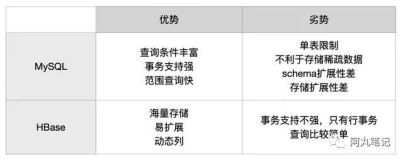
什么事HBASE :
HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据、实现数据分布式存储提供可靠的方案。从功能上来讲,HBase不折不扣是一个数据库,与我们熟悉的Oracle、MySQL、MSSQL等一样,对外提供数据的存储和读取服务。而从应用的角度来说,HBase与一般的数据库又有所区别,HBase本身的存取接口相当简单,不支持复杂的数据存取,更不支持SQL等结构化的查询语言;HBase也没有除了rowkey以外的索引,所有的数据分布和查询都依赖rowkey。所以,HBase在表的设计上会有很严格的要求。架构上,HBase是分布式数据库的典范,这点比较像MongoDB的sharding模式,能根据键值的大小,把数据分布到不同的存储节点上,MongoDB根据configserver来定位数据落在哪个分区上,HBase通过访问Zookeeper来获取-ROOT-表所在地址,通过-ROOT-表得到相应.META.表信息,从而获取数据存储的region位置
HBase设计与实践入门:
ROW Key:行健可以是任意字符串,在hbase内部,保存为字节数组,存储时,数据按照row key的字典序(byte order)排序存储,与NoSQL数据库一样,row key 是用来检索记录的主键,访问hbase table 中的行,三种访问方式:
1、通过单个row key 访问
2、通过row key 的range
3、通过全表扫描
rowkey是HBase实现分布式的基础,HBase通过rowkey范围划分不同的region,分布式系统的基本要求就是在任何时候,系统的访问都不要出现明显的热点现象,所以rowkey的设计至关重要,一般我们建议rowkey的开始部分以hash或者MD5进行散列,尽量做到rowkey的头部是均匀分布的。禁止采用时间、用户id等明显有分段现象的标志直接当作rowkey来使用。
列族(COLUMNS FAMILY):hbase表中的每个列,都归属与某个列族。列族是表的chema的一部分,必须在使用表之前定义。列名都以列族作为前缀
put 't1','r1','f1:c1','b1'
put 't1','r1','f1:c2','b2'
put 't1','r1','f1:c3','b3' ##一个列族里多个列
HBase的表设计时,根据不同需求有不同选择,需要做在线查询的数据表,尽量不要设计多个列簇,我们知道,不同的列簇在存储上是被分开的,多列簇设计会造成在数据查询的时候读取更多的文件,从而消耗更多的I/O
单元Cell:通过row和columns确定的为一个贮存单元为cell,CELL中的数据没有类型,全部是字节码形式存贮。
时间戳timestamp:每个cell都保存着同一份数据的多个版本,版本通过时间戳来索引,类型是64位整形,不同版本的数据按照时间倒叙排序,最新的数据排列在最前面
选择合适的数据过期时间也是表设计中需要注意的一点,HBase中允许列簇定义数据过期时间,数据一旦超过过期时间,可以被major compact进行清理。大量无用历史数据的残余,会造成region体积增大,影响查询效率。
HBASE shell 的常用操作:
1、创建表:create 't1','f1','f2','f3' #t1为表名字,f1-f3为列族名
2、查看所有的表:list
3、查看表的结构:describe 't1'
4、增加一个列族:a、先disable "表名"
b、alter 't1',NAME=>'f4',VERSIONS =>3
c、enable 't1'
5、删除某个列族:alter 't1', {NAME => 'f1'}, {NAME => 'f2', METHOD => 'delete'}
a、先disable "表名"
b、alter 't1',NAME=>'f4',METHOD =>'delete'
c、enable 't1'
6、查看表是否存在: exists 't1'
7、查看表是否允许修改:is_enable 't1'
8、删除表:
a、disable 't1'
b、drop 't1'
9、写入数据:put 't1','r1','f1:c1','value' #给t1表的r1行健的f1的列族的c1列插入一个值,列族的列事先可以先不存在
put 't1','r1','f1:c1','b1'
put 't1','r1','f1:c2','b2'
put 't1','r1','f1:c3','b3' ##一个列族里多个列
10、查询数据:
get 't1','r1' #查询r1的所有值
get 't1','r1','f1:c1' #获取某列的值
get 't1','r1','f1','f2' 《==》get 't1','r1',"f1:c1","f2:c2"
11、删除某行数据:deleteall 't1','r1'
12、获取表的所有行健值:scan 't1'
获取前几行的数据:scan 't1',{LIMIT=>1}
获取表从指定的位置行开始:scan 't1',{STARTROW=>'rowkey',LIMIT=>1}
获取表指定列的所有行数据:scan 't1',{COLUMNS=>'f1:c1'}
获取表从某一列根据时间来取:scan 't1′, {COLUMNS => 'c1', TIMERANGE => [1303668804, 1303668904]}
13、清空表:truncate 't1'
14、统计行数:count 't1'
count 't1′, INTERVAL => 100000
count 't1′, CACHE => 1000
count 't1′, INTERVAL => 10, CACHE => 1000 #count一般会比较耗时,使用mapreduce进行统计,统计结果会缓存,默认是10行。统计间隔默认的是1000行(INTERVAL)。
本文转自 DBAspace 51CTO博客,原文链接:http://blog.51cto.com/dbaspace/1950000