
1.概述
这篇博客不涉及到具体的编码,只是解答最近一些朋友心中的疑惑。最近,一些朋友和网友纷纷私密我,我总结了一下,疑问大致包含以下几点:
- 我学 Hadoop 后能从事什么岗位?
- 在遇到问题,我该如何去寻求解决方案?
针对以上问题,我在这里赘述下个人的经验,给即将步入 Hadoop 行业的同学做个参考。
2.我学 Hadoop 后能从事什么岗位
目前 Hadoop 相关的工作大致分为三类:应用,运维,二次开发
2.1 应用
这方面的主要工作是编写MapReduce作业,利用Hive之类的套件来进行数据分析或数据挖掘,Hadoop在这里只是一个基础平台,仍然是需要自己编写相应的逻辑去实现对应的业务。从事这方面的工作,你至少要懂一门编程语言,如Java,Shell,Python等。由于Hadoop的源码是用Java语言编写的,目前业界Java方面的Hadoop社区活跃度相对较高,Shell和Python对应的活跃度较少。目前培训机构都是在这方面进行培养的比较多,你只需要对Hadoop的框架构造,基本的组织结构有所了解,理解MapReduce的编程框架和模式,懂得代码调优,能够使用Hadoop的相关套件,如:Hive,Sqoop,Flume等。
2.2运维
这方面主要负责Hadoop集群的搭建,系统的各种参数的调优,集群故障处理和保持集群运行稳定,这部分人才目前市场上是较为奇缺的,也是很多在Hadoop平台相对成熟的企业所青睐的人才,对于从事这部分工作的人同学来说,他可以不懂Java语言,但是在工作上必须处事冷静,做事严谨认真。如果由较强的钻研精神,可以通过自己的在实际工作中摸索一些调优的解决方案。同样,也可以参加一些峰会,沙龙之类的互动活动与业界的一些牛人交流工作心得,从而来获取一些有价值的方案。另外一个能体现Hadoop运维价值的因素,遇到问题能够快速定位并找到解决方案,不过这部分的工作经验都是靠平时工作日积月累出来的,当然和你运维的集群规模大小也有一定关系,若你由机会进入到拥有大集群的公司进行这方面的工作,你的成长会很快,不单单是运维Hadoop。Hadoop运维这类工作是没法弄虚作假的,你想随便谷歌点资料去忽悠,很容易被识破。
2.3二次开发
从事这方面工作的要求较高,而且也不是所有的企业都设有这样的工作岗位,这部分的工作有:按照企业实际需求,对Hadoop的框架本身进行修改以适用于企业本身业务;研究版本的新特性;规划版本升级等等。这方面就需要你对Hadoop的源码进行深入了解学习和研究,时刻关注Hadoop官网及Hadoop社区,了解最新版本的特性,把握Hadoop未来的发展前景及房子方向。
但是并不是所有的企业将这些岗位划分的这么明细的,有些企业根本不涉及二次开发,一个Hadoop工程师同时负责开发和运维,所以,我们不仅要在Hadoop应用这块烂熟于心,而且,基本的Hadoop运维我们也必须要掌握,至少集群的搭建,基本的集群维护这些我们要会去做。
3.在遇到问题,我该如何去寻求解决方案
这个问题是很多初入Hadoop的同学会遇到的,在开发时遇到异常,或集群在运行时抛出一些异常,不知所措,下面我给出自己在实际工作中的一些心得体会。
一般抛出异常,log 文件都会有记录,这些问题很大一部分可能是你首次遇到,遇到问题我得先备份这些信息(log文件,异常操作记录)。然后,我们在仔细分析日志信息,若实在是没有解决思路,则可参考以下方案:
- Google 关键字
这里给大家举个例子,异常信息如下所示:
java.io.ioexception could not obtain block blk_
这个异常信息我只截取了部分,我们首先到Google去搜索对应得关键字,如下图所示:
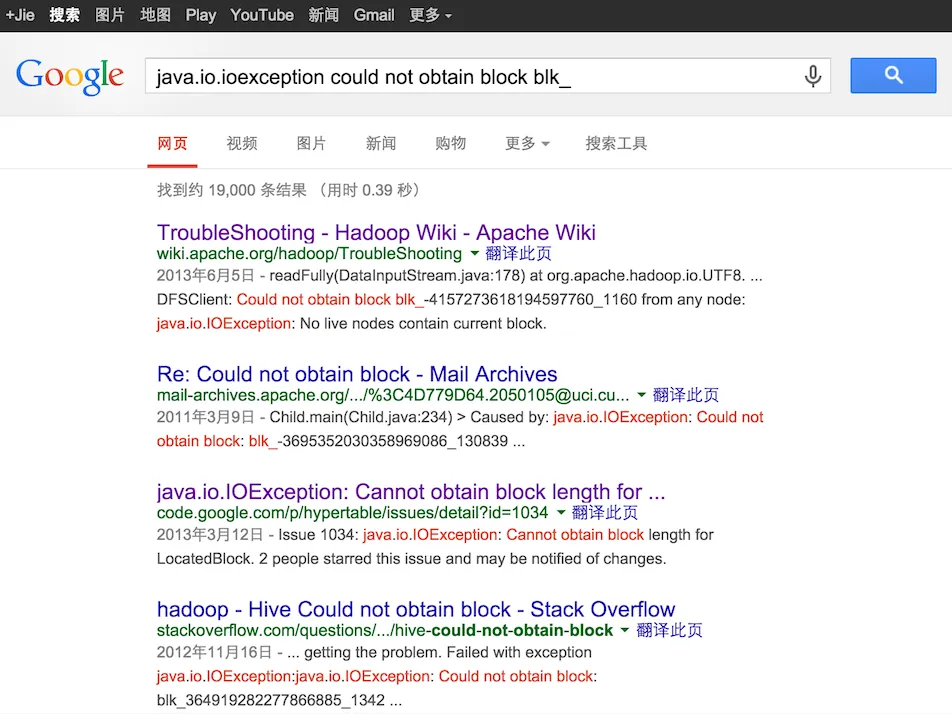
然后,Google会列出匹配到得或是相似得问题得结果,我们可以从中筛选出我们想要得结果。
- Hadoop Jira
若是在Google后找不到想要得结果,可在Apache的官方Jira上查找关键字,这里有来自世界各地从事这方面的人,他们会把出现的这些现象做详细的描述,有的甚至会给出解决方案,和附上相应的patch。
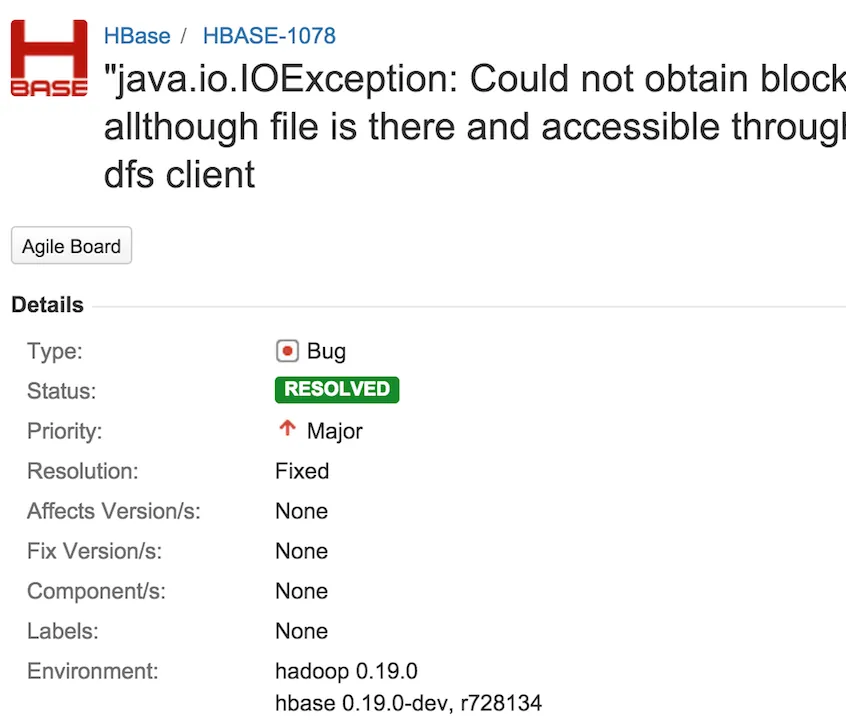

部分 Comments 截图如下所示:
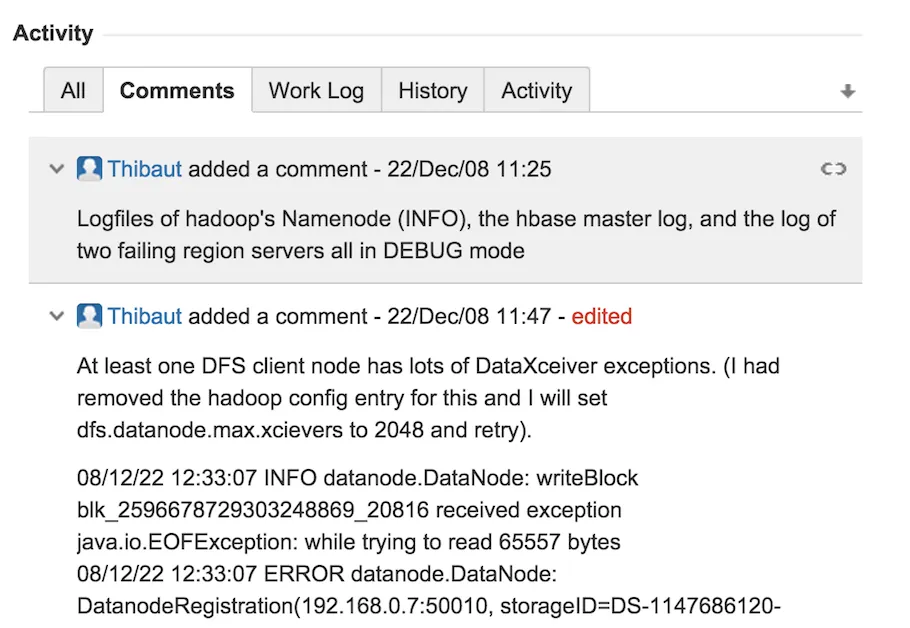
通过阅读评论,我们知道出现这种情况大多数是节点断开了,连接不上,原因找到后,我们就好去解决了。
- 源码
若以上两中方式都未能解决,查看源码,理解工作原理,初步猜测原因,调试验证。其实解决只是时间问题。如果你想深入了解,阅读官方的Jira,找到你感兴趣的问题去研究。绝对会有不一样的体验。
4.结束语
这篇答疑博客就和大家分享到这里,如果大家在研究的过程当中,有什么疑问可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
