
一.引言
本文介绍 Flink 的主要数据形式: DataStream,即流式数据的常用转换函数,通过 Transformation 可以将一个 DataStream 转换为新的 DataStream。
Tips:
下述介绍 demo 均采用如下 case class 作为数据类型,并通过自定义的 SourceFromCycle 函数每s 生成10个元素。特别注意 Source 函数还增加了 isWait 参数,控制该 Source 是否延迟 3s 生成数据。全局 env 为 StreamExecutionEnvironment。
case class Data(num: Int) // 每s生成一批数据 class SourceFromCycle(isWait: Boolean = false) extends RichSourceFunction[Data] { private var isRunning = true var start = 0 override def run(ctx: SourceFunction.SourceContext[Data]): Unit = { if (isWait) { TimeUnit.SECONDS.sleep(3) } while (isRunning) { (start until (start + 100)).foreach(num => { ctx.collect(Data(num)) if (num % 10 == 0) { TimeUnit.SECONDS.sleep(1) } }) start += 100 } } override def cancel(): Unit = { isRunning = false } } val env = StreamExecutionEnvironment.getExecutionEnvironment

二.常用 Transformation
1.Map - DataStream → DataStream
处理单个元素并返回单个元素。mapDemo 针对每个元素返回该 num 与 num+1,最终 sink 保存至文件。
def mapDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(1) val transformationStream = dataStream.map(data => { (data.num, data.num + 1) }) val output = "./output/" transformationStream.writeAsText(output, WriteMode.OVERWRITE) }


 编辑
编辑
2.Filter - DataStream → DataStream
对每个元素计算布尔函数,并保留该函数返回true的元素。filterDemo 仅保留1开头的数据。
def filterDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(1) dataStream.filter(data => { data.num.toString.startsWith("1") }).print() }


 编辑
编辑
3.FlatMap - DataStream → DataStream
通过一个元素生成0个、一个或多个元素。FlatMapDemo 返回自身与自身+1的 tuple。0 返回 0,1、1返回1,2 ... 以此类推。
def flatMapDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(1) dataStream.flatMap(data => { val info = ArrayBuffer[Data]() info.append(data) info.append(Data(data.num + 1)) info.iterator }).print() }

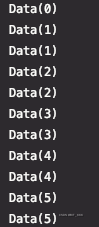
 编辑
编辑
4.KeyBy - DataStream → KeyedStream
将流划分为不相连的分区,具有相同 key 的记录会被分配到相同的分区, keyBy() 内部是通过 Hash 分区实现的,可以通过不同的方法指定 key。下面使用每个数字的第一位对数字进行分区,可以看到对应 TaskId 下的数字都有相同的第一位。Tips: 获取 TaskId 通过 RuntimeContext 得到。
def keyByDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(5) dataStream.keyBy(data => { data.num.toString.slice(0, 1) }).process(new ProcessFunction[Data, (Int, Int)] { override def processElement(i: Data, context: ProcessFunction[Data, (Int, Int)]#Context, collector: Collector[(Int, Int)]): Unit = { val taskId = getRuntimeContext.getIndexOfThisSubtask collector.collect((taskId, i.num)) } }).print() }

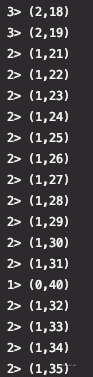
 编辑
编辑
5.Reduce - KeyedStream → DataStream
键控数据流上的“滚动”减记。将当前元素与最近的简化值组合,并发出新值。下述 reduce 聚合将相同开头的数字结果进行累加。由于是动态累加,所以产出的数字没有规律。
def reduceDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(5) dataStream.keyBy(data => { data.num.toString.slice(0, 1) }).reduce(new ReduceFunction[Data] { override def reduce(o1: Data, o2: Data): Data = { Data(o1.num + o2.num) } }).print() }


 编辑
编辑
6.Window - KeyedStream → WindowedStream
Windows可以在已经分区的KeyedStreams上定义。Windows根据某些特征(例如,在最近5秒内到达的数据)对每个键中的数据进行分组。根据类型不同有滑动窗口与滚动窗口,下述 Demo 采用第一位数字分区,并生成5s间隔的窗口,窗口内包含5s内全部的数据。
def windowDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(5) dataStream.keyBy(data => { data.num.toString.slice(0, 1) }).window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .process(new ProcessWindowFunction[Data, String, String, TimeWindow] { override def process(key: String, context: Context, elements: Iterable[Data], out: Collector[String]): Unit = { val log = key + "\t" + elements.toArray.mkString(",") out.collect(log) } }) .print() }


 编辑
编辑
7.WindowAll - DataStream → AllWindowedStream
Windows可以在常规的数据流上定义。Windows根据某些特征(例如,在最近5秒内到达的数据)对所有流事件进行分组。Window 和 WindowAll 都是聚合指定时间内的数据,差别在于 Window 聚合每个分区的数据,即将相同 key 的数据聚合,所以会生成 HashNum 个 window,而 WindowAll 汇聚规定时间内的全部数据,不区分 key,所以其并行度只有1。由于 WindowAll 不区分分区,所以看到 windowAll 得到的窗口中包含的数据很多,而 window 得到的窗口中数据少,但都具有相同的 key 即首数字相同。
def windowAllDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(5) dataStream.keyBy(data => { data.num.toString.slice(0, 1) }).windowAll(TumblingProcessingTimeWindows.of(Time.seconds(5))) .process(new ProcessAllWindowFunction[Data, String, TimeWindow] { override def process(context: Context, elements: Iterable[Data], out: Collector[String]): Unit = { val log = elements.toArray.map(_.num).mkString(",") out.collect(log) } }) .print() }


 编辑
编辑
8.WindowReduce - WindowedStream → DataStream
将函数reduce函数应用到窗口并返回减少后的值。下述方法将 windowAll 内的全部数字累加并返回为 DataStream,每个数字为 5s 内所有数字的总和。
def windowReduceDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(5) dataStream.keyBy(data => { data.num.toString.slice(0, 1) }).windowAll(TumblingProcessingTimeWindows.of(Time.seconds(5))) .reduce(new ReduceFunction[Data] { override def reduce(o1: Data, o2: Data): Data = { Data(o1.num + o2.num) } }).print() }


 编辑
编辑
9.Union - DataStream → DataStream
合并两个或多个数据流,创建一个包含所有流中的所有元素的新流。注意:如果你将一个数据流与它本身合并,你将在结果流中获得每个元素两次。由于 union 了数据流本身,所以每个元素可以获得两次。
def unionDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(5) dataStream.union(dataStream).print() }


 编辑
编辑
10.Join - DataStream,DataStream → DataStream
在给定的键和公共窗口上连接两个数据流。将两流中的数据按照指定 key 进行连接并处理。下述 Demo 将相同数字连接并求和。
def joinDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(5) dataStream .join(dataStream) .where(x => x.num).equalTo(x => x.num) .window(TumblingProcessingTimeWindows.of(Time.seconds(3))) .apply(new JoinFunction[Data, Data, String] { override def join(in1: Data, in2: Data): String = { val out = in1.num.toString + " + " + in2.num.toString + " = " + (in1.num + in2.num).toString out } }).print() }


 编辑
编辑
11.InnerJoin - KeyedStream,KeyedStream → DataStream
在给定的时间间隔内用公共键连接两个键流中的两个元素,其中元素需满足:
e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound

简言之就是两条相同 key 的数据只有在规定时间的上下界内才会被连接,如果超时即使 key 相同也不会聚合。
def windowInnerJoinDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()).assignTimestampsAndWatermarks(new AscendingTimestampExtractor[Data] { override def extractAscendingTimestamp(t: Data): Long = System.currentTimeMillis() }) val dataStreamOther = env.addSource(new SourceFromCycle()).assignTimestampsAndWatermarks(new AscendingTimestampExtractor[Data] { override def extractAscendingTimestamp(t: Data): Long = System.currentTimeMillis() }) env.setParallelism(5) env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) dataStream.keyBy(_.num).intervalJoin(dataStreamOther.keyBy(_.num)) .between(Time.seconds(-1), Time.milliseconds(1)) .upperBoundExclusive() .lowerBoundExclusive() .process((in1: Data, in2: Data, context: ProcessJoinFunction[Data, Data, String]#Context, collector: Collector[String]) => { val out = in1.num.toString + " + " + in2.num.toString + " = " + (in1.num + in2.num).toString collector.collect(out) }) .print() }

上述 demo 设置时间为 -1s -> 1s,即前后共 2s 的时间容忍度,首先运行下述示例,其中 isWait 参数均为 false,即数据流均不延迟,产出正常。
val dataStream = env.addSource(new SourceFromCycle(isWait = false)).assignTimestampsAndWatermarks(new AscendingTimestampExtractor[Data] { override def extractAscendingTimestamp(t: Data): Long = System.currentTimeMillis() }) val dataStreamOther = env.addSource(new SourceFromCycle()).assignTimestampsAndWatermarks(new AscendingTimestampExtractor[Data] { override def extractAscendingTimestamp(t: Data): Long = System.currentTimeMillis() })

数据可以正常联结。
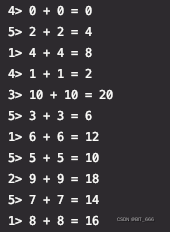
 编辑
编辑
下面将第一个流的 isWait 参数设置为 true:
val dataStream = env.addSource(new SourceFromCycle(isWait = true)).assignTimestampsAndWatermarks(new AscendingTimestampExtractor[Data] { override def extractAscendingTimestamp(t: Data): Long = System.currentTimeMillis() }) val dataStreamOther = env.addSource(new SourceFromCycle()).assignTimestampsAndWatermarks(new AscendingTimestampExtractor[Data] { override def extractAscendingTimestamp(t: Data): Long = System.currentTimeMillis() })

由于 isWait = true 时生成数据会延迟 3s,超过容忍度的 2s,所以数据无法联结,无数据产出。
12.WindowCoGroup - DataStream,DataStream → DataStream
在给定的键和公共窗口上对两个数据流进行协组。将相同 key 的数据组成 window 并按照该 key 将两流对应 key 的数据同时处理,下述 demo 处理两流中 5s 内首数字相同的所有数字。
def windowCoGroup(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(5) dataStream .coGroup(dataStream) .where(_.num.toString.head) .equalTo(_.num.toString.head) .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .apply { (t1: Iterator[Data], t2: Iterator[Data], out: Collector[String]) => val t1Output = t1.toArray.mkString(",") val t2Output = t2.toArray.mkString(",") val output = t1Output + "\t" + t2Output out.collect(output) }.print() }


 编辑
编辑
13.Connect - DataStream,DataStream → ConnectedStream
“连接”两个保持其类型的数据流。连接允许两个流之间的共享状态。Connect 有两种用处,一种是合并两个数据流,这里与 union 有一些不同,union 合并相同类型的数据流,即 Stream1,Stream2 都必须为 DataStream[T],Connect 可以合并不同类型的数据流,单数需要分别处理并最终 sink 相同的数据类型 T,例如 Stream1 为类型 A,Stream2 为类型 B,经过处理,二者都返回 T,则可以使用 Connect。第二种用法是 BroadcastStream,作为广播变量供另一个流共享,可以参考 Flink / Scala - DataStream Broadcast State 模式示例详解。下述 demo 对两个流的数据通过两个 Process 方法分开处理。
def connectDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) env.setParallelism(5) val connectStream = dataStream.connect(dataStream) connectStream.process(new CoProcessFunction[Data, Data, String] { override def processElement1(in1: Data, context: CoProcessFunction[Data, Data, String]#Context, collector: Collector[String]): Unit = { collector.collect("[Stream1]-" + in1.num.toString) } override def processElement2(in2: Data, context: CoProcessFunction[Data, Data, String]#Context, collector: Collector[String]): Unit = { collector.collect("[Stream2]-" + in2.num.toString) } }).print() }


 编辑
编辑
14.CoMap - ConnectedStream → DataStream
类似于连接数据流上的map和flatMap。下述 demo 对两个流数据单独处理并汇总。
def windowCoMapDemo(env: StreamExecutionEnvironment): Unit = { env.setParallelism(5) val dataStream = env.addSource(new SourceFromCycle()) dataStream.connect(dataStream).map(new CoMapFunction[Data, Data, String] { override def map1(in1: Data): String = "[1]:" + in1.num override def map2(in2: Data): String = "[2]:" + in2.num }).print() }


 编辑
编辑
15.CoFlatMap - ConnectedStream → DataStream
基本用法同上,可以返回0或多个数据,所以这里为 flatMap 函数提供了 Collector,可以生成多个数据,而 CoMap 则直接使用 map 函数构成 1-1 对应的关系。
def windowCoFlatMapDemo(env: StreamExecutionEnvironment): Unit = { env.setParallelism(5) val dataStream = env.addSource(new SourceFromCycle()) dataStream.connect(dataStream).flatMap(new CoFlatMapFunction[Data, Data, String] { override def flatMap1(in1: Data, collector: Collector[String]): Unit = { collector.collect("[1]-" + in1.num) collector.collect("[1 pow2]-" + in1.num * in1.num) } override def flatMap2(in2: Data, collector: Collector[String]): Unit = { collector.collect("[2]-" + in2.num) collector.collect("[2 pow2]-" + in2.num * in2.num) } }).print() }

16.Iterate - DataStream → IterativeStream → ConnectedStream
通过将一个操作符的输出重定向到前一个操作符,在流中创建一个“反馈”循环。这对于定义不断更新模型的算法特别有用。下面的代码从一个流开始,并连续地应用迭代体。大于0的元素被发送回反馈通道,其余的元素被下游转发。反馈循环流,该处理方式会将流内数据分为反馈流和下发流,前者的数据会持续循环的进行处理和迭代,而后者则会输出到 sink 结束其周期,多用于模型迭代,例如正样本匮乏的场景可以多次使用正样本反馈,而负样本则定时丢弃。下述 Demo 持续保留偶数,输出奇数。第一次 appear 奇偶数均有机会参与,但是到输出时只有 Data(奇数) 输出因为 Data(偶数) 继续进行反馈迭代。
def windowIterateDemo(env: StreamExecutionEnvironment): Unit = { val dataStream = env.addSource(new SourceFromCycle()) dataStream.iterate { iteration => { val iterationBody = iteration.map(data => { println(data.num + " " + "appear!") data }) // 反馈流,持续参与迭代 && 输出流,离开迭代 (iterationBody.filter(_.num % 2 == 0).setParallelism(1), iterationBody.filter(_.num % 2 != 0).setParallelism(1)) } }.print() }

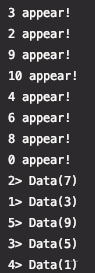
 编辑
编辑
三.总结
 编辑
编辑
Flink Stream 的基本 Transformation 大致就这些,以上方法官方 API 只给出简易 demo 无法运行所以匹配了数字的简单实例,一些 API 和 ProcessFunction 可能由于 Flink 版本不同有一些写法的不同,不过整体思路与思想不会改变,这里也顺便整理下 Flink Source -> Transformation -> Sink 的知识点。
FlinkDataSet Source -> Flink / Scala - DataSource 之 DataSet 获取数据总结
FlinkDataStream Source -> Flink / Scala - DataSource 之 DataStream 获取数据总结
FlinkDataSet Transformation -> Flink / Scala - DataSet Transformations 常用转换函数详解
FlinkDataStream Transformation -> Flink / Scala - DataStream Transformations 常用转换函数
Flink DataSet Sink -> Flink / Scala - DataSet Sink 输出数据详解
Flink DataStream Sink -> Flink / Scala - DataStream Sink 输出数据详解

