
docker安装部署FunASR
本指南详解FunASR在线语音识别服务的外网部署与内网迁移全流程:先在外网拉取Docker镜像、自动下载模型并启动服务(端口10095),验证成功后,将镜像和缓存模型打包导出;再于内网服务器导入镜像、解压模型、挂载运行,全程禁用SSL,支持热词与标点恢复,开箱即用。

覆盖16省方言的老人语音数据集!SeniorTalk:智源研究院开源全球首个超高龄老年人中文语音数据集
SeniorTalk是由智源研究院与南开大学联合推出的全球首个中文超高龄老年人对话语音数据集,包含202位75岁及以上老年人的55.53小时语音数据,涵盖16个省市的不同地域口音。

AI终于能听懂宝宝说话了!ChildMandarin:智源研究院开源的低幼儿童中文语音数据集,覆盖22省方言
ChildMandarin是由智源研究院与南开大学联合推出的开源语音数据集,包含41.25小时3-5岁儿童普通话语音数据,覆盖中国22个省级行政区,为儿童语音识别和语言发展研究提供高质量数据支持。

Dolphin:40语种+22方言!清华联合海天瑞声推出的语音识别大模型,识别精度超Whisper两代
Dolphin是清华大学与海天瑞声联合研发的语音识别大模型,支持40种东方语言和22种中文方言,采用CTC-Attention混合架构,词错率显著低于同类模型。

Text to Bark:让狗狗听懂人话!全球首个AI"狗语"生成器,137种狗狗口音任君挑选
ElevenLabs推出的Text to Bark是全球首个能将文本转换为逼真狗吠声的AI模型,支持多种犬种选择并适配智能家居设备,其核心技术基于深度神经网络训练。

PaddleSpeech:百度飞桨开源语音处理神器,识别合成翻译全搞定
PaddleSpeech是百度飞桨团队推出的开源语音处理工具包,集成语音识别、合成、翻译等核心技术,基于PaddlePaddle框架提供高性能解决方案。

EmotiVoice:网易开源AI语音合成黑科技,2000+音色情感可控
EmotiVoice是网易有道开源的多语言语音合成系统,支持中英文2000多种音色,通过提示词控制情感输出,提供Web界面和API接口,具备语音克隆等先进功能。

Oliva:语音RAG革命!开源多智能体秒解复杂搜索,实时对讲颠覆传统
Oliva是一款基于Langchain和Superlinked的开源语音RAG助手,通过实时语音交互在Qdrant向量数据库中进行语义搜索,支持多智能体协作处理复杂查询任务。

MoshiVis:语音视觉实时交互开源!7B模型秒懂图像,无障碍革命来袭
MoshiVis 是 Kyutai 推出的开源多模态语音模型,结合视觉与语音输入,支持实时交互,适用于无障碍应用、智能家居控制等多个场景。

Soundwave:语音对齐黑科技!开源模型秒解翻译问答,听懂情绪波动
Soundwave 是香港中文大学(深圳)开源的语音理解大模型,专注于语音与文本的智能对齐和理解,支持语音翻译、语音问答、情绪识别等功能,广泛应用于智能语音助手、语言学习等领域。

GPT-4o-mini-transcribe:OpenAI 推出实时语音秒转文本模型!高性价比每分钟0.003美元
GPT-4o-mini-transcribe 是 OpenAI 推出的语音转文本模型,基于 GPT-4o-mini 架构,采用知识蒸馏技术,适合在资源受限的设备上运行,具有高效、实时和高性价比的特点。
GPT-4o-Transcribe:OpenAI 推出高性能语音转文本模型!错误率暴降90%+方言通杀,Whisper当场退役
GPT-4o-Transcribe 是 OpenAI 推出的高性能语音转文本模型,支持多语言和方言,适用于复杂场景如呼叫中心和会议记录,定价为每分钟 0.006 美元。

GPT-4o mini TTS:OpenAI 推出轻量级文本转语音模型!情感操控+白菜价冲击配音圈
GPT-4o mini TTS 是 OpenAI 推出的轻量级文本转语音模型,支持多语言、多情感控制,适用于智能客服、教育学习、智能助手等多种场景。
URO-Bench:端到端语音对话模型评测黑马!多语言/多轮/副语言全维度一键开测
URO-Bench 是一款专为端到端语音对话模型设计的全面基准测试工具,涵盖多语言、多轮对话、副语言信息等多维度任务,帮助开发者全面评估模型性能。
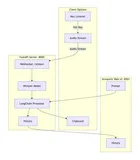
WhisperChain:开源 AI 实时语音转文字工具!自动消噪优化文本,效率翻倍
WhisperChain 是一款基于 Whisper.cpp 和 LangChain 的开源语音识别工具,能够实时将语音转换为文本,并自动清理和优化文本内容,适用于会议记录、写作辅助等多种场景。
Baichuan-Audio:端到端音频大模型,实时双语对话+语音生成
Baichuan-Audio 是百川智能推出的端到端音频大语言模型,支持无缝集成音频理解和生成功能,实现高质量、可控的实时中英双语对话。

OSUM:告别ASR单一功能,西工大开源的语音大模型会「读心」!识别+情感分析+年龄预测等8大任务1个模型全搞定
OSUM 是西北工业大学开发的开源语音理解模型,支持语音识别、情感分析、说话者性别分类等多种任务,基于 ASR+X 训练策略,具有高效和泛化能力强的特点。

Step-Audio:开源语音交互新标杆!这个国产AI能说方言会rap,1个模型搞定ASR+TTS+角色扮演
Step-Audio 是由阶跃星辰团队推出的开源语音交互模型,支持多语言、方言和情感表达,能够实现高质量的语音识别、对话和合成。本文将详细介绍其核心功能和技术原理。

Zonos:油管博主集体转粉!开源TTS神器Zonos爆火:克隆你的声音说5国语言,还能调喜怒哀乐
Zonos 是 ZyphraAI 推出的开源多语言 TTS 模型,支持语音克隆、情感控制和多种语言,适用于有声读物、虚拟助手等场景。

TIGER:清华突破性模型让AI「听觉」进化:参数量暴降94%,菜市场都能分离清晰人声
TIGER 是清华大学推出的轻量级语音分离模型,通过时频交叉建模和多尺度注意力机制,显著提升语音分离效果,同时降低参数量和计算量。

Hibiki:实时语音翻译模型打破语言交流障碍!支持将语音实时翻译成其他语言的语音或文本
Hibiki 是由 Kyutai Labs 开发的实时语音翻译模型,能够将一种语言的语音实时翻译成另一种语言的语音或文本,支持高保真度和低延迟。

FireRedASR:精准识别普通话、方言和歌曲歌词!小红书开源工业级自动语音识别模型
小红书开源的工业级自动语音识别模型,支持普通话、中文方言和英语,采用 Encoder-Adapter-LLM 和 AED 架构,实现 SOTA 性能。

SpeechGPT 2.0:复旦大学开源端到端 AI 实时语音交互模型,实现 200ms 以内延迟的实时交互
SpeechGPT 2.0 是复旦大学 OpenMOSS 团队推出的端到端实时语音交互模型,具备拟人口语化表达、低延迟响应和多情感控制等功能。

百聆:集成Deepseek API及语音技术的开源AI语音对话助手,实时交互延迟低至800ms
百聆是一款开源的AI语音对话助手,结合ASR、VAD、LLM和TTS技术,提供低延迟、高质量的语音对话体验,适用于边缘设备和低资源环境。

Kokoro-TTS:超轻量级文本转语音模型,支持生成多种语言和多种语音风格
Kokoro-TTS 是一款轻量级文本转语音模型,支持多语言和多语音风格生成,具备实时处理能力和低资源占用,适用于多种应用场景。

Weebo:支持多语言和实时语音交流的开源 AI 聊天机器人,回复具备语调、情感的语音
Weebo 是一款基于 Whisper Small、Llama 3.2 和 Kokoro-82M 技术的 AI 语音聊天机器人,支持实时语音交互和多语言对话,适用于个人助理、娱乐互动和教育辅导等多种场景。

三行代码实现实时语音转文本,支持自动断句和语音唤醒,用 RealtimeSTT 轻松创建高效语音 AI 助手
RealtimeSTT 是一款开源的实时语音转文本库,支持低延迟应用,具备语音活动检测、唤醒词激活等功能,适用于语音助手、实时字幕等场景。

TangoFlux:高速生成高质量音频,仅用3.7秒生成长达30秒的音频,支持文本到音频转换
TangoFlux 是由英伟达与新加坡科技设计大学联合开发的文本到音频生成模型,能够在3.7秒内生成30秒的高质量音频,支持文本到音频的直接转换和用户偏好优化。

3D-Speaker:阿里通义开源的多模态说话人识别项目,支持说话人识别、语种识别、多模态识别、说话人重叠检测和日志记录
3D-Speaker是阿里巴巴通义实验室推出的多模态说话人识别开源项目,结合声学、语义和视觉信息,提供高精度的说话人识别和语种识别功能。项目包含工业级模型、训练和推理代码,以及大规模多设备、多距离、多方言的数据集,适用于多种应用场景。

Freestyler:微软联合西工大和香港大学推出说唱音乐生成模型,支持控制生成的音色、风格和节奏等
Freestyler是由西北工业大学、微软和香港大学联合推出的说唱乐生成模型,能够根据歌词和伴奏直接生成说唱音乐。该模型基于语言模型生成语义标记,并通过条件流匹配模型和神经声码器生成高质量音频。Freestyler还推出了RapBank数据集,支持零样本音色控制和多种应用场景。

CosyVoice 2.0:阿里开源升级版语音生成大模型,支持多语言和跨语言语音合成,提升发音和音色等的准确性
CosyVoice 2.0 是阿里巴巴通义实验室推出的语音生成大模型升级版,通过有限标量量化技术和块感知因果流匹配模型,显著提升了发音准确性、音色一致性和音质,支持多语言和流式推理,适合实时语音合成场景。

ChatTTSPlus:开源文本转语音工具,支持语音克隆,是 ChatTTS 的扩展版本
ChatTTSPlus 是一个开源的文本转语音工具,是 ChatTTS 的扩展版本,支持语音克隆、TensorRT 加速和移动模型部署等功能,极大地提升了语音合成的性能和灵活性。

Clone-voice:开源的声音克隆工具,支持文本转语音或改变声音风格,支持16种语言
Clone-voice是一款开源的声音克隆工具,支持16种语言,能够将文本转换为语音或将一种声音风格转换为另一种。该工具基于深度学习技术,界面友好,操作简单,适用于多种应用场景,如视频制作、语言学习和广告配音等。

ClearerVoice-Studio:阿里通义开源的语音处理框架,提供语音增强、分离和说话人提取等功能
ClearerVoice-Studio 是阿里巴巴达摩院通义实验室开源的语音处理框架,集成了语音增强、分离和音视频说话人提取等功能。该框架基于复数域深度学习算法,能够有效消除背景噪声,保留语音清晰度,并提供先进的预训练模型和训练脚本,支持研究人员和开发者进行语音处理任务。

Fish Speech 1.5:Fish Audio 推出的零样本语音合成模型,支持13种语言
Fish Speech 1.5 是由 Fish Audio 推出的先进文本到语音(TTS)模型,支持13种语言,具备零样本和少样本语音合成能力,语音克隆延迟时间不到150毫秒。该模型基于深度学习技术如Transformer、VITS、VQVAE和GPT,具有高度准确性和快速合成能力,适用于多种应用场景。

Voice-Pro:开源AI音频处理工具,集成转录、翻译、TTS等一站式服务
Voice-Pro是一款开源的多功能音频处理工具,集成了语音转文字、文本转语音、实时翻译、YouTube视频下载和人声分离等多种功能。它支持超过100种语言,适用于教育、娱乐和商业等多个领域,为用户提供一站式的音频处理解决方案,极大地提高工作效率和音频处理的便捷性。
kws_util 下载不了
用户在树莓派上安装了一个语音唤醒环境,并使用了CTC语音唤醒模型“小云小云”。但在执行推理时遇到了错误。已尝试安装[kws_tuil],安装不成功,更换镜像后仍然安装失败,目前无法解决此问题。
使用开源的模型(像speech_sambert-hifigan_tts_zhida_zh-cn_16k)进行语音合成任务的推理时,推理速度太慢了,500字大约需要1分钟,为什么会这么慢
使用开源的模型(像speech_sambert-hifigan_tts_zhida_zh-cn_16k)进行语音合成任务的推理时,推理速度太慢了,500字大约需要1分钟,为什么会这么慢
同一个语音为什么识别结果还不一致的,有大佬知道原因吗(Paraformer语音识别-中文-通用-16k-离线-large-热词版)
模型speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404,在线体验同一个语音识别结果不一致(https://modelscope.cn/models/damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404/summary)
ModelScope官方镜像,CPU环境镜像(python3.8)pull不存在
在pullModelScope官方镜像时,一直pull失败,发现官方镜像应该没有推送,Python3.7的是有的







