知识蒸馏的概念出自2015年Hinton发表的Distilling the Knowledge in a Neural Network论文。在分类问题中,模型的输出层采用Softmax函数预测类别概率值。模型的目标是使输出概率值最高的类别尽可能接近于实际真实目标(Hard-target),它的训练过程是对真实值求极大似然。原始数据标签通常采用独热编码。这种情况下,所有负标签被平等对待,但这与实际并不一致,例如在动物图片分类时,如果图片的真实结果是猫,而负样本老虎和蛇与猫相近程度是不同的,显然老虎与猫更像;而当模型预测为蛇时,它比预测为老虎时更差。这说明不同负样本对应的输出概率应该有区别,也就是说不同的负样本对损失函数的贡献是不同的。而软目标(Soft Target)是通过改进Softmax层输出的类别概率,对每个类别都分配概率。
软目标(Soft Target)是在Softmax函数中增加了温度参数T:
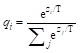
其中,zi是某个类别i的逻辑单元输出值,其值越大,说明结果属于这个类别的可能性就越大。T表示蒸馏的温度或强度,T的值越高,其输出概率分布越趋于平滑,就越放大负标签对应的信息,也就更加关注负标签。当T的值为1时,上式就变成了传统的Softmax函数。采用这种方式进行训练,对样本量要求更少,训练后的模型具有更好的泛化能力。
知识蒸馏的重点是对学生模型进行训练,其实现的过程如下:
1.通过传统方式训练比较复杂的教师模型。
2.训练学生模型,其损失分为蒸馏损失和学生损失两部分:前者借助教师模型的输出作为标签进行损失值计算,后者借助真实标签值计算损失,两个损失加权求和即可得到学生模型的总损失,从而对学生模型进行训练。
3.得到学生模型后,在推理阶段使用传统Softmax进行预测。
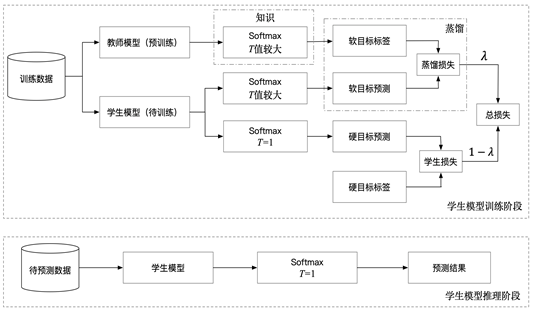
学生模型的训练和推理过程如图11-25所示。
在知识蒸馏之前先训练教师模型,然后基于改进的Softmax可得到教师模型已经学习的知识,并用其预测的结果作为标签与学生模型软目标输出的结果比较,计算蒸馏损失,使学生模型学习到正样本与负样本之间的关系信息。学生模型的损失除了蒸馏损失之外,还包括采用传统Softmax得到的硬目标损失,即设置T的值为1,将真实的样本标签与模型预测结果进行比较得到学生损失。