
以下内容源于对 PEP-0263 的翻译和解读,同时给出了一些网上网友的说法。
======== 我是分割线 ========
PEP 0263 -- Defining Python Source Code Encodings
【摘要】
给出声明 Python 源文件编码的语法。该编码信息后续会被 Python 解析器用于解析源文件。
这种方式增强了对源文件中 Unicode 编码字的处理。
【问题】
Python 2.1 时代,Unicode 字符只能利用 Latin-1 字符进行“Unicode 转义”的方式来表示(也就是说当时只支持 Latin-1 字符编码,所以 Unicode 字符编码只能使用 Latin-1 字符来进行转义表示)。这对广大亚洲人民是很坑爹的。
【解决方案】
通过在 Python 脚本文件的头部增加 显式的、可按文件随时改变的 特殊注释,来声明编码方式。
【编码定义】
Python 默认使用 ASCII 编码。
若要自定义 Python 源码的编码方式,需要在脚本文件的第一或者第二行的位置上添加如下定义:
1.
2.
3.
在前两种方式中,实际上是通过 coding[:=]\s*([-\w.]+) 这个正则表达式来进行匹配。
为了支持 Windows 平台上的应用,会在生成的 Unicode 文件的头部添加 Unicode BOM 标识,其中带有 UTF-8 标识 '\xef\xbb\xbf' 的文件会被当做具有 UTF-8 编码的文件(此时在 Python 脚本的头部没有那行编码特殊注释也没问题) 。
如果出现源文件同时使用了 UTF-8 BOM 标识和文件头部的特殊注释的情况,那么在表明编码的特殊注释中只能使用 'utf-8' 这个字串,其他情况会报错。
【举例】
1. Python 解析器说明 + Emacs 风格的文件编码注释
2. 无 Python 解析器说明 + 普通明文描述
3. Python 解析器说明 + 非 Emacs 风格的文件编码注释
4. 无编码注释(Python 解析器默认为 ASCII)
5. 错误的编码注释方式
a. 无 coding: 前缀
b. 编码注释不在第一或第二行
c. 使用不支持的编码
=========== 我是分割线 ============
小实验截图:
输出中文。

报错。
添加编码。
正常输出。
IDE默认的编码设置。
各种转码输出。
输出的结果。
补充说明:
cp936即 code page 936(代码页936)是以GBK(国标扩展字符集)为基础的编码。GB2312(国标字符集)只是GBK的一部分。 GB2312只支持常用的汉字,而且是简体字。GBK支持繁体字和生僻字。
======== 我是分割线 ========
PEP 0263 -- Defining Python Source Code Encodings
【摘要】
给出声明 Python 源文件编码的语法。该编码信息后续会被 Python 解析器用于解析源文件。
这种方式增强了对源文件中 Unicode 编码字的处理。
【问题】
Python 2.1 时代,Unicode 字符只能利用 Latin-1 字符进行“Unicode 转义”的方式来表示(也就是说当时只支持 Latin-1 字符编码,所以 Unicode 字符编码只能使用 Latin-1 字符来进行转义表示)。这对广大亚洲人民是很坑爹的。
【解决方案】
通过在 Python 脚本文件的头部增加 显式的、可按文件随时改变的 特殊注释,来声明编码方式。
【编码定义】
Python 默认使用 ASCII 编码。
若要自定义 Python 源码的编码方式,需要在脚本文件的第一或者第二行的位置上添加如下定义:
1.
|
1
|
# coding=<encoding name>
|
|
1
2
|
#!/usr/bin/python
# -*- coding: <encoding name> -*-
|
|
1
2
|
#!/usr/bin/python
# vim: set fileencoding=<encoding name> :
|
为了支持 Windows 平台上的应用,会在生成的 Unicode 文件的头部添加 Unicode BOM 标识,其中带有 UTF-8 标识 '\xef\xbb\xbf' 的文件会被当做具有 UTF-8 编码的文件(此时在 Python 脚本的头部没有那行编码特殊注释也没问题) 。
如果出现源文件同时使用了 UTF-8 BOM 标识和文件头部的特殊注释的情况,那么在表明编码的特殊注释中只能使用 'utf-8' 这个字串,其他情况会报错。
【举例】
1. Python 解析器说明 + Emacs 风格的文件编码注释
|
1
2
3
4
|
#!/usr/bin/python
# -*- coding: latin-1 -*-
import
os, sys
...
|
|
1
2
3
4
|
#!/usr/bin/python
# -*- coding: iso-8859-15 -*-
import
os, sys
...
|
|
1
2
3
4
|
#!/usr/bin/python
# -*- coding: ascii -*-
import
os, sys
...
|
2. 无 Python 解析器说明 + 普通明文描述
|
1
2
3
|
# This Python file uses the following encoding: utf-8
import
os, sys
...
|
3. Python 解析器说明 + 非 Emacs 风格的文件编码注释
|
1
2
3
4
|
#!/usr/local/bin/python
# coding: latin-1
import
os, sys
...
|
4. 无编码注释(Python 解析器默认为 ASCII)
|
1
2
3
|
#!/usr/local/bin/python
import
os, sys
...
|
5. 错误的编码注释方式
a. 无 coding: 前缀
|
1
2
3
4
|
#!/usr/local/bin/python
# latin-1
import
os, sys
...
|
|
1
2
3
4
5
|
#!/usr/local/bin/python
#
# -*- coding: latin-1 -*-
import
os, sys
...
|
|
1
2
3
4
|
#!/usr/local/bin/python
# -*- coding: utf-42 -*-
import
os, sys
...
|
=========== 我是分割线 ============
小实验截图:
输出中文。

报错。
 添加编码。
添加编码。

正常输出。
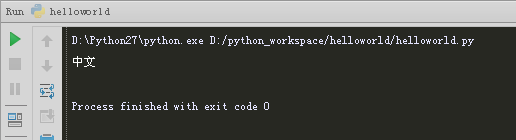
IDE默认的编码设置。

各种转码输出。

输出的结果。


补充说明:
cp936即 code page 936(代码页936)是以GBK(国标扩展字符集)为基础的编码。GB2312(国标字符集)只是GBK的一部分。 GB2312只支持常用的汉字,而且是简体字。GBK支持繁体字和生僻字。

