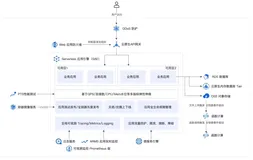
OpenWhisk 简介
OpenWhisk 是基于云的分布式事件驱动的编程服务。OpenWhisk 提供一种编程模型,将事件处理程序注册到云服务中,以处理各种不同的服务。其可以支持数千触发器和调用,可以对不同规模的事件进行响应。
OpenWhisk 是由许多组件构建的,这些组件让 OpenWhisk 成为一款优秀的开源 FaaS 平台。

Apache OpenWhisk 组件结构
OpenWhisk 部署
实验机器操作系统为 Ubuntu 18.04 Desktop。使用 GitHub 上所提供的 incubator-openwhisk 进行安装,如果本机没有安装 Git,需要先安装 Git:
apt install git
接下来克隆 repo 到本地目录:
git clone https://github.com/apache/incubator-openwhisk.git openwhisk
克隆完成之后,显示如图所示。

Apache OpenWhisk 项目 Clone
进入 OpenWhisk 目录,并且执行脚本。OpenWhisk 是由 Scala 开发的,运行需要安装 Java 环境。下面的脚本实现了 Java 环境的安装,以及其他的所需要的软件:
cd openwhisk && cd tools/ubuntu-setup && ./all.sh
Apache OpenWhisk 安装配置如图所示。

Apache OpenWhisk 安装配置
OpenWhisk 使用 ansible 进行部署,环境变量定义在 ansible/environments/group_vars/all 下:
limits:invocationsPerMinute: "{{ limit_invocations_per_minute | default(60) }}"concurrentInvocations: "{{ limit_invocations_concurrent | default(30) }}"concurrentInvocationsSystem: "{{ limit_invocations_concurrent_system | default (5000) }}"firesPerMinute: "{{ limit_fires_per_minute | default(60) }}"sequenceMaxLength: "{{ limit_sequence_max_length | default(50) }}"
上面程序定义了 OpenWhisk 在系统中的限制。
invocationsPerMinute 表示同一个 Namespace 每分钟调用 Action 的数量。
concurrentInvocations 表示同一个 Namespace 的并发调用数量。
concurrentInvocationsSystem 表示系统中所有 Namespace 的并发调用数量。
firesPerMinute 表示同一个 Namespace 中每分钟调用 Trigger 的数量。
sequenceMaxLength 表示 Action 的最大序列长度。
如果需要修改上述的默认值,可以把修改后的值添加到文件
ansible/environments/local/group_vars/all 的末尾。
例如,Action 的最大序列长度为 100,可以将 sequenceMaxLength: 120 添加到文件的末尾。接下来,为 OpenWhisk 配置一个持久存储的数据库,有 CouchDB 和 Cloudant 可选。以 CouchDB 为例,配置环境:
export OW_DB=CouchDBexport OW_DB_USERNAME=rootexport OW_DB_PASSWORD=PASSWORDexport OW_DB_PROTOCOL=httpexport OW_DB_HOST=172.17.0.1export OW_DB_PORT=5984
在 openwhisk/ansible 目录下,运行脚本,如图所示。
ansible-playbook -i environments/local/ setup.yml

执行脚本过程
接下来使用 CouchDB 部署 OpenWhisk,确保本地已经有了 db_local.ini。在 openwhisk/ 目录下执行部署命令:
./gradlew distDocker
如果部署过程中出现问题(如下图所示),可能是没有安装 npm 导致的,此时可以执行如下指令。


部署过程可能报错示例
apt install npm
稍等片刻,可以看到 Build 成功页面,如图所示。

Build 成功示例
接下来进入 openwhisk/ansible 目录:
ansible-playbook -i environments/local/ couchdb.ymlansible-playbook -i environments/local/ initdb.ymlansible-playbook -i environments/local/ wipe.ymlansible-playbook -i environments/local/ apigateway.ymlansible-playbook -i environments/local/ openwhisk.ymlansible-playbook -i environments/local/ postdeploy.yml
执行脚本过程如图所示。

执行脚本过程
部署成功后,OpenWhisk 会在系统中启动几个 Docker 容器。我们可以通过 docker ps 来查看:
docker ps --format "{{.Image}} \t {{.Names }}"
安装成功后的容器列表如图所示。

安装成功后的容器列表
开发者工具
OpenWhisk 提供了一个统一的命令行接口 wsk。生成的 wsk 在 openwhisk/bin 下。其有两个属性需要配置。
- API host 用于部署 OpenWhisk 的主机名或 IP 地址的 API。
- Authorization key(用户名或密码)用来授权操作 OpenWhisk 的 API。
设置 API host,在单机配置中的 IP 应该为 172.17.0.1,如图所示。
./bin/wsk property set --apihost '172.17.0.1'

设置 API host
设置 key:
./bin/wsk property set --auth `cat ansible/files/auth.guest
权限设置如图所示。

 设置权限
设置权限
OpenWhisk 将 CLI 的配置信息存储在 ~/.wskprops 中。这个文件的位置也可以通过环境变量 WSK_CONFIG_FILE 来指定。
验证 CLI:
wsk action invoke /whisk.system/utils/echo –p message hello –result{ "message": "hello"}
体验测试
创建简单的动作(action),代码如下:
# test.pydef main(args): num = args.get("number", "30") return {"fibonacci": F(int(num))}def F(n): if n == 0: return 0 elif n == 1: return 1 else: return F(n - 1) + F(n - 2)
创建动作:
/bin/wsk action create myfunction ./test.py --insecure
函数创建如图所示。

创建函数
触发动作:
./bin/wsk -i action invoke myfunction --result --blocking --param nember 20
得到结果,如图所示。

执行函数
至此,我们完成了 OpenWhisk 项目的部署以及测试。