
目录
利用LogisticGD算法(梯度下降)依次基于一次函数和二次函数分布的数据集实现二分类预测(超平面可视化)
相关文章
DL之GD:利用LogisticGD算法(梯度下降)依次基于一次函数和二次函数分布的数据集实现二分类预测(超平面可视化)
DL之GD:利用LogisticGD算法(梯度下降)依次基于一次函数和二次函数分布的数据集实现二分类预测(超平面可视化)实现
利用LogisticGD算法(梯度下降)依次基于一次函数和二次函数分布的数据集实现二分类预测(超平面可视化)
设计思路
后期更新……
输出结果
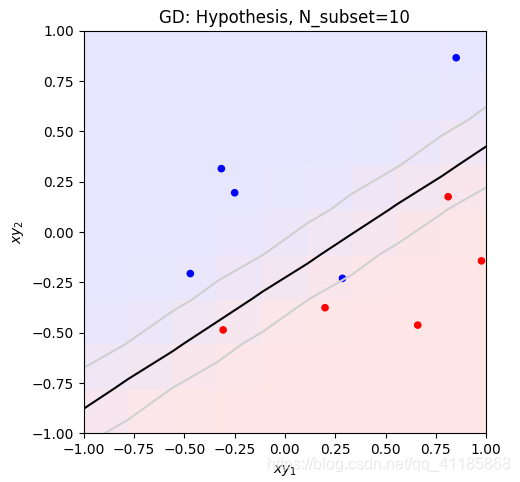
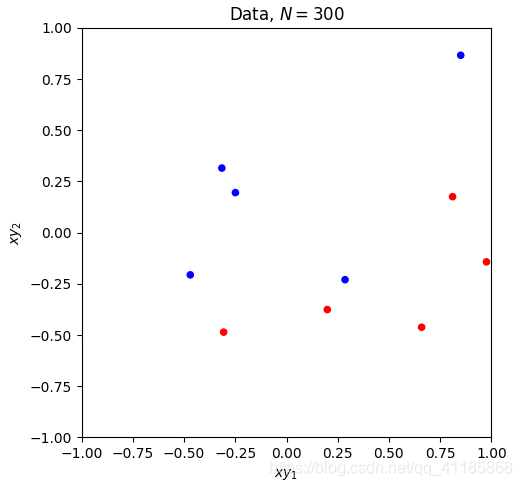
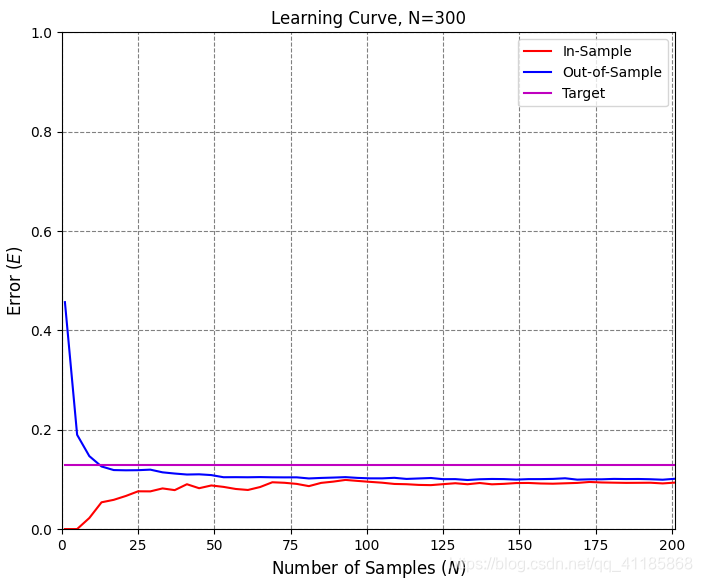
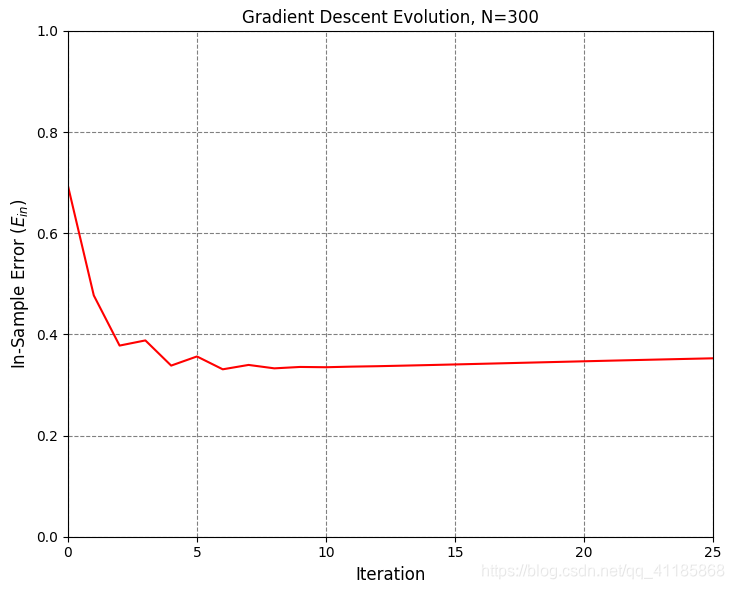
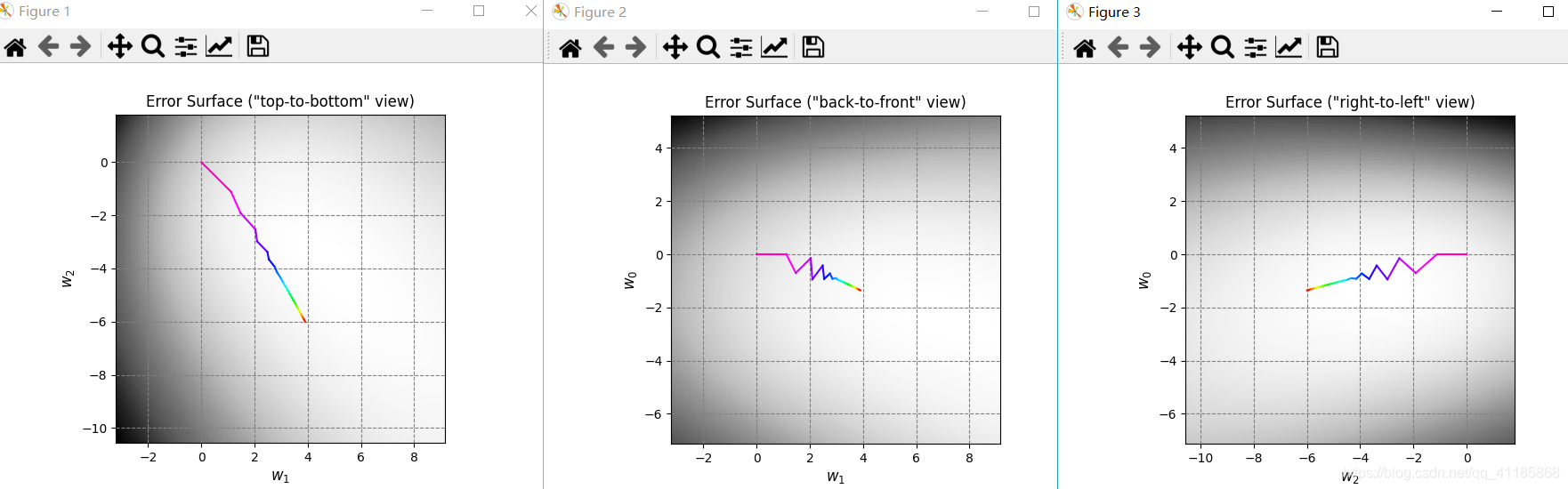
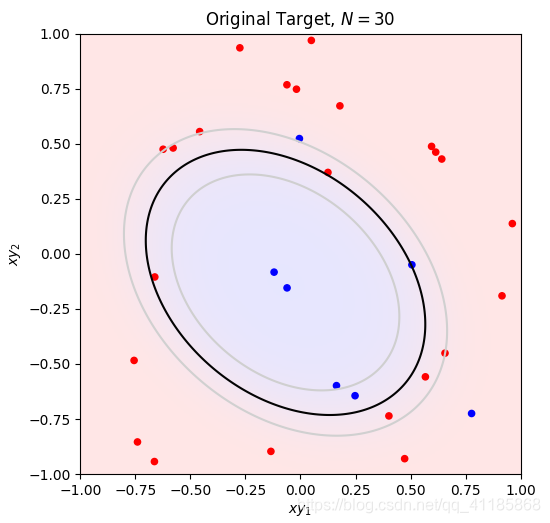
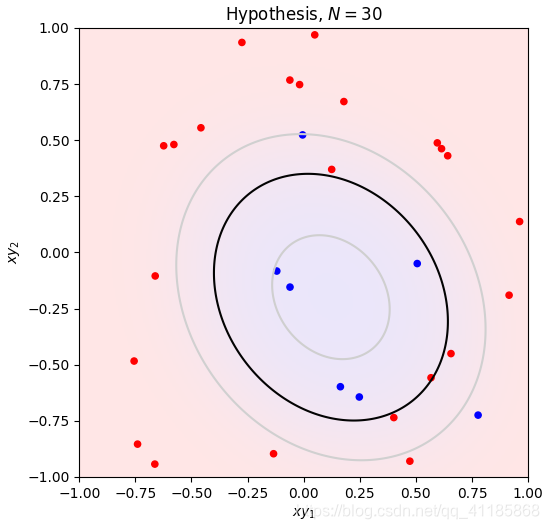
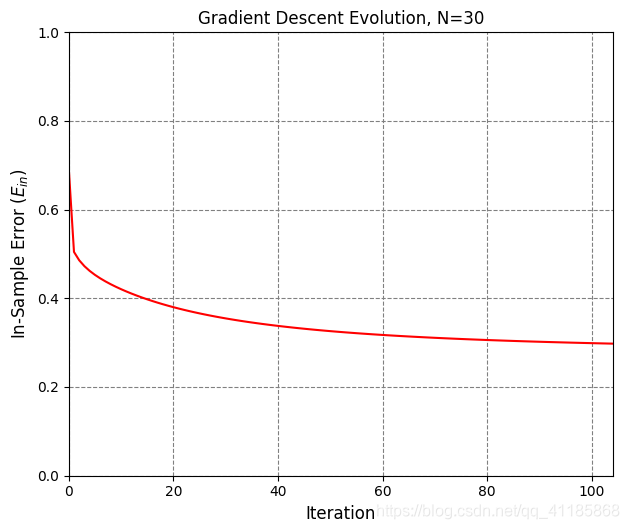
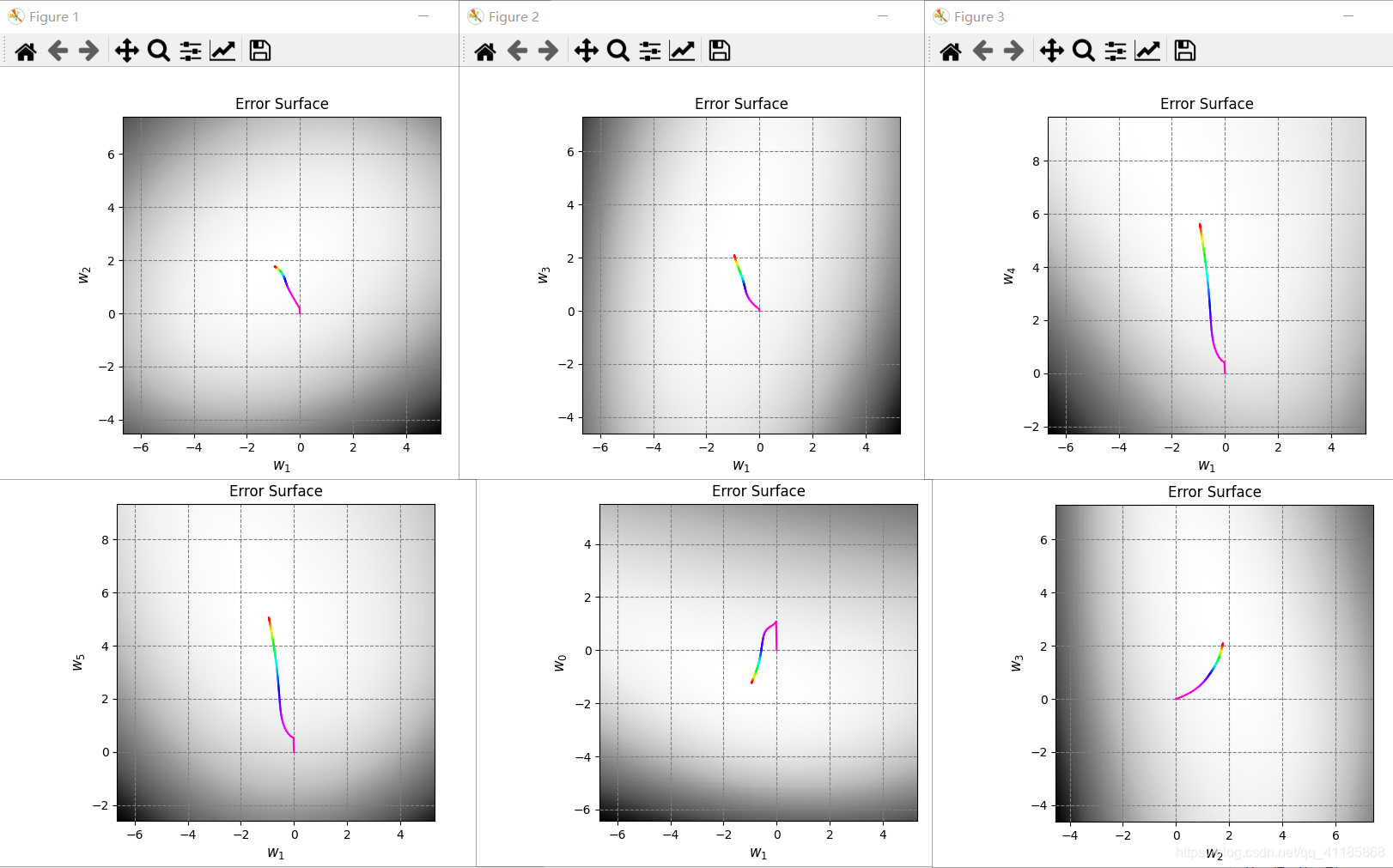
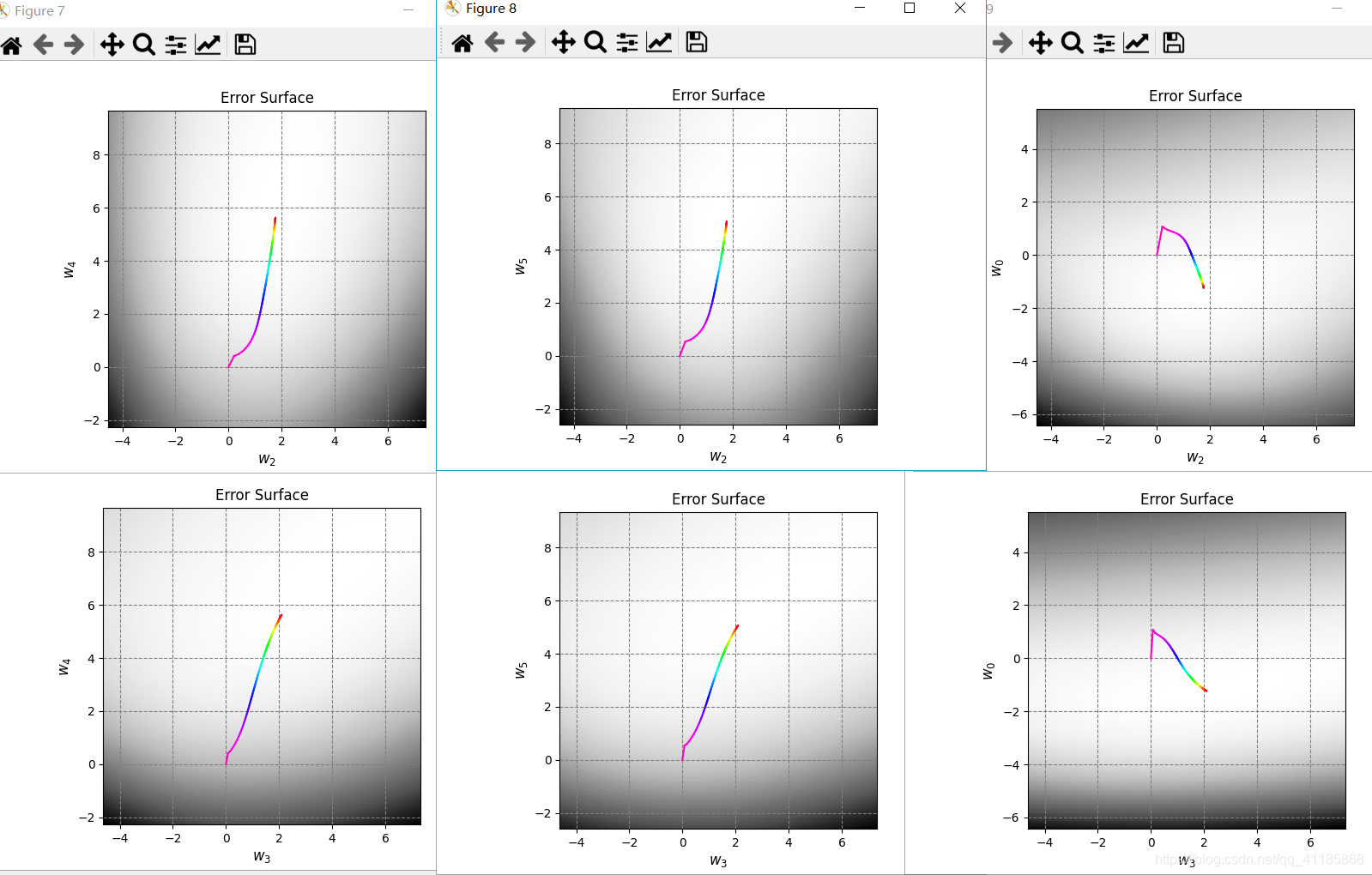
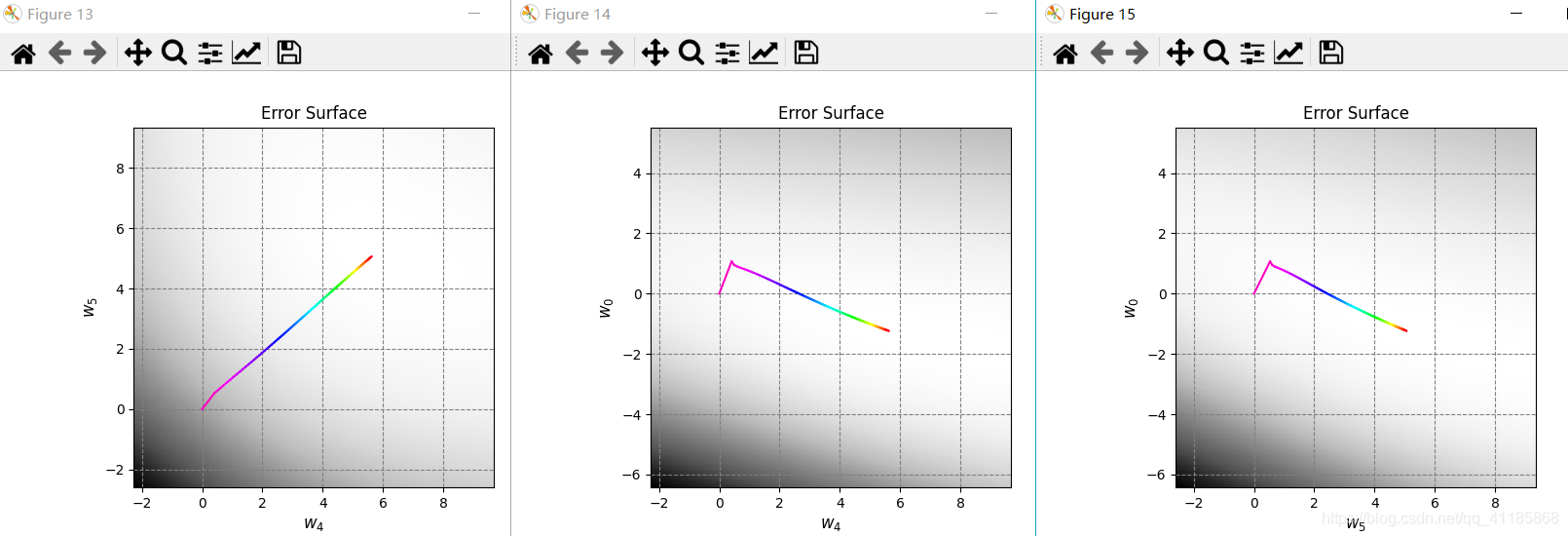
1. [ 1. 0.06747879 -0.97085008] 2. data_x 3. (300, 3) [[ 1. 0.83749402 0.80142971] 4. [ 1. -0.93315714 0.91389867] 5. [ 1. -0.72558136 -0.43234329] 6. [ 1. 0.21216637 0.88845027] 7. [ 1. 0.70547108 -0.99548153]] 8. 因为Linear_function函数无意义,经过Linear_function函数处理后,data_x等价于data_z 9. data_y 10. (300,) [-1. -1. -1. -1. 1.] 11. data_x: (300, 3) 12. data_z: (300, 3) 13. data_y: (300,) 14. [228 106 146 250 91 214 47 49 178 90] 15. Number of iterations: 26 16. 17. Plot took 0.10 seconds. 18. Plot took 0.04 seconds. 19. Target weights: [ -0.49786797 5.28778784 -11.997255 ] 20. Target in-sample error: 3.33% 21. Target out-of-sample error: 6.21% 22. Hypothesis (N=300) weights: [-0.45931854 3.20434478 -7.70825364] 23. Hypothesis (N=300) in-sample error: 4.33% 24. Hypothesis (N=300) out-of-sample error: 6.08% 25. Hypothesis (N=10) weights: [-1.35583449 3.90067866 -5.99553537] 26. Hypothesis (N=10) in-sample error: 10.00% 27. Hypothesis (N=10) out-of-sample error: 12.87% 28. Error history took 88.89 seconds. 29. Plot took 17.72 seconds. 30. Plot took 35.88 seconds. 31. GD_w_hs[-1] [-1.35583449 3.90067866 -5.99553537] 32. dimension_z 5 33. data_x 34. (30, 3) [[ 1. -0.0609991 -0.15447425] 35. [ 1. -0.13429796 -0.89691689] 36. [ 1. 0.12475253 0.36980185] 37. [ 1. -0.0182513 0.74771272] 38. [ 1. 0.50585605 -0.04961719]] 39. 因为Linear_function函数无意义,经过Linear_function函数处理后,data_x等价于data_z 40. data_y 41. (30,) [-1. 1. 1. 1. -1.] 42. 43. Plot took 1.02 seconds. 44. Number of iterations: 105 45. 46. Plot took 1.03 seconds. 47. Target weights: [-3 2 3 6 9 10] 48. Hypothesis weights: [-1.23615696 -0.9469097 1.76449666 2.09453304 5.62678124 5.06054409] 49. Hypothesis in-sample error: 10.00% 50. Hypothesis out-of-sample error: 15.47% 51. Plot took 16.58 seconds. 52. GD_w_hs[-1] [-1.23615696 -0.9469097 1.76449666 2.09453304 5.62678124 5.06054409]
核心代码
1. def in_sample_error(z, y, logisticGD_function): 2. y_h = (logisticGD_function(z) >= 0.5)*2-1 3. return np.sum(y != y_h) / float(len(y)) 4. 5. 6. def estimate_out_of_sample_error(Product_x_function, NOrderPoly_Function,Pre_Logistic_function, logisticGD_function, N=10000, Linear_function_h=None): 7. x = np.array([Product_x_function() for i in range(N)]) 8. z = np.apply_along_axis(NOrderPoly_Function, 1, x) 9. if not Linear_function_h is None: 10. z_h = np.apply_along_axis(Linear_function_h, 1, x) 11. else: 12. z_h = z 13. y = Pre_Logistic_function(z) 14. y_h = (logisticGD_function(z_h) >= 0.5)*2-1 15. return np.sum(y != y_h) / float(N) 16. 17. 18. def ErrorCurve_Plot(N,GD_w_hs, cross_entropy_error): 19. start_time = time.time() 20. fig = plt.figure() # figsize=(8, 6) 21. ax = fig.add_subplot(1, 1, 1) 22. ax.set_xlabel(r'Iteration', fontsize=12) 23. ax.set_ylabel(r'In-Sample Error ($E_{in}$)', fontsize=12) 24. ax.set_title(r'Gradient Descent Evolution, N={}'.format(N), fontsize=12) 25. ax.set_xlim(0, GD_w_hs.shape[0]-1) 26. ax.set_ylim(0, 1) 27. ax.xaxis.grid(color='gray', linestyle='dashed') 28. ax.yaxis.grid(color='gray', linestyle='dashed') 29. ax.set_axisbelow(True) 30. ax.plot(range(GD_w_hs.shape[0]), np.apply_along_axis(cross_entropy_error, 1, GD_w_hs), 'r-') 31. plt.show() 32. print('Plot took {:.2f} seconds.'.format(time.time()-start_time))

