云原生日志系统 EFK 实践(一)


为什么需要分布式日志系统
在以前的项目中,如果想要在生产环境中通过日志定位业务服务的Bug 或者性能问题,则需要运维人员使用命令挨个服务实例去查询日志文件,这样导致的结果就是:排查问题的效率非常低。
在微服务架构中,服务多实例部署在不同的物理机上,各个微服务的日志也被分散储存在不同的物理机。集群足够大的话,使用上述传统的方式查阅日志就变得非常不合适。因此需要集中化管理分布式系统中的日志,其中有开源的组件如Syslog,用于将所有服务器上的日志收集汇总。
然而集中化日志文件之后,我们面临的是对这些日志文件进行统计和检索,比如哪些服务有报警和异常,这些都需要有详细的统计。所以,在以前出现线上故障时,经常会看到开发和运维人员下载服务的日志,并基于 Linux 下的一些命令(如 grep、awk 和 wc 等)进行检索和统计。这样的方式不仅工作量大、效率低,而且对于要求更高的查询、排序和统计等操作,以及庞大的机器数量,难免会有点“力不从心”,无法很好地胜任。
容器的日志收集方式
如果日志放到容器内部,会随着容器删除而被删除。容器数量很多,按照传统的查看日志方式已变不太现实。
- K8S 中收集日志与传统条件下的日志收集有什么区别?
- 他一般是收集哪些日志?
- 确定收集日志类型之后又是怎么去收集的?
容器日志的分类
关于容器的日志分好几种,针对 k8s 本身而言有三种:
1、资源运行时的event事件。比如在k8s集群中创建pod之后,可以通过 kubectl describe pod 命令查看pod的详细信息。
2、容器中运行的应用程序自身产生的日志,比如 tomcat、nginx、php的运行日志。比如kubectl logs redis-master-bobr0。这也是官方以及网上多数文章介绍的部分。
3、k8s各组件的服务日志,比如 systemctl status kubelet。
k8s 的方式
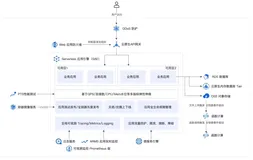
K8s本身特性是容器日志输出控制台,Docker 本身提供了一种日志采集能力。如果落地到本地文件,目前还没有一种好的采集方式。所以新扩容Pod属性信息(日志文件路径,日志源)可能发生变化流程和传统采集是类似的,如下图。

一般来说,我们用的日志收集方案有两种:
- 容器外收集。将宿主机的目录挂载为容器的日志目录,然后在宿主机上收集。
- 容器内收集。node上部署日志的收集程序,比如用 daemonset 方式部署,对本节点容器下的目录进行采集。并且把容器内的目录挂载到宿主机目录上面。目录为对本节点 /var/log/kubelet/pods 和 /var/lib/docker/containers/ 两个目录下的日志进行采集。
- 网络收集。容器内应用将日志直接发送到日志中心,比如 java 程序可以使用 log4j 2 转换日志格式并发送到远端。
- 在 Pod 中附加专用日志收集的容器。每个运行应用程序的 Pod 中增加一个日志收集容器,使用 emtyDir 共享日志目录让日志收集程序读取到。
官方使用的是最后一种方式,将 ElesticSearch 和 kibana 都运行在 k8s 集群中,然后用 daemonset 运行 fluentd。
ELKB 分布式日志系统
- Kibana :可视化化平台。Kibana 用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据,是一个 Web 网页。Kibana 利用 Elasticsearch 的 REST 接口来检索数据,调用 Elasticsearch 存储的数据,将其可视化。它不仅允许用户自定义视图,还支持以特殊的方式查询和过滤数据。
- Elasticsearch :分布式搜索引擎。具有高可伸缩、高可靠、易管理等特点。可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在使用最广的开源搜索引擎之一,Wikipedia 、StackOverflow、Github 等都基于它来构建自己的搜索引擎。
- Logstash :数据收集处理引擎。支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储以供后续使用。
- Filebeat :轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat 就是新版的 Logstash-fowarder,也会是 ELK Stack 第一选择。

这种架构下我们把 Logstash 实例与 Elasticsearch 实例直接相连。Logstash 实例直接通过 Input 插件读取数据源数据(比如 Java 日志, Nginx 日志等),经过 Filter 插件进行过滤日志,最后通过 Output 插件将数据写入到 ElasticSearch 实例中。
Filebeat 是基于原先 logstash-forwarder 的源码改造出来的,无需依赖 Java 环境就能运行,安装包10M不到。
如果日志的量很大,Logstash 会遇到资源占用高的问题,为解决这个问题,我们引入了Filebeat。Filebeat 是基于 logstash-forwarder 的源码改造而成,用 Go 编写,无需依赖 Java 环境,效率高,占用内存和 CPU 比较少,非常适合作为 Agent 跑在服务器上。
Filebeat 所消耗的 CPU 只有 Logstash 的 70%,但收集速度为 Logstash 的7倍。从应用实践来看,Filebeat 确实用较低的成本和稳定的服务质量,解决了 Logstash 的资源消耗问题。
前置条件:数据储存持久化
部署前需要创建数据持久化存储,pv 和 pvc。
选择 Node1:192.168.11.196 作为 NFS 服务器 。
# 三台都安装 NFS 和 RPCBINDyum -y install nfs-utils rpcbind mkdir-pv /ifs/kubernetes systemctl enable rpcbind systemctl enable nfs systemctl start nfs
$ vim /etc/exports /ifs/kubernetes *(rw,no_root_squash)
exportfs -r
找其他机器测试:
mount -t nfs 192.168.11.196:/ifs/kubernetes /mnt/
在 NFS 即 k8snode1 上新建三个文件夹:
mkdir-pv /ifs/kubernetes/{pv00001,pv00002,pv00003}
采用动态分配 pv 的方式。
#生产动态存储卷kubectl apply -f class.yaml #生成podskubectl apply -f deployment.yaml #赋权kubectl apply -f rbac.yaml # 最后自动创建存储卷kubectl apply -f deployment-pvc.yaml #验证效果kubectl get pv,pvc

小结
本文主要介绍了云原生日志系统 EFK 的相关概念以及集群搭建的前期准备,接下来的文章将会继续介绍 EFK 的配置实现。