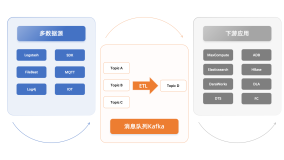
一说到数据孤岛,所有技术人都不陌生。在 IT 发展过程中,企业不可避免地搭建了各种业务系统,这些系统独立运行且所产生的数据彼此独立封闭,使得企业难以实现数据共享和融合,并形成了"数据孤岛"。
由于数据散落在不同数据库、消息队列中,计算平台直接访问这些数据时可能遇到可用性、传输延迟,甚至系统吞吐问题。如果上升到业务层面,我们会发现这些场景随时都会遇到:汇总业务交易数据、旧系统数据迁移到新系统中、不同系统数据整合。因此,为了能让数据更加实时、高效的融合并支持各业务场景,企业通常选择使用各种 ETL 工具以达到上述目的。
因此,我们可以看到企业自行探索的各种解决方案,比如使用自定义脚本,或使用服务总线(Enterprise Service Bus,ESB)和消息队列(Message Queue,MQ),比如使用企业应用集成(Enterprise application integration,EAI)通过底层结构的设计来横贯企业异构系统、应用、数据源等,实现数据的无缝共享与交换。
尽管以上手段都算实现了有效实时处理,但也给企业带来更难决断的选择题:实时,但不可扩展,或可扩展。但批处理。与此同时,随着数据技术、业务需求的不断发展,企业对 ETL 的要求也不断提升:
- 除了支持事务性数据,也需要能够处理诸如 Log、Metric 等类型越来越丰富的数据源;
- 批处理速度需要进一步提升;
- 底层技术架构需要支持实时处理,并向以事件为中心演进。
可以看到,流处理/实时处理平台作为事件驱动交互的基石。它向企业提供了全局化的数据/事件链接、即时数据访问、单一系统统管全域数据以及持续索引/查询能力。也正是面对以上技术与业务需求,Kafka 提供了一个全新思路:
- 作为实时、可扩展消息总线,不再需要企业应用集成;
- 为所有消息处理目的地提供流数据管道;
- 作为有状态流处理微服务的基础构建块。
我们以购物网站数据分析场景为例,为了实现精细化运营,运营团队以及产品经理需要将众多用户行为、业务数据以及其他数据数据进行汇总,这其中包括但不限于:
1. 用户各类点击、浏览、加购、登陆等行为数据;
2. 基础日志数据;
3. APP 主动上传数据;
4. 来自 db 中的数据;
5. 其他。
这些数据汇集到 Kafka,然后数据分析工具统一从 Kafka 中获取所需的数据进行分析计算。由于 Kafka 采集的数据源非常多且格式也各种各样。在数据进入下游数据分析工具之前,需要进行数据清洗,例如过滤、格式化。在这里研发团队有两个选择:(1)写代码去消费 Kafka 中的消息,清洗完成后发送到目标 Kafka Topic。(2)使用组件进行数据清洗转换,例如:Logstash、Kafka Stream、Kafka Connector、Flink等。
看在这里,大家肯定会有疑问:Kafka Stream 作为流式处理类库,直接提供具体的类给开发者调用,整个应用的运行方式主要由开发者控制,方便使用和调试。这有什么问题吗?虽然以上方法确实能够很快解决问题,但其问题也显而易见。
- 研发团队需要自行编写代码,且需要后期持续维护,运维成本较大;
- 对于很多轻量或简单计算需求,引入一个全新组件的技术成本过高,需要进行技术选型;
- 在某组件选定后,需要研发团队进行学习并持续维护,这就带来了不可预期的学习成本、维护成本。

为了解决问题,我们提供了一个更加轻量的解决方案:Kafka ETL 功能。
使用 Kafka ETL 功能后,只需通过 Kafka 控制台进行简单配置,在线写一段清洗代码,即可实现 ETL 的目的。可能存在的高可用、维护等问题,完全交由 Kafka。
那么接下来,我们为大家展示如何快速的创建数据 ETL 任务,仅需 3 步即可。
Step 1 : 创建任务
选择 Kafka 来源实例、来源 Topic,以及对应的选择 Kafka 目标实例、目标 Topic。并配置消息初始位置、失败处理以及创建资源方式。


Step 2:编写ETL主逻辑
我们可以选择 Python3 作为函数语言。与此同时,这里提供了多种数据清洗、数据转化模板,比如规则过滤、字符串替换、添加前/后缀等常用函数。


Step 3:设置任务运行、异常参数配置,并执行


可以看到,无需额外的组件接入或者复杂的配置,更轻量、更低成本的 Kafka ETL 仅需 3-5 步的可视化配置,即可开始 ETL 任务。对于数据 ETL 要求相对简单的团队而言,Kafka ETL 成为最佳选择,可以将更多精力放在业务研发上。
如此轻松便捷的 ETL 功能,真的不容错过!告别繁琐的脚本,告别组件选型与接入,立即扫码或点击原文链接,体验更加轻松的 ETL 吧!

原文链接:https://www.aliyun.com/product/kafka?utm_content=se_1009650951