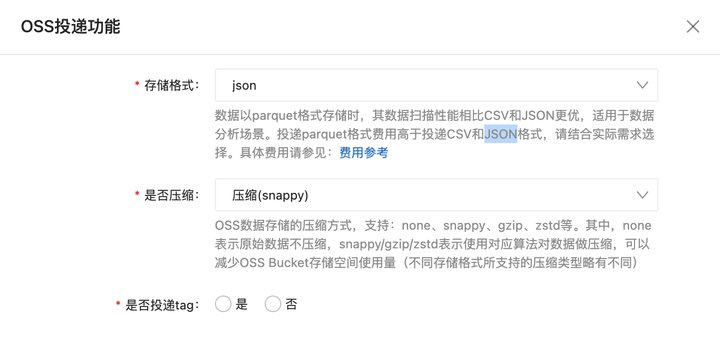
参考回答:
可以的,DataWorks 支持将日志服务投递到 OSS(Object Storage Service),然后 DataWorks 读取 OSS 数据。以下是一个简单的例子:
- 首先,确保你已经在 OSS 上创建了一个存储桶,并上传了 JSON 格式的日志文件。
- 在 DataWorks 控制台中,创建一个任务,选择 "数据处理" 类型。
- 在任务配置页面,选择 "OSS" 作为数据源,填写你的 OSS 存储桶名称、访问密钥等信息。
- 在任务配置页面,选择 "JSON" 作为数据格式,设置解析规则,以便 DataWorks 能够正确解析 JSON 格式的日志文件。
- 在任务配置页面,选择 "OSS" 作为目标数据源,填写你的 OSS 存储桶名称、访问密钥等信息。
- 在任务配置页面,选择 "JSON" 作为目标数据格式,设置转换规则,以便 DataWorks 能够将处理后的数据写入 OSS。
- 完成任务配置后,点击 "启动任务",DataWorks 将会开始处理日志文件,并将处理后的数据写入 OSS。
- 你可以通过 DataWorks 的控制台查看任务的运行状态和进度,以及处理后的数据。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570892
问题五:DataWorks还有一个问题,一直卡主?
DataWorks还有一个问题,一直卡主? 
参考回答:
DataWorks卡主可能是由于多种原因造成的。首先,您需要确定问题的根源:
- 如果是占用资源的任务导致的问题,您可以检查这些任务是否卡住或者运行缓慢。如果存在问题,建议先解决或暂停部分任务。等待这些任务执行完成后,资源会被释放,此时您可以重新启动您的任务。
- 如果DataWorks中的DataStudio页面加载正常,但交互反应很慢或卡顿,可能的原因包括数据量过大、浏览器和机器的负载能力不足等。解决方法可以是采样数据、只显示部分数据、缓存数据、分批传输以及降低报表的复杂度。
- 如果您在运维中心遇到周期任务相关问题,如节点未发布到生产环境或周期实例不存在,建议您检查工作空间的配置,确保调度已开启。
- 其他可能的原因包括输入节点配置错误、上游节点问题等。您可以检查输入节点的配置,如表名、SQL语句等,并确保有相应的权限。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570159
