
基于Serverless Devs的深度学习模型部署
配置
函数计算的基本配置
- 下载Serverless Devs开发者工具, 并完成阿里云密钥配置之后。
- 使用命令
s init完成项目的基本配置,以阿里云为例,选择带http触发器的python3的环境,并输入第一步获得的密钥。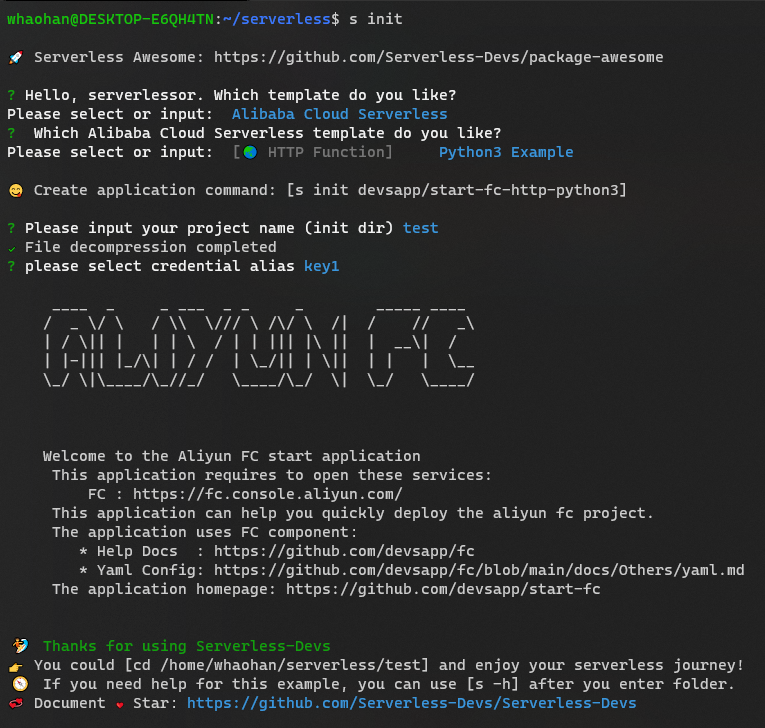
- 修改项目的配置文件
s.yaml,完成项目名称以及描述的配置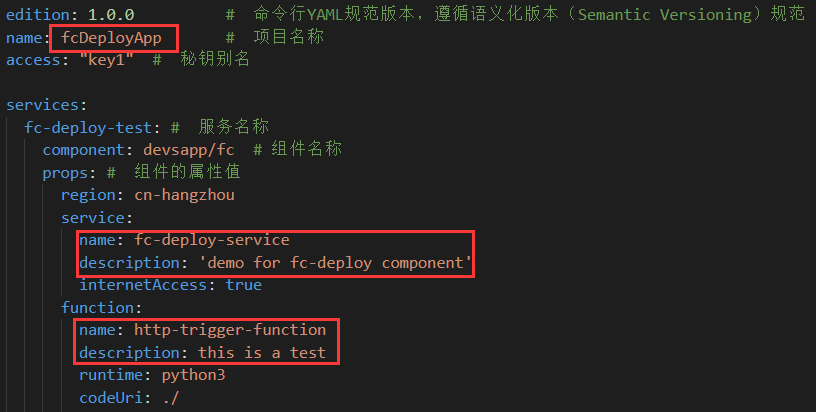
配置NAS和VPC
在深度学习模型的部署中,最难处理的是大体积的机器学习依赖安装以及深度学习模型参数的储存问题。通常而言,机器学习的库大小能接近1G,而深度模型一般也有100M起步。对于函数计算来说,为了减少平台的冷启动,都会设置代码包大小限制,阿里云的函数计算代码包必须在100MB以内。因此,我们需要一个云存储来解决依赖调用与模型参数加载的问题。在本示例中,我们使用NAS(Network Attached Storage)来存放我们的依赖与模型。NAS,简单来说说就是连接在网络上,具备资料存储功能的储存系统,我们可以通过挂载的方式对NAS进行访问。
- 开通阿里云NAS服务,并创建一个文件系统,根据业务需求我们可以选择不同的配置。
- 将获得的NAS地址写入配置,并将VPC设置为自动。
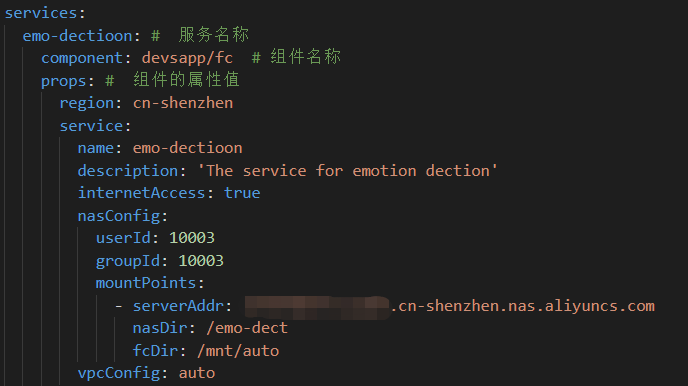
配置注意事项
- 由于深度学习模型初始化时间较长,建议将初始化时间
initializationTimeout调至120s以上 - 由于深度学习模型内存占用较大,建议将最大内存
memorySize调至521MB以上
- 更多配置可参考s工具配置文档。
代码架构
简单来说,我们可以将基于serverless devs的工程分成三个部分。.s文件夹中存放部分配置文件,以及我们build出来的依赖和代码;src文件夹存放我们的源代码和深度学习模型参数;s.yaml文件存放我们对函数计算的配置。

其中,src文件夹的index.py文件一般存放我们的函数入口,这里给出部分示例代码。在本项目中,我们需要对用户上传的图片进行处理。为了方便获取图片,这里我们使用flask框架。需要注意的是,对于每次执行都会进行的操作如加载模型参数,为了减少模型推理时间,我们将其放置在initialize函数中,这样这段代码只会被执行一次。
# -*- coding: utf-8 -*-
import logging
import numpy as np
from PIL import Image
import io
from skimage.transform import resize
import torch as torch
import torch.nn.functional as F
from flask import Flask, request
from models import VGG
import transforms as transforms
net = VGG('VGG19')
class_names = ['Angry', 'Disgust', 'Fear',
'Happy', 'Sad', 'Surprise', 'Neutral']
logger = logging.getLogger()
app = Flask(__name__)
def initialize(context):
# Get parameters from NAS
ROOT_DIR = r'/mnt/auto/'
# ROOT_DIR = r''
MODEL_PATH = ROOT_DIR + 'vgg_emo_dect.t7'
# Load the VGG network
logger.info('load the model ...')
checkpoint = torch.load(
MODEL_PATH, map_location=torch.device('cpu'))
net.load_state_dict(checkpoint['net'])
net.eval()
@app.route("/", methods=["POST", "GET"])
def predict():
logger.info('processing ...')
# get the image buffer
image = request.files.get('file').read()
# transform it to the np array
image_data = np.array(Image.open(io.BytesIO(image)))
# return the final result
inputs = preprocess(image_data)
score, predict = infer(inputs)
res = dict(zip(class_names, score.tolist()))
logger.info(class_names[int(predict)])
res['pred'] = class_names[int(predict)]
return res本地调试
由于本地的调试环境与远程的函数计算环境往往不同,为了兼容性,我们最好使用Docker拉取函数计算远程镜像进行调试。
- 下载docker(如果本机没有docker的话)
- 使用命令
s build --use-docker进行依赖安装 - 使用命令
s local invoke/start进行本地调试。
构建简单测试,对本地接口进行调用,示例测试代码:
import requests files = {'file':('1.jpg',open('1.jpg','rb'),'image/jpg')} url = 'http://localhost:7218/2016-08-15/proxy/emo-dectioon/get-emotion/' res = requests.post(url=url, files=files) print(res.text)
上传依赖与模型参数
上传依赖与模型参数到NAS
- 上传依赖:
s nas upload -r .s/build/artifacts/emo-dectioon/get-emotion/.s/python nas:///mnt/auto/python - 上传模型:
s nas upload src/vgg_emo_dect.t7 nas:///mnt/auto
- 查看是否上传成功:
s nas command ls nas://mnt/auto
- 查看安装的依赖:
s nas command ls nas:///mnt/auto/python/lib/python3.6/site-packages
上传成功后,我们可以在代码中简单使用路径获取对应文件:)
模型部署
在本地调试时,我们模型参数和依赖的路径都是本地路径。现在,我们要将这些路径转化为NAS的路径,并删去本地模型参数和调试生成的依赖(不然因代码包过大而无法进行部署)。需要注意的是,对于依赖,我们需要修改python的引用路径,这体现在我们的配置文件中:
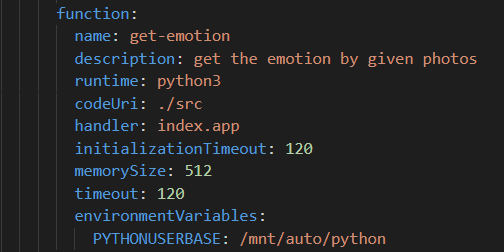
接着,运行命令s depoly即可将代码部署到远程:

用上述测试代码调用远程接口进行测试:

完整代码链接:Emotion Dection: The AI model deployment based on Serverless Devs

