









2026 爆火 OpenClaw 小龙虾 AI 部署教程|Win10/11 一键搭建本地 AI 数字员工,零代码零基础即用
OpenClaw(“小龙虾”)是2026年爆火的开源本地AI智能体,GitHub星标超28万。本教程专为小白设计,Win10/11一键部署,零代码、全图形化操作,10分钟即可启用AI数字员工,自动完成文件整理、Excel生成、浏览器操作等办公任务,数据全程本地运行,隐私安全无忧。(239字)

深度强化学习中SAC算法:数学原理、网络架构及其PyTorch实现
软演员-评论家算法(Soft Actor-Critic, SAC)是深度强化学习领域的重要进展,基于最大熵框架优化策略,在探索与利用之间实现动态平衡。SAC通过双Q网络设计和自适应温度参数,提升了训练稳定性和样本效率。本文详细解析了SAC的数学原理、网络架构及PyTorch实现,涵盖演员网络的动作采样与对数概率计算、评论家网络的Q值估计及其损失函数,并介绍了完整的SAC智能体实现流程。SAC在连续动作空间中表现出色,具有高样本效率和稳定的训练过程,适合实际应用场景。

国内可用的 Web Search API,可以平替Bing Search API
近期人们发现,AI对搜索引擎的需求远远超过人类。这个团队专为AI打造搜索引擎,上线仅60天就已被调用超30万次。
给AI模型“加外挂”:LoRA技术详解,让小白也能定制自己的大模型
LoRA是一种高效轻量的大模型微调技术,如同为万能咖啡机加装“智能香料盒”——不改动原模型(冻结参数),仅训练少量低秩矩阵(参数量降千倍),显著降低成本、保留通用能力,并支持插件式灵活部署。现已成为AI定制化普惠落地的核心方案。(239字)

DINOv3上手指南:改变视觉模型使用方式,一个模型搞定分割、检测、深度估计
DINOv3是Meta推出的自监督视觉模型,支持冻结主干、仅训练轻量任务头即可在分割、深度估计等任务上达到SOTA,极大降低训练成本。其密集特征质量优异,适用于遥感、工业检测等多领域,真正实现“一个模型走天下”。
跨境代购集运架构设计|Taocarts代购系统对接国际集运转运接口实践
在反向海淘、跨境代购业务体系中,采购是基础,集运转运是核心盈利环节。绝大多数跨境独立站的核心利润都来自代购集运、国际集运的服务费和物流差价,因此集运转运模块的架构设计和代码稳定性,直接决定平台的盈利能力和用户留存。我调研过大量开源代购源码和自研代购系统,发现很多项目将采购和物流模块混写在一起,代码耦合度极高,后续无法迭代集运规则、无法对接多渠道国际物流,基本不具备商用价值。
阐述:通过图片地址搜索淘宝相似商品教程
本篇详解淘宝图片搜索API(taobao.item_search_img):支持通过图片URL或imgid搜索相似商品,涵盖接口调用、标准返回结构、标题/价格/SKU/库存等关键字段解析及常见避坑指南,附辅助接口说明,开箱即用。

从 Flink 到 Doris 的实时数据写入实践 —— 基于 Flink CDC 构建更实时高效的数据集成链路
本文将深入解析 Flink-Doris-Connector 三大典型场景中的设计与实现,并结合 Flink CDC 详细介绍了整库同步的解决方案,助力构建更加高效、稳定的实时数据处理体系。

开发者急盼!Cisco Packet Tracer超详细下载安装教程,附中文版插件使用步骤!
Cisco Packet Tracer是思科推出的专业路由器模拟器,适用于学习IOS配置、故障排查及网络拓扑构建。支持多种协议(STP、OSPF等),含无线功能与安全设备。本文提供下载链接、安装教程及高级功能介绍,如复杂网络仿真、可视化调试、自动化脚本和行业场景模拟等,助你高效学习网络技术并启用中文语言包。



UV实战教程,我啥要从Anaconda切换到uv来管理包?
本文对比Anaconda“手动挡”与uv“全自动挡”环境管理:uv以“项目即环境”为核心,支持`uv init`一键初始化、自动下载Python、智能依赖管理(`uv add/sync/run`)及PyCharm无缝对接,大幅提升Python开发效率与协作体验。(239字)
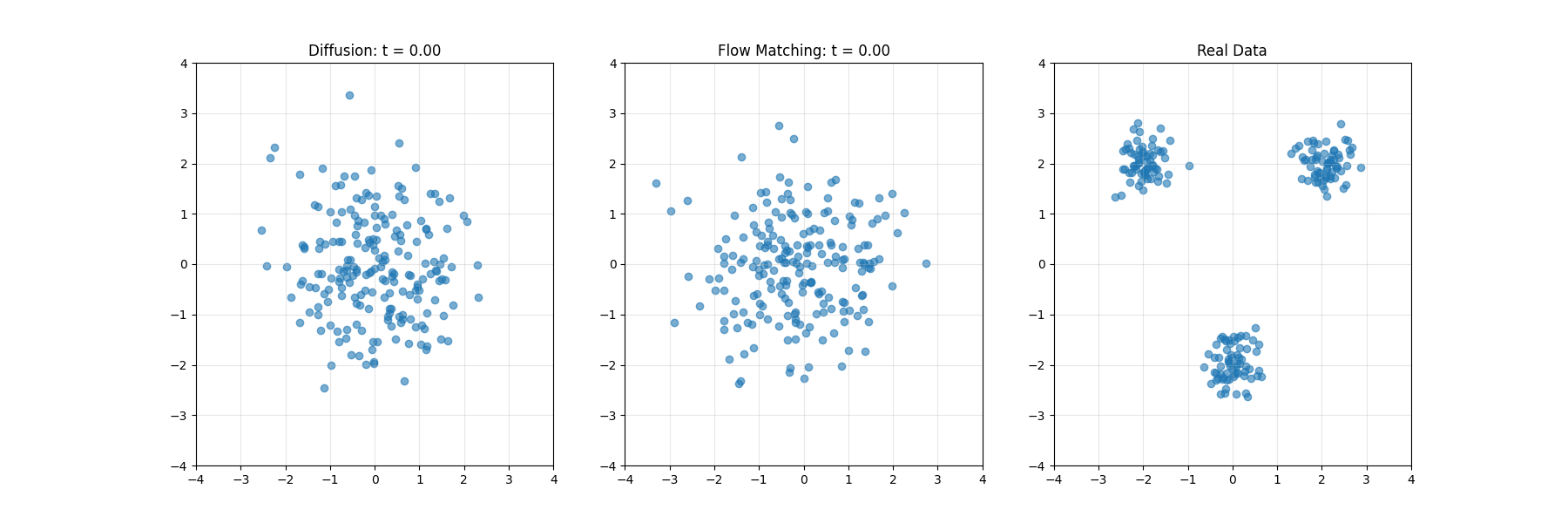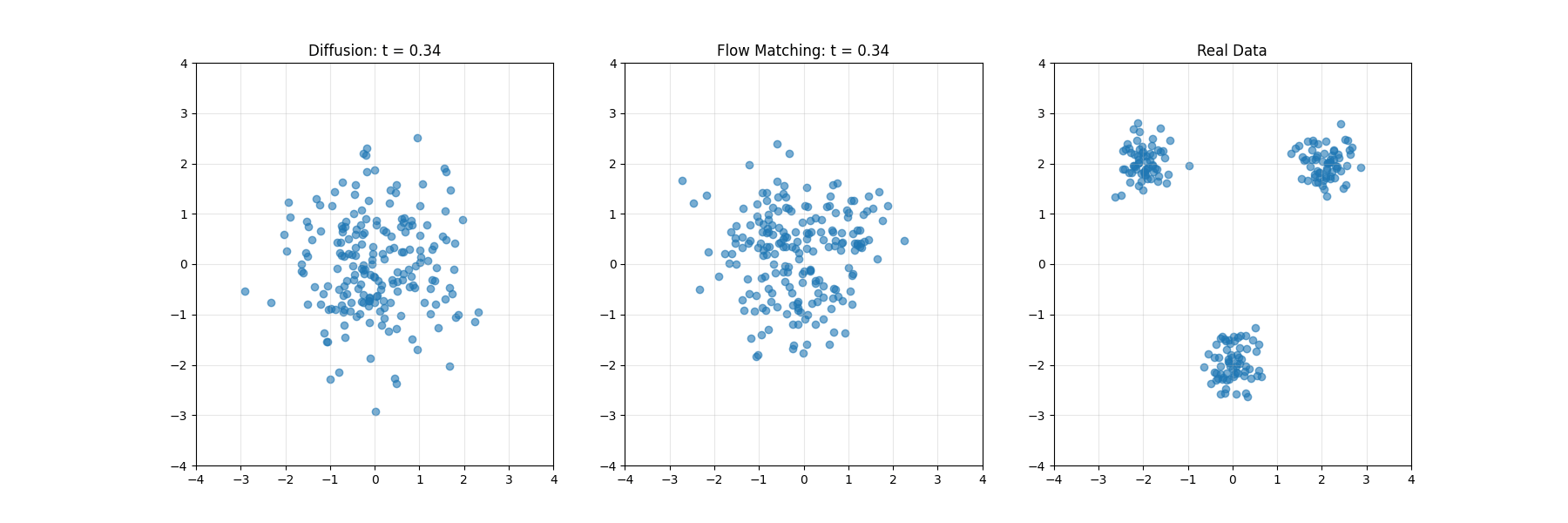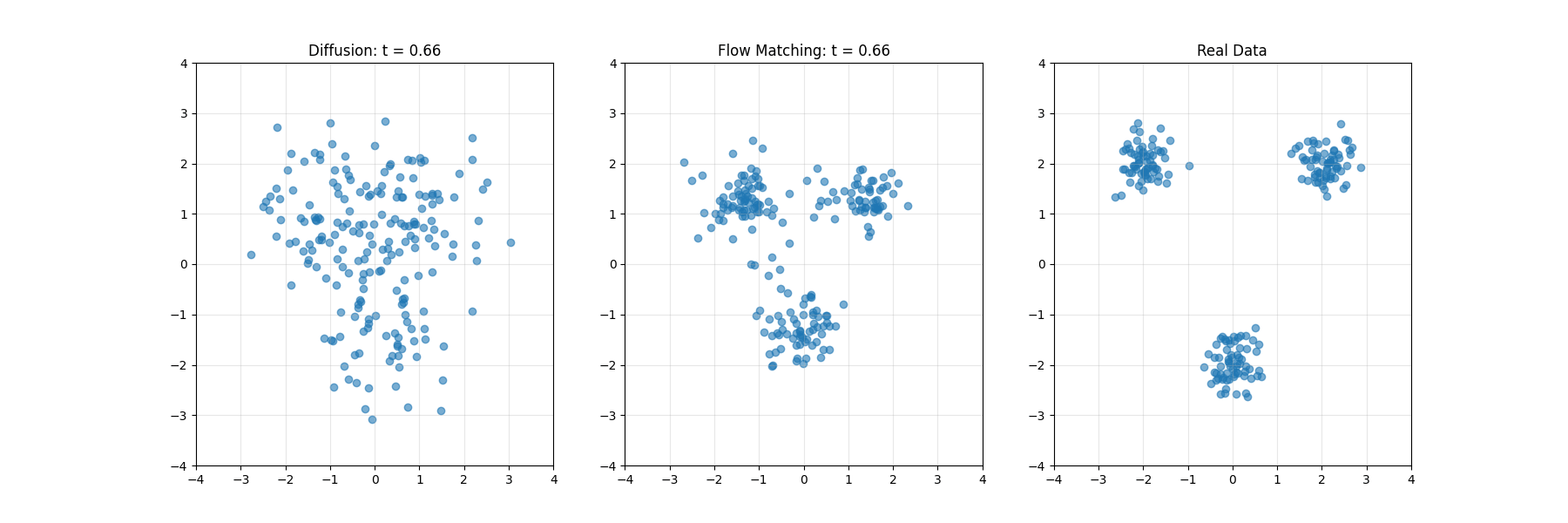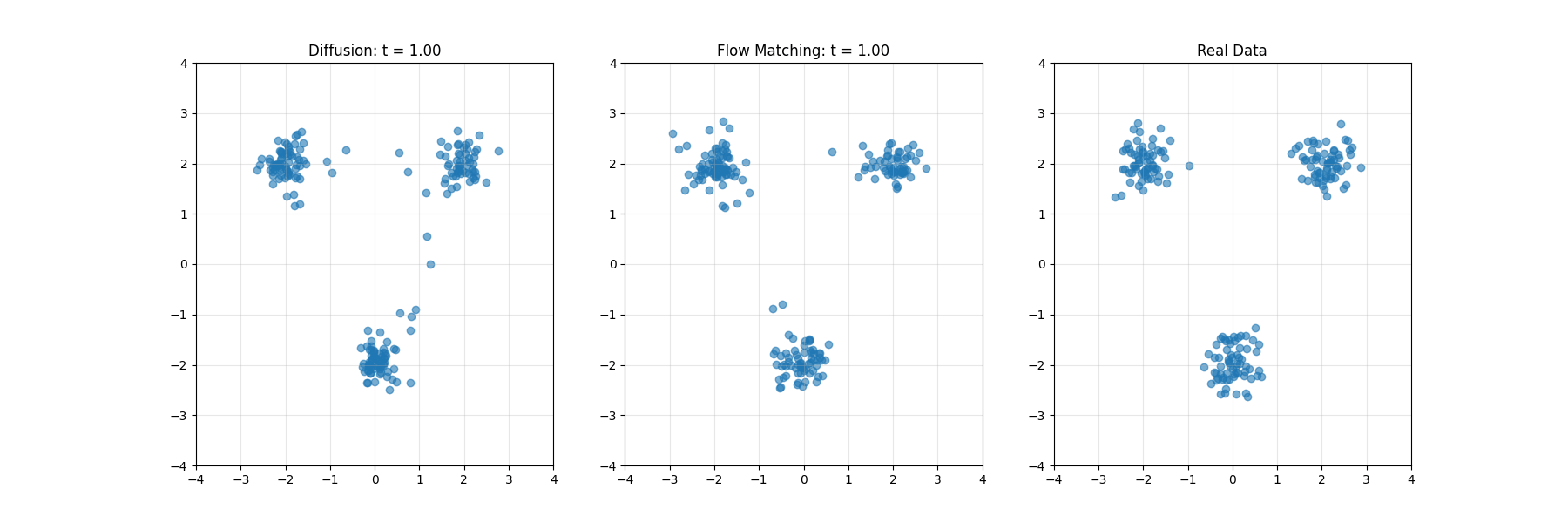
生成AI的两大范式:扩散模型与Flow Matching的理论基础与技术比较
本文系统对比了扩散模型与Flow Matching两种生成模型技术。扩散模型通过逐步添加噪声再逆转过程生成数据,类比为沙堡的侵蚀与重建;Flow Matching构建分布间连续路径的速度场,如同矢量导航系统。两者在数学原理、训练动态及应用上各有优劣:扩散模型适合复杂数据,Flow Matching采样效率更高。文章结合实例解析两者的差异与联系,并探讨其在图像、音频等领域的实际应用,为生成建模提供了全面视角。
让大模型“读懂”你的文档:RAG核心技术——文档切分完全指南
文档切分是智能问答系统成败的关键。本文深入解析RAG技术中分块(Chunking)的核心原理,涵盖五大切分策略:从基础的按句子、固定长度切分,到更智能的递归与语义切分。通过LangChain实战代码,手把手教你处理文本、Markdown、代码等多格式文档,并优化块大小、重叠与分隔符参数。提供人工抽样、模拟检索和端到端测试三大评估方法,助你构建高效精准的知识检索体系。

ClickHouse 应用剖析:设计理念、机制与实践
ClickHouse 是一款高性能的列式数据库管理系统,主要用于实时的大数据分析场景。它由俄罗斯 Yandex 公司开源于 2016 年,在网页日志分析、物联网监控、广告计费等领域有广泛应用。ClickHouse 通过列式存储、向量化执行和分布式架构,实现对海量数据的快速查询分析。本文将介绍 ClickHouse 的设计理念,以及在实际使用中如何处理数据删除更新、冷热数据分离等问题,并提供常见配置的调优建议和异常问题的处理方法。
抖音商品详情API 实战总结(技术复盘)
本文复盘抖音商品详情API(douyin.item_get)实战经验,涵盖鉴权、风控、token管理等关键问题,优化请求队列与重试机制。支持抖音小店/精选联盟商品结构化采集,返回基础信息、价格规格、多媒体、销售及评价五大模块,稳定高效,适配电商采集中台。
钉钉机器人接入 OpenClaw 全攻略教程
本文详解OpenClaw接入钉钉企业内部机器人的全流程:从创建应用、开通机器人能力、配置Stream模式(免公网域名),到获取Client ID/Secret并对接网关。涵盖前置准备、图文操作步骤及关键注意事项,助力高效实现业务信息实时同步与团队协作升级。
基于yolov8的深度学习水果识别检测系统
在农业现代化与消费升级背景下,基于YOLOv8的水果智能检测系统应运而生。该系统利用计算机视觉技术,实现高效、精准的水果识别与分级,广泛应用于生产、流通与零售环节,显著提升分拣效率、降低人工成本,并推动农业智能化发展。
小红书 API 接口使用指南:笔记详情数据接口的接入与使用
小红书是一款广受喜爱的生活方式分享社交平台,涵盖旅行、美食等领域。其API允许开发者批量获取笔记内容、图片链接及用户互动数据,助力内容分析与营销策略优化。要使用API,需先注册开发者账号并通过认证获取密钥;随后依据官方文档构建与发送HTTP请求,最后处理JSON格式响应数据。整个过程中,请务必遵循平台使用条款,尊重用户隐私权。
Ubuntu 报错:System has not been booted with systemd as init system (PID 1). Can‘t operate.
系统未使用 `systemd` 初始化导致错误。解决方法是通过 `apt` 安装。首先备份并更换`sources.list`,添加阿里云镜像源,然后更新源并以管理员权限运行 `apt-get install systemd -y` 和 `apt-get install systemctl -y` 安装所需组件。
如何搭建音视频知识库?从语音转文字到结构化整理的完整方案
本文分享用AI(如Ai好记+Obsidian)将B站、播客、YouTube等音视频高效转化为可检索知识库的实操方案:一键实现视频转笔记、语音转文字、视频总结、思维导图生成,并支持全文搜索与双向链接,15分钟搞定45分钟视频,大幅提升知识获取效率。

两节锂电池充电管理芯片BOM表电路图及关键元件布局要求整理
两节串联电池的电压特性(标称7.4V,满电8.4V,工作范围6V-8.4V) 典型应用场景:便携设备、蓝牙音箱、电动工具、无人机、矿灯等
小红书笔记详情数据获取实战:从笔记链接提取 ID 到解析详情
小红书笔记详情API可获取标题、正文、作者、互动数据、图文/视频资源及话题标签等结构化信息,支持自定义字段与评论拉取。适用于内容分析、竞品监控、营销优化与用户研究,HTTPS+JSON接口,Python调用便捷。(239字)
Vue项目实战入门:从0到1搭建电商商品列表页
本文以电商商品列表页为实战案例,详解Vue3项目从需求分析、环境搭建到核心功能实现的完整流程。涵盖组件化开发、Pinia状态管理、Vue Router路由跳转及Axios接口封装,助你掌握Vue工程化开发核心技能,快速构建可落地的前端应用。
Git仓库创建与代码上传指南
本教程介绍了将本地项目推送到远程Git仓库的完整流程,包括初始化本地仓库、添加和提交文件、创建远程仓库、关联远程地址及推送代码。同时,还提供了`.gitignore`配置、分支管理等可选步骤,并针对常见问题(如认证失败、分支不匹配、大文件处理及推送冲突)给出了解决方案。适合初学者快速上手Git版本控制。

相约深圳,全球征集|Flink Forward Asia 2026 演讲议题征集正式启动
Flink Forward Asia 2026将于6月26–27日首次落地深圳,聚焦实时计算与AI深度融合。面向全球征集议题(截止5月29日),涵盖实时AI、AI Agent、湖流一体等前沿方向。免费报名开启,共探下一代实时计算范式!
AI 十大论文精讲(三):RLHF 范式奠基 ——InstructGPT 如何让大模型 “听懂人话”
本文解读AI十大核心论文之二——《Training Language Models to Follow Instructions with Human Feedback》。该论文提出RLHF框架,通过“监督微调-奖励建模-强化学习”三步法,首次实现大模型与人类意图的有效对齐,推动GPT-3进化为更安全、可信的InstructGPT,奠定ChatGPT等后续模型的技术基石,开启大模型“从博学到好用”的新时代。
四张图片道清AI大模型的发展史(1943-2023)
现在最火的莫过于GPT了,也就是大规模语言模型(LLM)。“LLM” 是 “Large Language Model”(大语言模型)的简称,通常用来指代具有巨大规模参数和复杂架构的自然语言处理模型,例如像 GPT-3(Generative Pre-trained Transformer 3)这样的模型。这些模型在处理文本和语言任务方面表现出色,但其庞大的参数量和计算需求使得它们被称为大模型。当然也有一些自动生成图片的模型,但是影响力就不如GPT这么大了。

大数据&AI的16种可能,2020阿里云客户最佳实践合集下载
2020年9月18日下午13:00云栖大会正式发布 《大数据&AI的16种可能,2020阿里云客户最佳实践合集》
Win10/11 飞书联动 OpenClaw 远程办公自动化搭建教程
OpenClaw(小龙虾)v2.4.1 新增飞书机器人支持!无需公网,通过内网长连接即可实现飞书端自然语言指令下发,自动解析、拆解并执行本地AI自动化任务。Windows一键部署,可视化配置,适配Win10/11,开箱即用。(239字)
大模型RAG实战:从零搭建专属知识库问答助手
本文介绍如何用RAG技术从零搭建个人Python知识库问答助手,无需代码基础,低成本实现智能问答。涵盖数据准备、向量存储、检索生成全流程,附避坑技巧与优化方法,助力新手快速上手大模型应用。
机器学习:模型训练术语大扫盲——别再混淆Step、Epoch和Iter等
本文用通俗类比讲清机器学习核心术语:Epoch是完整训练一轮,Batch Size是每次训练的数据量,Step/Iter是每批数据处理及参数更新的最小单位。结合学习率、损失值、过拟合等概念,帮你快速掌握训练过程关键要点,打通术语任督二脉。(238字)
想让豆包在答案里提到你的官网?这三个步骤缺一不可
想让豆包引用你的官网?必须做好三步:一是将内容模块化、结构清晰,便于AI理解;二是通过专业资质、数据出处和结构化标记提升权威性;三是持续监测引用效果,优化内容策略。AI搜索时代,被“看见”才能赢得客户。
Escrcpy手机投屏工具!Scrcpy最全安装指南教程!
Escrcpy是一款开源免费的安卓投屏工具,支持Windows、macOS、Linux,无需Root,无广告。可实现低延迟(35-70ms)、高帧率(120fps)投屏,支持键鼠控制、文件互传、录屏截图,适用于办公、游戏、开发等场景。
Flink 基础详解:大数据处理的强大引擎
Apache Flink 是一个分布式流批一体化的开源平台,专为大规模数据处理设计。它支持实时流处理和批处理,具有高吞吐量、低延迟特性。Flink 提供统一的编程抽象,简化大数据应用开发,并在流处理方面表现卓越,广泛应用于实时监控、金融交易分析等场景。其架构包括 JobManager、TaskManager 和 Client,支持并行度、水位线、时间语义等基础属性。Flink 还提供了丰富的算子、状态管理和容错机制,如检查点和 Savepoint,确保作业的可靠性和一致性。此外,Flink 支持 SQL 查询和 CDC 功能,实现实时数据捕获与同步,广泛应用于数据仓库和实时数据分析领域。
1688商品详情API(1688.item_get)Python实战:构建B2B供应链数据中台
本文详解1688开放平台2.0官方API(`1688.item_get`)接入实战,涵盖HMAC-MD5签名算法、环境配置、Python完整代码及高频问题解决方案,助力企业构建稳定、合规的B2B供应链数据同步系统。
机器人训练纯仿真路线实现“零成本学习”,0真机数据,98%成功率!
2026年4月,某企业发布纯仿真训练具身模型,零真机数据实现近100% Zero-shot成功率,首次抓取率达98%。依托高保真仿真器学习物理规律,突破数据采集瓶颈,推动具身智能迈向“模型中心、软件定义、硬件重构”新范式。(239字)

Flink Agents:基于Apache Flink的事件驱动AI智能体框架
本文基于Apache Flink PMC成员宋辛童在Community Over Code Asia 2025的演讲,深入解析Flink Agents项目的技术背景、架构设计与应用场景。该项目聚焦事件驱动型AI智能体,结合Flink的实时处理能力,推动AI在工业场景中的工程化落地,涵盖智能运维、直播分析等典型应用,展现其在AI发展第四层次——智能体AI中的重要意义。
PAI-Rec的RealTimeU2IRecall 如何使用内置的i2i 缓存功能
`RealTimeU2IRecall` 内置物品级本地LRU缓存(I2ICacheSize/I2ICacheTime),对trigger item的相似商品列表进行内存缓存,命中即用、未命中批量查FeatureStore并写入负缓存,兼顾实时性与性能,显著降低下游查询压力。
解决 Win10 SmartScreen 拦截 OpenClaw 部署避坑教程
OpenClaw(小龙虾)是2026年爆火的开源本地AI智能体,专为Windows10 64位深度优化:纯小白友好、免命令行、解压即用;内置全部依赖,可视化操作;完美解决SmartScreen拦截、路径权限等Win10特有问题,10分钟轻松“养虾”!
深度回顾 | 阿里云携手 Elastic 定义 Agent 时代搜索新范式,解锁 Search AI 核心生产力
阿里云Elasticsearch升级为Agent Native搜索底座,推出Agentic Search、知识记忆湖、FalconSeek引擎及Hybrid Retrieval 2.0,实现面向AI智能体的毫秒级上下文检索,支持千亿级数据降本40%-70%,助力企业构建稳定、智能、低成本的下一代AI搜索基础设施。
微信智能体 OpenClaw 2.7.1 部署与故障排查全解
OpenClaw(小龙虾)是专注微信私域自动化的开源AI智能体,支持本地、云端、命令行三模式部署,简化微信接入,保障连接稳定与数据安全,适用于客服、运营、助理等场景,附一键装机包及完整部署指南。
关键词搜索京东商品列表 API 指南(2026 最新版)
本文详解京东商品搜索API(jd.item_search与jd.item_get)的技术接入,涵盖接口对比、参数配置、认证流程及Python实现,适用于电商选品、竞品分析与价格监控,助力开发者高效获取京东商品数据。
全面认识MCP:大模型连接真实世界的“USB-C接口”
MCP(模型上下文协议)是Anthropic推出的开放标准,被誉为AI时代的“USB-C”。它统一了大模型与工具、数据源的连接方式,简化集成,提升安全与扩展性,推动AI智能体实现复杂任务自动化,正重塑全球AI应用生态。
2025 最新史上最全 Java 面试题独家整理带详细答案及解析
本文从Java基础、面向对象、多线程与并发等方面详细解析常见面试题及答案,并结合实际应用帮助理解。内容涵盖基本数据类型、自动装箱拆箱、String类区别,面向对象三大特性(封装、继承、多态),线程创建与安全问题解决方法,以及集合框架如ArrayList与LinkedList的对比和HashMap工作原理。适合准备面试或深入学习Java的开发者参考。附代码获取链接:[点此下载](https://pan.quark.cn/s/14fcf913bae6)。

实时数仓Hologres V2.2发布,Serverless Computing降本20%
实时数仓Hologres V2.2发布,Serverless Computing降本20%

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
