作者简介:陶王飞,58快狗打车资深大数据开发工程师,长期专注于实时计算和数据应用。
前言
数据的实时化是最近几年数据行业很重要的趋势,我们在去年底也建立起新一代的实时数仓,但是在数据应用上一直没有取得很大的突破,我们希望实时数仓不仅仅是支撑大屏、核心实时报表、个别实时应用等简单的场景,希望更大的发挥实时数仓的价值,更方便、更快速、更大规模的对外提供数据服务是我们一直思考的问题。
基于阿里云Hoogres 所建设的统一数据服务,在一定程度上帮助我们实现了这个目标。
通过这套系统整合离线和实时数据,对外提供统一的数据服务,目前已经支撑了实时报表、用户司机实时标签系统,push系统、运力调度、营销活动实时监控、公司内部的客服后台系统等几十个数据需求,实现实时用户精细化运营。在数据易用性、交付周期、数据的准确性上都比以往有了很大的提升。
公司介绍
快狗打车(原58速运)是一家拉货的短途货运打车平台,解决比如搬家、买大家具家电、买各种大件、批发市场商家发货等场景对货车的需求,同时为蓝领司机师傅提供一个可以接单的平台,也就是货运版的“滴滴”,来实现帮助1000w人解决就业问题的目标。
数据服务的发展背景
原始阶段
在早期,我们的数据服务常见的场景,根据每一个需求加工数据。
如果是离线需求,通过Hive加工数据,使用Sqoop将结果数据导出到业务提供的MySQL表中,供业务查询。
如果是实时需求,开发一个实时项目将处理的数据落表或者发送MQ(Kafka或DMQ(自研组件)),提供到业务方使用。
这种从底到顶的烟囱式开发,导致的开发成本高、逻辑分散 、数据不一致、管理维护困难等问题,随着业务的发展,已经难以接受。
1.0阶段
18年我们基于Spark Streaming 和Spark SQL所实现的实时数仓,对落地表进行分层、建设大宽表,将计算好的数据统一存放到HBase中,使用ES给HBase做索引,并仿照SQL接口设计了一个较为简单的查询API,对外提供统一的查询接口。所有需要实时数据的任务都可以从这套系统获取数据,不再根据具体需求做定制化开发。
这种方式,在一定程度上降低了开发成本,增加了数据的复用、缓解了数据不一致问题,并且应用在多个实时程序上。但是因为计算层面Spark Streaming 状态支持有限很难做较复杂计算、开发修改成本高。存储和服务层面,通过接口查询在HBase中的数据,只能做明细查询和简单聚合查询,灵活性不足,能对外提供的功能有限,同时也没有能解决针对离线数据需求的问题,所以大部分应用主要是在部门内,为部门内提效。
2.0阶段
在去年底实现的基于Blink的实时数仓,借助于Blink SQL的实时ETL能力,重新设计了实时数仓的数据模型,完善了层级划分和主题建设,能对外提供的数据比之前多得多。
在存储层,我们选择类似于开源Doris的一种实时OLAP引擎,接口层面都是兼容MySQL,对于一些不是太复杂的OLAP查询,可以在秒级甚至亚秒级返回结果。我们将一部分查询场景简单、数据量大、查询QPS特别高的表输出到HBase中,使用ES做索引。
底层存储的割裂,只能在数据服务层做统一。为此我们设计了一套查询接口,无论数据存放在实时OLAP引擎、HBase、MYSQL、Maxcompute中,都可以通过接口的SQL查询出来。但是接口层并没有完全屏蔽底层存储,要根据数据存储位置不同,写不同的查询SQL。不同存储之间,也不能做跨库join,在使用上还是有很多的局限性。虽然承接了一些数据需求,但是这些局限还是约束了不能更大规模的推广,我们希望提供给到用户的是一个使用起来足够简单、丰富的数据服务。
3.0 阶段
底层存储的不一致导致的一系列问题一直困扰着我们 ,期望有一种引擎,具有帮助我们统一实时数据存储的能力。
我们是在Hologres(下面称Holo) 刚刚商业化的时候注意到Holo的,Holo提出的HSAP概念统一了服务的点查询和实时OLAP查询。通过一周多的测试、对Holo的系统架构有了一定了解之后,明确了预期收获、风险点、成本等因素后,写了一篇Holo的测试文章之后,将实时数仓的数据存储全部迁移到Holo。
同时基于Holo重新修改了数据服务接口,由于统一的数据存储、更完善的数据建设、以及Holo很强的实时OLAP能力、统一的数据服务,我们的需求交付能力相比以往有了很大的提升。很多以往要做几天的需求,现在只需要配置一条SQL,效率的提升是巨大的。系统上线两个月,接到了很多外部数据需求,目前每天请求百万次,高峰期实时OLAP 查询QPS上百(和OLTP的QPS不可比,可以想象1s向Hive提交100个查询),大部分周期查询平均耗时几十毫秒、两三百毫秒,很少有超过1s的。单个周期查询最大耗时很少有超过1s。虽然从请求量上看,并不是太大,但是考虑到公司体量和我们上线的时间,这个数据还是很可观的。目前公司新上的实时数据需求基本上都是在使用这套数据服务。
Hologres简介
下面是个人在使用Hologres过程中结合官网资料对Hologres的理解:
阿里云官网对Hologres 的介绍是:交互式分析(Hologres)是一款兼容PostgreSQL协议的实时交互式分析产品,与大数据生态无缝打通,支持对PB级数据进行高并发、低延时的分析处理。 是基于阿里提出的HSAP(hybrid serving and analytical processing)理念而设计的一种ROLAP系统。相对于HTAP(Hybrid transaction/analytical processing)来说,HSAP弱化了对事务的要求,追求更强的性能和更快的响应时间。
一般来说,为了应对不同的数据使用场景,我们会将高QPS的点查请求的数据存放在kv存储中,比如说Redis、HBase、Tair等系统中,分析型的数据存放在Druid、Clickhouse、Doris等系统中,有些场景还会使用ES、MySQL等。比如说下图美团到店的实时数仓存储分层图,就是目前常见的实时数仓存储架构。
HSAP理念的主要目标,将以上的这些存储统一成一种存储引擎,主要分为两种场景:点查(point query)和OLAP的查询,Holo的点查询实现很类似于HBase,使用很小的资源就可以支撑起很高的QPS,实时OLAP查询则是基于MPP的实时交互式查询,针对两种场景分别使用了行存和列存两种不同的存储格式。
在存储上,Hologres采取云原生设计,存储计算分离,数据存储在阿里云分布式文件系统pangu中(类比开源HDFS),方便按需单独扩展计算或者存储,读写分离的设计,以同时支持高并发读取和高吞吐的写入。
Holo的数据写入也是使用LSM tree ,写入即可见,定期刷新,但是碎片文件会分为多个级别。弱化一致性,仅支持原子写和Read-your-writes以实现高吞吐和低延迟的读取和写入。
宣传的是写入可以达到数亿的TPS,我们在压测时,没有遇到写入瓶颈。
在查询上,Hologres使用LBS做查询负载均衡,查询请求发送到Hologres FE,做查询优化,生成并行化的很多片段的执行计算DAG,提交给Blackhole执行。
Holo设计了称为HOS的用户态线程调度系统,执行上下文之间的切换成本几乎忽略不计,同时可以实现更高的并行。Holo的调度策略中,还考虑到大型分析查询不应阻止对低敏感的服务查询,此处的服务查询也就是点查询(point query)。和Clickhouse、Doris底层一样,Holo也是使用C++实现,使用native方法,以及向量化引擎等提供更好的性能。
我们在实际的使用中,还发现Holo的硬扫的能力很强,几百万级别的数据,不需要要索引就很快返回。
另外,Holo还提供了多种索引,可以手动添加,比如聚簇索引、分段索引、bitmap索引、字典索引等等。要注意的是,除bitmap和字典索引,其他索引都需要在建表时指定,不能修改。
如果对Holo的实现感兴趣,文末附有Holo发表在vldb上的论文链接。
场景实践
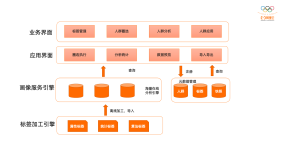
下面是58快狗打车基于Hologres的场景架构图,主要的架构思路是:
- 实时数据由Blink做实时ETL,写入Hologres。
- 使用Hologres统一实时数据存储。
- 基于Hologres和离线仓库之上,提供统一数据服务,对接业务层的各种报表、分析系统等

可以看到,整个架构主要有主要分为3个部分:数据服务、实时数仓和数据存储。下面将会就这3个部分仔细讲诉。
1.数据服务
主要基于Holo,我们做了一套对外提供的统一数据服务。从上面的架构图可以看到,用户提交的查询请求到统一数据服务接口,经过安全校验解析、别名映射后,提交到Holo等执行。
使用Holo为我们解决了两个半问题:
1)Holo很大程度上降低了存储的成本。
2)Holo解决了数据存储不统一的问题,同时提供了高性能的实时OLAP能力。
3)Holo提供了无需搬移数据,加速查询离线数据的功能,但是由于是以资源消耗为代价,性能会比直接查询Holo内部表差10倍,同时有较多的限制(例如单次query命中的数据量为200G、分区限制512个等)。所以,算是解决了半个问题。
然后,我们在数据服务接口做了更进一步的统一,数据服务接口以Holo为主,同时兼容一些历史上存放在MySQL中的任务。对于特别复杂,同时对响应时长不敏感的查询,也可以使用数据服务接口直接查询离线数据。所以,我们希望数据服务接口是作为整个数据部门统一的数据服务,统一对外的所有数据接口。
Blink任务修改后,可能会导致之前的状态不可用,状态清空,直接修改上线落表数据正确性会有影响。同时Holo大部分索引需要在建表时指定,如果一开始表设计不合理, 或者之前的表设计不再满足现有需求。这时候物理表如果被写入很多任务中,是很难修改的。所以我们设计了别名映射的mapping系统,mapping中会指定物理表,库名、连接等信息,用户只需要知道别名就可以使用,无需关心具体位置,同时别名是相对固定的。Blink修改任务时,可以新建任务写到新建表,待补齐数据,借助推送系统,一键切换,立即生效,所有的查询马上切换到新物理表,线上业务无感知,类似于一个主备切换的过程。另外如果一旦发生较大改动,也可以在我们这边控制。
服务保障方面,通过监控每次的查询,建立查询异常报警机制,监控整体服务的稳定性,对于不合理查询可以及时提供修改意见,保障整体服务持续稳定和高效。
2.实时数仓
实时数仓原始数据源来自日志数据和MySQL binlog订阅,我们开发了数据订阅平台,通过平台配置,将数据统一发送到Kafka中,使用Blink SQL做实时ETL,数据的输出主要有两种,表(Holo)和MQ(Kafka)。
在建模上,参考了离线的已有的数据模型,但是又不完全一样,主要体现在分层和表字段设计,这是因为离线、实时数据的本身的属性不同。离线每天拉取一次,一次性计算,跑一次,当天都可以一直使用,同时离线计算能力强,所以可以建设高内聚低耦合复杂的数据模型 ,使用逻辑下沉、复杂模型、完善分层和更完整维度抽象等方式,来更好的保障数据一致性和数据易用性。对外提供的也是聚合数据为主,明细为辅。
但是实时任务是24小时运行,更高的层级抽象意味着使用起来不灵活、链路长稳定性差、维护代价大、时效性差等。
所以,相较于离线,实时的层级更轻。很多公司在实时数仓会有较多的维度退化,我们基于Holo较好的join 性能,在一定程度上减少维度退化的设计,提高了灵活性和开发效率。
更重要的是,借助于Holo很好的实时OLAP性能,很多任务可以实时OLAP 现算,而不用针对具体任务加工具体的应用层数据,使用实时Join也不用做大宽表,这对效率的提升是巨大的。以前,很多实时需求需要专门写实时加工任务,而且如果需求修改,修改实时任务的代价也是很大的,整个开发周期好几天,现在可能使用统一数据服务接口,基于我们体系的数据建设,可能几分钟就可以交付了。
当然,也并不能过度的依赖于实时OLAP,在我们的最终实践上,为了更高的效率和一定的数据一致性。我们预处理了部分比较固化的计算在聚合层,对外提供的数据,优先使用固化的聚合层,对于比较灵活的查询和不好固化的统计,使用明细层,总体来说,以明细为主,需求交付效率有较大提升。
可能在很多公司,实时数仓更多应用在实时报表等运营实时监控等场景,对于风控等场景,会有独立的数据流程。我们认为实时数仓的优势在于,数据建设完整、开发效率高、对聚合类数据有不可替代的优势,虽然有数据处理链路长的劣势,但是如果仅仅是用在实时报表有一点浪费。 所以,我们在拓展实时数据应用时,一直是有所节制,场景主要限制在一些内部需求或者灵敏度不是特别高的业务场景,比如说我们准备做的,将取消订单等相关的信息、用户统计数据推送到客服系统等需求。对于个别像反作弊之类的线上业务,也会限制只提供低层的Kafka基础数据来确保稳定性。
3.数据存储
Lambda架构不仅会导致了计算的冗余,也导致了存储的冗余。而Kappa架构在目前的技术下,过于理想化。行业内还很少听到有完全的Kappa架构落地的案例,目前主要是以Lambda为主,个别地方会做调整优化的方式。
计算的冗余其实比较难以解决,虽然这几年实时计算技术发展迅速,但是实时计算还远远不能完全替代掉离线程度,实时任务修改的复杂度也远远高于离线任务。Flink的流批一体的方案,使用一套代码同时运行离线和实时计算的方案,目前也是在初期发展中,虽然没有用过,但是能想到应该有很多困难的地方。
相对而言,存储的一致性能做的事情更多。不考虑实际,理想情况下,离线和实时的数据都存储在一个存储引擎中,同时能跑批任务,也具有对外提供数据服务的能力。
Holo在这个方向上往前走了一步,除了解决了实时数仓存储统一的问题,还提供了离线外表的功能,可以将离线表作为Holo的外部表,借助于Holo比较强大的硬扫能力,来加快离线数据的查询,使用一套系统就能同时查询离线和实时的数据。上面也讲过,这种硬扫是以大量的磁盘IO和CPU资源为代价的,所以会有较多的限制,比如说为了更好的性能,对于外表的分区数量和MaxCompute数据量有一定的约束。这种做法可以理解为一种冷数据的处理,官方给的字眼是 ”离线加速“。
在实际使用中,我们测试对2亿数据的点查大约在2s左右,官方给到的数据是,相比于内部表,外部表性能会差10倍,可以满足一些对时效要求不高、查询频率不高的数据需求,在高时效性的任务这种性能表现可能不能满足需求,可以通过导入内表来解决。
具体到我们的实践上,对于一部分需要离线数据、对时效性要求不是特别高同时离线查询分钟级的响应时长不能满足、查询频率不高的需求,我们会以外部表的形式对外提供,语法还是和Holo内表相同的语法,对于需要一部分离线数据、同时时效性要求很高、查询频率很高的查询场景,我们选择将一部分离线数据导入到Holo中,有时会和实时对应任务放在同一个表中,对外提供服务,这种做法事实上造成数据冗余,是一种妥协。
总的来说,Holo 并没有完全解决实时和离线统一存储的问题,但是往前做了一些探索性的工作。目前,Holo和离线Maxcompute开发团队已经融合,期待下一步看到更多的融合。
业务价值
总结来讲,从业务开始接触Hologres并上线,在实战场景中带来的主要优势有以下几点:
1.统一了实时存储,解决了实时数据孤岛等问题
2.加速离线数据查询,简单查询可以数秒返回,但还是会有一些使用限制,需要根据实际使用场景来做调整。
3.数据模型的变化,一定程度上减少了以往实时过多的维度冗余,帮助我们建设更低耦合的实时数仓
4.加速了需求的交付,不需要做数据开发的需求,甚至只需要十几分钟就能交付任务,大大的提升了效率。交付的提升,我们可以将数据更大范围的推广。
同时,Holo作为新生事物,基于新型的架构设计,提供了非常强大的性能。我们在测试和使用的过程中,也发现了一些不足之处,也希望这些不足或者建议能帮助快速发展
1)目前Holo升级配置和版本需要停服,需要停服几分钟的时间,需要提前有准备,后续版本会解决。
2)Holo gis 功能目前不支持索引,在大量数据下效率较低,我们测试2亿数据下地理距离查询大约几秒钟。目前索引功能开发中。
3)Holo支持分区子表,有点类似于Hive的分区表,比较适合增量数据,在数据删除和查询上有一定的优势。但是目前每个分区子表必须手动提前建表,手动删除,当前的解决办法是通过调度任务来自动建表,期待Holo团队能够实现这个功能
4)资源隔离,在我们调研测试中,就发现高吞吐查询会影响到对延时要求高的小查询,在后来的实测中,发现即使是大查询没有完全跑满资源的情况,也会影响到小查询的响应时长。这个问题很早就和Holo沟通过,算是一个比较普遍的问题,开源引擎也会遇到,有些公司会使用独立集群对不同查询做物理隔离。Holo也已经明确给答复后面会彻底解决这个问题。由于我们很早就意识到这个问题,所以从一开始的整体设计就有预防和控制,目前还好。
5)在测试使用过程中,还发现一些小bug ,作为新产品,我们在享受便利的同时,也肯定会有一些不足的地方,我们也愿意同Holo一起成长。
未来规划
Holo帮助我们实现在实时数据数据存储方面,只使用一套存储,在一定程度上缓解了数据不一致的问题,算是前进了一大步。但是更远期来说,我们希望在未来可以彻底解决数据一致的问题,真正的让一份数据只存储在一个地方。
具体到眼前,我们的主要精力在系统的稳定性、规范化沉淀、工具提效、并通过需求来完善我们的数据服务体系,更好的易用性、更强的稳定性、更快的交付周期,会更多的在内部的建设上。
参考
Alibaba Hologres: A Cloud-Native Service for Hybrid Serving/Analytical Processing:http://www.vldb.org/pvldb/vol13/p3272-jiang.pdf