
开源大数据平台 E-MapReduce
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。

活动报名 | Agentic Lakehouse Meetup · 北京站,从开源技术创新到多模态数据智能化
8月14日,阿里云在北京举办“Agentic Lakehouse”技术活动,聚焦开源大数据生态如何支撑AI Agent全生命周期。
【直播】StarRocks Stella 2.0 发布|具身行业训练数据圈选实战
EMR StarRocks Stella 2.2.0 多模态数据处理与检索能力重磅发布!揭秘文本、图片、视频的统一向量化与多模态理解,实战演示具身行业训练数据圈选全流程,从向量化标注到模型训练准备,助力智能驾驶、RAG等场景落地,理论+实操一站式掌握!
阿里云 EMR Serverless StarRocks(Stella 2.2.0)发布:多模态处理与分析闭环,内表与湖表统一检索
Stella 2.2 面向 AI 时代的数据基础设施,打通“多模态数据处理—向量化与理解—多路检索—分析消费”的完整闭环。无论数据沉淀在 Paimon 湖表,还是 StarRocks 存算分离内表,都可以在统一 SQL 入口下组合结构化分析、全文检索、向量检索与 AI Function,服务智能驾驶、具身智能、内容与商品理解、企业知识库和 RAG 等场景。

阿里云 EMR Serverless Spark 全托管 Ray 再进化:加速构建全模态数据处理新基建
阿里云 EMR Serverless Spark + Ray 双引擎构建全模态数据处理的新基建,通过极致内核优化和统一数据、算力底座,彻底打通了大数据工程与 AI 模型训练的割裂。结合 RayData、Daft、Data-Juicer 等多模态引擎,以及 CPFS、OSS 等高性能存储生态,阿里云正在为全球的 AI 开发者提供一套最具竞争力的数据新基建。
淘天集团基于 Fluss、Paimon 与 StarRocks 构建湖流一体数据链路
针对淘天集团秒级分析需求,构建基于Fluss、Paimon与StarRocks的湖流一体架构。Flusss承载秒级实时数据,Paimon沉淀分钟及历史数据,StarRocks通过Union Read统一查询,实现数据自动同步与口径一致。相比传统Kafka+Flink链路,新方案消除实时孤岛,降低80以上消费成本,提升50%开发效率。阿里云EMR Serverless StarRocks通过Native读取等增强,进一步简化运维,实现低成本、高性能的秒级实时OLAP分析。

EMR Serverless Spark AI Function 的双维降本实践
EMR Serverless Spark AI Function 已在智驾、具身智能等行业广泛落地。随着数据规模增长,如何控制由模型推理与Spark计算资源构成的双重成本愈发关键。本文深入解析并发控制等执行机制,并重点介绍两大降本手段:一是通过感知AI Function的查询优化减少模型调用量;二是利用Batch File异步批量推理降低单价并释放等待期资源。两者适用场景各异且可叠加使用,助力企业实现高效降本。
基于 StarRocks提效多模态工单标注与舆情研判的实践
针对消费金融多模态数据(语音、图片、文本)处理难、风险识别滞后及系统割裂痛点,方案基于阿里云 EMR Serverless StarRocks,利用 AI Function实现“推理即查询”。通过标准SQL直接在库内调用大模型,完成OSS文件映射、VLM/ASR识别、情感意图打标、向量生成及内外舆情交叉印证。该方案将非结构化数据转化为可计算资产,实现全量工单自动质检与实时高危预警。相比传统链路,显著降低工程复杂度与成本,提升合规效率,确保数据不出库,为金融风控提供高效、安全的多模态闭环解决方案。
EMR Serverless Spark PB级文本语义去重4倍加速的技术方案解读
针对大模型语料清洗中文本去重面临的性能瓶颈,某企业迁移至阿里云emr serverless spark后实现突破。新方案通过minhash-lsh内置函数将算法下沉引擎层,减少40%代码量;结合fusion engine向量化加速与shuffle优化,消除python udf跨进程开销并解决数据倾斜问题。实测去重性能提升4倍,任务耗时从天级降至小时级,且实现零shuffle失败与免运维。该实践验证了serverless架构在pb级数据预处理中的高效性与稳定性,显著加速模型迭代并降低计算成本。
分链路差异化设计的DSP准实时数仓|钛动科技基于阿里云实时计算 Flink 版 + DLF Paimon + EMR Serverless StarRocks 的实践
钛动科技针对DSP广告业务9.6PB数据规模及多场景SLA差异,将原StarRocks All-in-One架构重构为三条差异化链路:NRR链路利用DLF Paimon存储低频数据,降低60%成本;BT链路依托EMR Serverless StarRocks主键表,实现2分钟新鲜度及P99<5ms在线点查;CT链路负责数据归并。通过解耦实时点查与BI物化视图,该方案在保障故障隔离的同时,兼顾了低成本、高性能与高稳定性,实现了阿里云大数据产品栈的高效协同。
EMR Serverless Daft 如何简化多模态数据处理:视频抽帧、清洗、标注全流程与具身智能实践
阿里云 EMR Serverless Spark 引入 Ray 分布式计算框架与 Daft 高性能数据引擎,为用户提供了一套开箱即用、免运维且极致高效的多模态数据处理基础设施。
StarRocks x Fluss x Paimon 湖流一体方案:构建秒级响应、湖流一体的实时数据引擎
StarRocks x Fluss x Paimon 湖流一体方案通过将 Apache Fluss(面向分析场景的实时流存储)与 Apache Paimon(高性能湖格式表)深度融合,以 StarRocks 作为统一查询入口,构建了一套具备秒级新鲜度、十倍成本降低、一份数据一次查询的全新实时数据引擎。本文将介绍该方案的核心架构、技术优势、查询模式以及在阿里云 EMR Serverless StarRocks 上的产品化落地。

从数据湖到多模态湖仓-基于阿里云 EMR Serverless StarRocks 与 DLF Paimon 构建AI时代的统一分析检索架构
阿里云 EMR Serverless StarRocks 在统一数据、一致语义和系统级优化之上,构建了面向 AI Data、AI Agent 和多模态应用的下一代湖仓架构。
优路教育借助阿里云Flink+StarRocks+Paimon湖仓一体化构建职业教育业务全链路实时数据服务平台
优路教育大数据团队携手阿里云,基于实时计算 Flink + EMR Serverless StarRocks + DLF(Paimon) 构建了全链路实时数据服务平台,从学员画像、营销筛选到题库关联查询,实现了从“分钟级延迟”到“秒级响应”的质变,为成人教育行业的数据化转型提供了标杆实践。
OpenClaw + QQ 机器人!保姆级图文教程,一步到位
2026年OpenClaw+QQ机器人保姆级教程:7步完成接入——扫码登录QQ开放平台→创建机器人→复制AppID/AppSecret→OpenClaw安装插件→填参并启用→保存配置→发消息测试,零代码、全图文、20分钟速成!
1688商品详情API(1688.item_get)Python实战:构建B2B供应链数据中台
本文详解1688开放平台2.0官方API(`1688.item_get`)接入实战,涵盖HMAC-MD5签名算法、环境配置、Python完整代码及高频问题解决方案,助力企业构建稳定、合规的B2B供应链数据同步系统。
迅雷基于阿里云 EMR Serverless Spark 实现数仓资源效率与业务提升
迅雷基于阿里云 EMR Serverless Spark 实现数仓资源效率与业务提升,在迁移到 EMR Serverless Spark 之后,TCO 明显下降,平台按作业生命周期弹性拉起与回收,只为实际消耗付费;同时,托管化带来了稳定性与调度效率提升;更关键的是交付确定性提升,大作业整体可提速约 1 小时,报表链路从长尾波动变成更可控的出数节奏。
鹰角网络:EMR Serverless Spark 在《明日方舟》游戏业务的应用
鹰角网络为应对游戏业务高频活动带来的数据潮汐、资源弹性及稳定性需求,采用阿里云 EMR Serverless Spark 构建云原生大数据架构,迁移后实现计算加速50%,核心链路产出时间提前1.5h,研发效率和稳定性显著提升!
一套底座支撑多场景:高德地图基于 Paimon + StarRocks 轨迹服务实践
面对轨迹数据“高实时、高并发、长周期存储”的典型特征,高德团队以访问跨度为依据完成热/温/冷分层,并以 Apache Paimon + StarRocks 构建统一的数据底座,支撑轨迹数据的近实时写入与高性能查询。
EMR Serverless Spark 携手 PAI/百炼,开启“SQL 即 AI”的新篇章
EMR Serverless Spark 深度集成 AI Function 能力,并无缝对接 阿里云百炼与 阿里云人工智能平台 PAI 模型在线服务 PAI-EAS,定义了“SQL 即 AI”的新解决思路,数据分析师只需一行 SQL,即可直接调用世界顶尖的大模型。
诗悦游戏基于DLF与EMR StarRocks降本38%
诗悦网络(2014年成立)是千人规模的研运一体手游公司,代表作有《长安幻想》《永夜降临》等。为支撑PB级开放世界新游《望月》,其原半托管StarRocks数据平台面临高成本、难运维、稳定性差等痛点。阿里云以Serverless StarRocks+DLF Paimon数据湖方案实现存算分离、多租户隔离与全托管运维,总成本降38%,查询性能提升40%+,RPO=0,全面赋能实时/近实时/离线场景。

数仓-湖仓-湖流,人力家基于阿里云OpenLake架构演进与思考
人力家资深数据工程师石玉阳(Thorne),Flink-CDC Contributor,分享其公司湖仓一体实践:以Paimon为数据基座、StarRocks为OLAP引擎、Flink+Fluss实现湖流融合,打通离线/实时/增量计算,支持多模态与DATA+AI演进,构建开放、统一、可持续的大数据架构。(239字)
淘宝闪购基于阿里云 EMR Serverless Spark&Paimon的湖仓实践:超大规模下的特征生产&多维分析双提效
本文介绍阿里云 Serverless Spark + Paimon 在淘宝闪购大数据湖仓场景的应用。

有奖实践:EMR Serverless StarRocks × Serverless Spark x DLF 共探 TPC 极致性能
免费试用 EMR Serverless StarRocks 与 EMR Serverless Spark,体验“实时分析冠军”与“批处理之神”的极致性能表现!
大模型RAG实战:从零搭建专属知识库问答助手
本文介绍如何用RAG技术从零搭建个人Python知识库问答助手,无需代码基础,低成本实现智能问答。涵盖数据准备、向量存储、检索生成全流程,附避坑技巧与优化方法,助力新手快速上手大模型应用。
大模型微调技术入门:从核心概念到实战落地全攻略
大模型微调是通过特定数据优化预训练模型的技术,实现任务专属能力。全量微调精度高但成本大,LoRA/QLoRA等高效方法仅调部分参数,显存低、速度快,适合工业应用。广泛用于对话定制、领域知识注入、复杂推理与Agent升级。主流工具如LLaMA-Factory、Unsloth、Swift等简化流程,配合EvalScope评估,助力开发者低成本打造专属模型。

活动报名 | Apache Spark Meetup · 上海站,助力企业构建高效数据平台
2025年12月20日,上海 · 阿里巴巴徐汇滨江园区,Apache Spark Meetup 助力企业构建高效数据平台,欢迎报名!
0 基础建站?PageAdmin CMS 10 分钟搞定,源码免费拿!
PageAdmin CMS 为无编程基础用户提供高效建站方案。步骤包括:准备服务器、域名及源码;上传源码并配置数据库;通过安装向导完成基础设置;在后台创建栏目、填充内容;测试功能后上线。全程无需编程,简单操作即可搭建独立网站,支持后续维护与扩展。
EMR AI助手开启公测:用AI重塑大数据运维,更简单、更智能
EMR AI 助手开启公测,通过合理利用 EMR AI 助手的各项功能,可以快速查询资源信息、唤起相关操作、诊断组件异常、获取技术支持等,能帮您提升运维效率和操作体验。
EMR StarRocks Stella 内核正式发布,登顶 TPC 榜单全球第一
EMR Serverless StarRocks 重磅发布全新企业级版本内核 Stella (StarRocks Efficient and Lightening-fast Lakehouse),完全兼容开源 StarRocks,为用户提供企业级的产品功能、卓越的性能及稳定性保障。
QuickSSO 与 ECreator 实操应用案例手册
本手册以企业 CRM 搭建与统一身份认证接入为场景,先说明环境要求与模块确认,再讲 ECreator 建 CRM 的应用、数据模型、页面及流程设计,后述 QuickSSO 认证中心配置、权限分配与测试,还提及效果验证与常见问题排查,助用户掌握二者协同应用。
StarRocks+Paimon 落地阿里日志采集:万亿级实时数据秒级查询
A+流量分析平台是阿里集团统一的全域流量数据分析平台,致力于通过埋点、采集、计算构建流量数据闭环,助力业务提升流量转化。面对万亿级日志数据带来的写入与查询挑战,平台采用Flink+Paimon+StarRocks技术方案,实现高吞吐写入与秒级查询,优化存储成本与扩展性,提升日志分析效率。
立马耀:通过阿里云 Serverless Spark 和 Milvus 构建高效向量检索系统,驱动个性化推荐业务
蝉妈妈旗下蝉选通过迁移到阿里云 Serverless Spark 及 Milvus,解决传统架构性能瓶颈与运维复杂性问题。新方案实现离线任务耗时减少40%、失败率降80%,Milvus 向量检索成本降低75%,支持更大规模数据处理,查询响应提速。

鹰角网络:EMR Serverless Spark 在《明日方舟》游戏业务的应用
鹰角网络为应对游戏业务高频活动带来的数据潮汐、资源弹性及稳定性需求,采用阿里云 EMR Serverless Spark 替代原有架构。迁移后实现研发效率提升,支持业务快速发展、计算效率提升,增强SLA保障,稳定性提升,降低运维成本,并支撑全球化数据架构部署。
千万级数据秒级响应!碧桂园基于 EMR Serverless StarRocks 升级存算分离架构实践
碧桂园服务通过引入 EMR Serverless StarRocks 存算分离架构,解决了海量数据处理中的资源利用率低、并发能力不足等问题,显著降低了硬件和运维成本。实时查询性能提升8倍,查询出错率减少30倍,集群数据 SLA 达99.99%。此次技术升级不仅优化了用户体验,还结合AI打造了“一看”和“—问”智能场景助力精准决策与风险预测。
百观科技基于阿里云 EMR 的数据湖实践分享
百观科技为应对海量复杂数据处理的算力与成本挑战,基于阿里云 EMR 构建数据湖。EMR 依托高可用的 OSS 存储、开箱即用的 Hadoop/Spark/Iceberg 等开源技术生态及弹性调度,实现数据接入、清洗、聚合与分析全流程。通过 DLF 与 Iceberg 的优化、阶梯式弹性调度(资源利用率提升至70%)及倚天 ARM 机型搭配 EMR Trino 方案,兼顾性能与成本,支撑数据分析需求,降低算力成本。
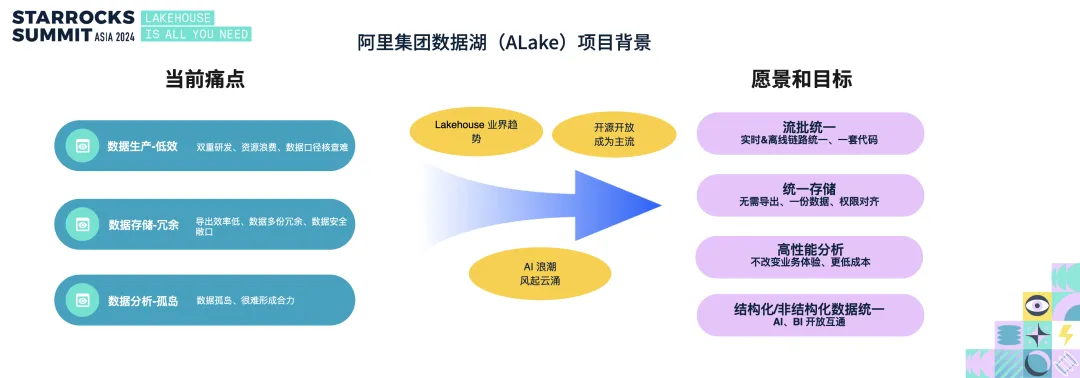
StarRocks + Paimon 在阿里集团 Lakehouse 的探索与实践
阿里集团在推进湖仓一体化建设过程中,依托 StarRocks 强大的 OLAP 查询能力与 Paimon 的高效数据入湖特性,实现了流批一体、存储成本大幅下降、查询性能数倍提升的显著成效: A+ 业务借助 Paimon 的准实时入湖,显著降低了存储成本,并引入 StarRocks 提升查询性能。升级后,数据时效提前60分钟,开发效率提升50%;JSON列化存储减少50%,查询性能提升最高达10倍;OLAP分析中,非JOIN查询快1倍,JOIN查询快5倍。 饿了么升级为准实时Lakehouse架构后,在时效性仅损失1-5分钟的前提下,实现Flink资源缩减、StarRocks查询性能提升(仅5%
美的楼宇科技基于阿里云 EMR Serverless Spark 构建 LakeHouse 湖仓数据平台
美的楼宇科技基于阿里云 EMR Serverless Spark 建设 IoT 数据平台,实现了数据与 AI 技术的有效融合,解决了美的楼宇科技设备数据量庞大且持续增长、数据半结构化、数据价值缺乏深度挖掘的痛点问题。并结合 EMR Serverless StarRocks 搭建了 Lakehouse 平台,最终实现不同场景下整体性能提升50%以上,同时综合成本下降30%。
阿里云 EMR Serverless Spark 在微财机器学习场景下的应用
面对机器学习场景下的训练瓶颈,微财选择基于阿里云 EMR Serverless Spark 建立数据平台。通过 EMR Serverless Spark,微财突破了单机训练使用的数据规模瓶颈,大幅提升了训练效率,解决了存算分离架构下 Shuffle 稳定性和性能困扰,为智能风控等业务提供了强有力的技术支撑。
阿里云 EMR 发布托管弹性伸缩功能,支持自动调整集群大小,最高降本60%
阿里云开源大数据平台 E-MapReduce 重磅推出托管弹性伸缩功能,基于 EMR 托管弹性伸缩功能,您可以指定集群的最小和最大计算限制,EMR 会持续对与集群上运行的工作负载相关的关键指标进行采样,自动调整集群大小,以获得最佳性能和资源利用率。
关于商品详情 API 接口 JSON 格式返回数据解析的示例
本文介绍商品详情API接口返回的JSON数据解析。最外层为`product`对象,包含商品基本信息(如id、name、price)、分类信息(category)、图片(images)、属性(attributes)、用户评价(reviews)、库存(stock)和卖家信息(seller)。每个字段详细描述了商品的不同方面,帮助开发者准确提取和展示数据。具体结构和字段含义需结合实际业务需求和API文档理解。
EMR管控平台全面升级:智能化助力客户实现在离线混部和降本增效
本次介绍EMR开源大数据平台2.0的最新特性,基于微服务架构,提供更稳定高效的服务。平台升级主要体现在智能化和Serverless两个方面。智能化功能利用大语言模型提升运维效率,推出一键诊断和根因分析,缩短问题定位时间。全托管弹性伸缩根据业务动态自动调整资源,提高资源利用率。即将推出的EMR on ACS产品形态支持离在线业务混部,进一步优化资源使用,帮助用户实现降本增效。
拍立淘API是基于图像识别技术的服务接口,支持淘宝、1688和义乌购平台。
拍立淘API是基于图像识别技术的服务接口,支持淘宝、1688和义乌购平台。用户上传图片后,系统能快速匹配相似商品,提供精准搜索结果,并根据用户历史推荐个性化商品,简化购物流程。开发者需注册账号并获取API Key,授权权限后调用接口,返回商品详细信息如ID、标题、价格等。使用时需遵守频率限制,确保图片质量,保障数据安全。
有奖实践,基于EMR StarRocks实现游戏玩家画像和行为分析
阿里云EMR-StarRocks联合镜舟科技,基于EMR-StarRocks实现游戏实时湖仓分析,免费试用物化视图、Paimon写入查询等新能力,前45位赢取StarRocks定制T恤、Lamy钢笔,小米充电宝,阿里云拍拍灯等活动礼品,前500位均可获得创意马克杯。

基于OpenLake的Flink+Paimon+EMR StarRocks流式湖仓分析
阿里云OpenLake解决方案建立在开放可控的OpenLake湖仓之上,提供大数据搜索与AI一体化服务。通过元数据管理平台DLF管理结构化、半结构化和非结构化数据,提供湖仓数据表和文件的安全访问及IO加速,并支持大数据、搜索和AI多引擎对接。本文为您介绍以Flink作为Openlake方案的核心计算引擎,通过流式数据湖仓Paimon(使用DLF 2.0存储)和EMR StarRocks搭建流式湖仓。
【赵渝强老师】部署Hadoop的本地模式
本文介绍了Hadoop的目录结构及本地模式部署方法,包括解压安装、设置环境变量、配置Hadoop参数等步骤,并通过一个简单的WordCount程序示例,演示了如何在本地模式下运行MapReduce任务。
降本60% ,阿里云 EMR StarRocks 全新发布存算分离版本
阿里云 EMR Serverless StarRocks 现已推出全新存算分离版本,该版本不仅基于开源 StarRocks 进行了全面优化,实现了存储与计算解耦架构,还在性能、弹性伸缩以及多计算组隔离能力方面取得了显著进展。




