-
概述
目前行业内OLTP类的数据库单库单表支撑不了几十亿数据的在线处理,包括一些NoSQL数据库,因此对于数据量较大的场景需要进行数据库拆分,如mysql单表建议数据量再500w以内,一些强大的NoSQL单表可以支撑几亿的数据量,但是对于几十亿的数据量一样无法直接支撑,因此我们要做分库分表 - 分库分表类型
•垂直拆分:充分利用数据库的缓存,提升访问性能。
垂直切分是将一个表的不同属性切分到不同的表中,可以将访问频率高的、长度短的、或者经常一起访问的放在一个表里,
其它的放在另一个表里,从而提升数据库本身缓存的命中率来提升性能,但是单表大数据量依然存在性能瓶颈问题。
•水平拆分:借用分布式的优势,使用多个数据库的能力来提升存储容量和性能。
将数据均匀的分布在多个数据库多个表中
- 拆分键的选择
拆分键是水平分库分表的关键,怎么选择拆分键是能否做好分库分表的关键
1)找到业务主体,确保核心的数据库操作都是围绕这个主体数据进行,然后使用该主体对应的字段作为拆分键
1)选择拆分键的核心是要保证数据量均匀和请求量均匀
2)要考虑热点查询语句,尽量保证其不会进行跨库查询
3)要兼顾关联表,尽可能保证关联表的分库分表规则和主表一致
- 非拆分键的加速查询
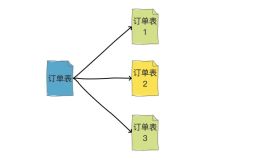
1)多维度表法:如订单表,本身按照订单进行拆分,按照实际场景又分别按照买家和卖家生成订单表
2)缓存映射法:缓存中记录查询条件->拆分键的映射关系,如fpdm+fphm -> fpid
3)基因融入法: 将查询条件融入到拆分键生成中,如假设分8个库,采用id%8路由,潜台词是,id的后3个bit决定这条数据落在哪个库上,这3个bit就是所谓的基因。
name -> 基因生成函数 -> name_gene -> 3bit
id(64 bit) = 生成全局唯一id(61 bit)+ 3bit
4)数据冗余法:使用外置索引(搜索引擎)或者大数据处理(如hive、hbase)来冗余数据进行解决
- 分库分表的查询过程
分库分表的查询一般使用DRDS、MyCat等中间件来实现,但是用哪款中间件不重要,重要的是我们要了解其核心原理,原理是基础,其他都是表现形式,有了内功之后做什么都无往不利,如令狐冲独孤九剑+吸星大法+易筋经
1)分片规则:自定义分片策略,主要是根据拆分键值计算出将该条数据放在哪个库哪个表里
2)JDBC规范重写:针对DataSource、Connection、Statement、PreparedStatement和ResultSet接口封装,对外提供的是逻辑实例,在内部封装多个真实物理实例实现类集合
3)sql解析:解决sql语法,可以直接使用druid的SQLParser
4)sql改写:修改逻辑表名->真实表名;替换不支持的功能,如:avg->sum和count;有可能一条sql语句变成多条,如avg查询会变成 2 * 分表数 的sql语句
5)sql路由:单表路由(不一定落在单表上,如in、between查询)、binding表路由(路由规则一致,如fpzxx和fpmx)、笛卡尔积路由(两个关联表路由不一致,性能很低,占用连接数很高,一般不使用)
6)sql执行:多线程并发执行sql
7)结果归并:遍历类、排序类(归并排序)、聚合类(比较型、累加型、平均型)、分组类