作者:
邹佳华 碧桂园服务大数据运维高级工程师
田明 碧桂园服务数据开发高级工程师
指导人:
杜鹏 部门总经理
背景介绍
公司介绍
碧桂园服务(以下简称“碧服”)是中国领先的综合物业管理服务运营商,以“服务成就美好生活”为使命,业务覆盖住宅、商业物业、写字楼、产业园、学校、公园、公建等多种业态。作为行业领先的综合服务集团,碧服每天要为8000多个社区的各类建筑和设备提供保障服务,设备监控、业户需求、物业运维等海量数据就像洪流涌入到数据湖仓。面对日益复杂的业务需求和海量数据挑战,碧服亟需引入一个具备卓越的实时处理和数据加速能力、高效且稳定的数据引擎,从而实现数据高效管理,支撑企业决策和服务优化。
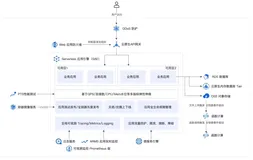
碧服架构概览

上图是碧服 OLAP 运行架构概览,底层存储层包括 MaxCompute(用于离线存储)和 Kafka(用于实时数据),一些业务系统的多维数据清洗转成非结构化数据存储在OSS,还有部分外表数据存储在 MySQL。在存储层之上,处理层由 MaxCompute 承担批处理,Flink 负责流处理,分析层大部分由 StarRocks 承担,极少部分查询用到 ClickHouse,最上层则是各种应用场景。

碧服早期使用关系型数据库和 Elasticsearch 进行数据分析,这些组件适用于数据规模小,场景简单的分析任务。随着公司数据量持续增长,数据分析场景变得复杂多样,传统分析引擎难以满足数据业务持续增长的需求。在提升大数据分析性能的道路上,碧服使用过其他 OLAP 引擎作为实时数仓,开源的 ClickHouse 作为联邦查询引擎。2022年引进了开源分析型数据库 StarRocks,通过利用 StarRocks 的多表连结(Join)的能力,提升了数据分析效率。截至目前 StarRocks 是公司最主要的数据分析引擎。
为什么选择阿里云 EMR Serverless StarRocks
存算一体架构痛点

在数字化转型初期,碧服采用了传统的存算一体架构,StarRocks 作为一款 MPP 架构的分析型数据库,能够支撑 PB 级别的数据量,拥有灵活的建模方式,可以通过向量化引擎、物化视图、稀疏索引等优化手段构建极速统一的分析层数据存储系统。但随着业务的快速发展,数据规模的指数级增长让存算一体架构逐渐暴露出诸多痛点:
- 节点扩缩容困难
存储与计算无法进行解耦,必须同步扩缩容(Scale Up)。伴随着副本的迁移,有时网络的抖动或是数据更新都会影响副本均衡,而数据均衡也会影响查询性能。
- 资源利用率低
多套集群独立部署,资源无法共享实现充分利用,各个集群无法设置弹性资源,实现低峰减容,高峰扩容。
- 并发能力低
在业务高峰期,由于单点并发能力的限制,数据写入伴随着副本创建和小文件 compact 影响到查询性能,从而影响到用户体验。
- 数据SLA风险增高
随着数据规模、OLAP 服务与应用需求的不断扩大,复杂查询和高频写入场景占比日益升高,在业务高峰期间,报表查询和数据服务查询延迟“突刺”不断增加,导致数据服务质量SLA风险增高。
EMR Serverless StarRocks 存算分离架构优势

为了解决以上困局,从并发能力、资源利用率和数仓融合能力等方面对存算分离和存算一体的架构进行了调研,EMR Serverless StarRocks 存算分离架构,不仅基于开源 StarRocks 进行了全面优化,实现了存储与计算解耦架构,还在性能、弹性伸缩以及多计算组隔离能力方面取得了显著进展。
EMR Serverless StarRocks 存算分离架构将数据存储和计算分离,使得存储和计算资源可以独立扩展和管理。存储层采用 OSS 存储系统,能够轻松应对大规模数据的存储需求,并且具有高可靠性和高扩展性;计算层则可以根据业务需求灵活调整计算资源,提高资源利用率,整体存储成本和计算成本降低60%以上,同时保持了与传统存算一体架构相媲美的内表处理速度。为了进一步提升查询性能,计算节点(CN)增加了加速缓存盘,将热数据存储于计算节点的缓存盘中,显著提升了查询效率。此外,EMR Serverless StarRocks 存算分离架构支持高度灵活的弹性伸缩机制,能够根据实际业务需求动态调整资源,确保高效利用的同时降低了运营成本。更重要的是,借助多计算组功能,用户可以在同一实例内部署配置多个独立的计算资源组,从而更好地满足不同工作负载的需求,并保证了各组间工作的互不影响,进一步提升了系统的灵活性和安全性。另外,从3.3 版本(公司使用版本)开始还加强了湖仓融合能力。
技术方案设计
从存算一体到存算分离的架构迁移是一场难度极高的"数据大迁徙"。在迁移升级前,碧服技术团队对存算一体的集群资源使用情况进行梳理统计,根据原来资源使用量进行评估之后,构建了一套缓存盘为1T,多个 CN 节点的 StarRocks 存算分离集群。基于现有业务使用情况进行全面评估,制定了详细的迁移计划,明确了迁移的目标、步骤、时间节点和风险应对措施,对多套集群进行迁移升级和资源整合,总共涉及的业务报表有 200+,表数量 1400+,集成任务有 1100+。


迁移实施
为了避免迁移切换对用户体验造成影响,实现业务查询无感,采取“数据双写,逐步切换”的迁移思路。整个迁移过程要求业务无感,给碧服技术团队很大的挑战。因此,前期碧服技术团队做了充分的风险评估和测试,根据业务报表优先级进行排期,稳步推进业务报表切换。通过调整告警阈值,提升监控的灵敏度,关注存算分离集群资源使用情况和健康状况,将影响集群的稳定因素提前解决。以下是迁移总体路线图:

数据对齐&业务切换
在新集群创建 Catalog 连接旧集群,数据校验入口在新集群,提升了数据校验效率。为了实现无缝切换和用户查询无感,碧服技术团队在夜间 10 点进行切换,切换过程中涉及到数据校验,报表查询结果比对等工作,充分验证之后报表查询切换到新集群。有些未知因素可能会导致查询异常,为了保证能够及时回退,保持数据“双写”,以便出现异常时能够及时回切到旧集群。所有业务报表在保证原报表查询稳定的情况下,逐一完成了迁移切换工作。

迁移后的收益
经过数月的努力,碧服成功完成了存算分离架构的迁移升级。这次架构升级不仅解决了原有的技术痛点,更带来了显著的业务价值提升:
- 成本降低
迁移升级到存算分离架构,硬件资源成本大幅度降低。计算资源可以根据业务需求灵活调整,避免了资源的浪费,运维成本也相应降低。同时,存算分离计算节点只挂载数据缓存盘,数据块以单副本的形式存放在OSS对象存储中,总体存储成本也是下降了不少。
- 用户体验提升
原集群存在版本bug和读写资源竞争的缺点,在业务高峰期经常会出现页面加载缓慢,甚至页面加载失败的情况,优化后实时查询P99快了8倍,在业务高峰时期,系统的性能也得到了有效保障。由于数据写入效率高,查询平均出错率相较于存算一体减少了30倍,集群数据SLA提升到99.99%。例如:一看、企微数据看板、大运营看板及相关数据服务的响应速度均提升了3到5倍,整体的报表性能和体验有极大提升。

总结与规划
碧服这次的存算分离实践不仅仅是一项技术升级,更是一场数字化转型的战略跃迁。依托海量大数据,碧服结合AI和大模型,打造了“一看”和“一问”的智能场景。通过“看现在”,系统能实时捕捉业务状态,为企业决策提供精准数据支持,从而助力精益运营、提升效率和降低成本;而“知未来”则赋予企业商业洞察力,既能精准挖掘市场机会和业户需求,又能提前预测设备故障,自动发起维保工单,有效规避风险,从而大幅提升用户满意度。

迁移升级之后,持续的监控和优化是提升集群读写性能和保障稳定性的重要手段。下一步计划,碧服技术团队将进行参数,入数方式、表模型改造、查询语句等方面进行优化,根据场景需求进行资源隔离和设置弹性伸缩资源等。同时,利用 EMR Serverless StarRocks 湖仓一体的融合能力,结合物业大数据场景需求,实现技术落地。