

人工智能正在深刻地改变世界,而Python凭借其简洁的语法、丰富的库生态和活跃的社区,已经成为AI领域的首选语言。然而,从理论到实践之间存在着巨大的鸿沟:如何选择合适的模型架构?如何处理真实世界的脏数据?如何将模型部署到生产环境?如何持续监控和优化模型性能?本文将从零构建一个生产级智能图像识别系统,完整呈现Python+AI项目开发的实战流程,涵盖数据采集、数据增强、模型训练、模型优化、模型部署、A/B测试、持续学习等全生命周期环节。
第一部分:项目概述与需求分析
1.1 项目背景与目标
在电商领域,商品分类是基础且重要的一环。传统的商品分类依赖人工打标,效率低、成本高、一致性差。随着深度学习的发展,计算机视觉技术可以自动识别商品类别,极大提升运营效率。
项目名称: AI Product Classifier - 智能商品分类系统
项目目标: 构建一个能够自动识别商品图片所属类别的AI系统,支持100个常见商品类别(服装、电子产品、家居用品等),准确率达到95%以上,单张图片推理时间小于100ms。
为什么选择图像分类作为实战项目?
涵盖AI项目开发的完整流程
有成熟的预训练模型可供使用(ResNet、EfficientNet、ViT)
可以逐步演进:基础模型 → 微调 → 蒸馏 → 部署
数据增强、迁移学习、模型优化等技术通用性强
业务价值明确,易于展示效果
1.2 功能需求
┌─────────────────────────────────────────────────────────────┐
│ 智能商品分类系统功能 │
├─────────────────────────────────────────────────────────────┤
│ 1. 训练模块 │
│ - 数据加载与预处理 │
│ - 数据增强(翻转、旋转、色彩抖动等) │
│ - 模型训练(ResNet/EfficientNet/ViT) │
│ - 模型评估(准确率、召回率、F1分数) │
│ - 模型导出(ONNX/TensorRT) │
│ │
│ 2. 推理模块 │
│ - 单张图片分类 │
│ - 批量图片分类 │
│ - 返回Top-K预测结果 │
│ - 置信度分数 │
│ │
│ 3. API服务 │
│ - RESTful API接口 │
│ - 异步推理队列 │
│ - 请求限流与认证 │
│ - 结果缓存 │
│ │
│ 4. 监控模块 │
│ - 推理延迟监控 │
│ - 准确率监控(人工抽检) │
│ - 数据漂移检测 │
│ - 模型版本管理 │
│ │
│ 5. 持续学习 │
│ - 难例挖掘 │
│ - 主动学习 │
│ - 在线模型更新 │
└─────────────────────────────────────────────────────────────┘
1.3 非功能需求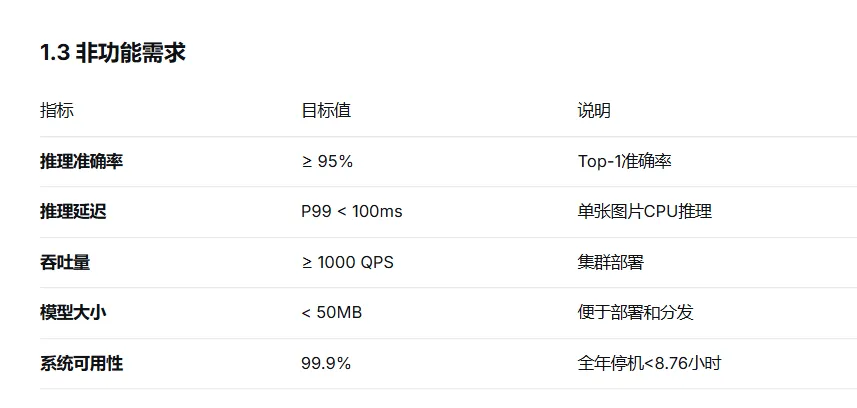
1.4 技术选型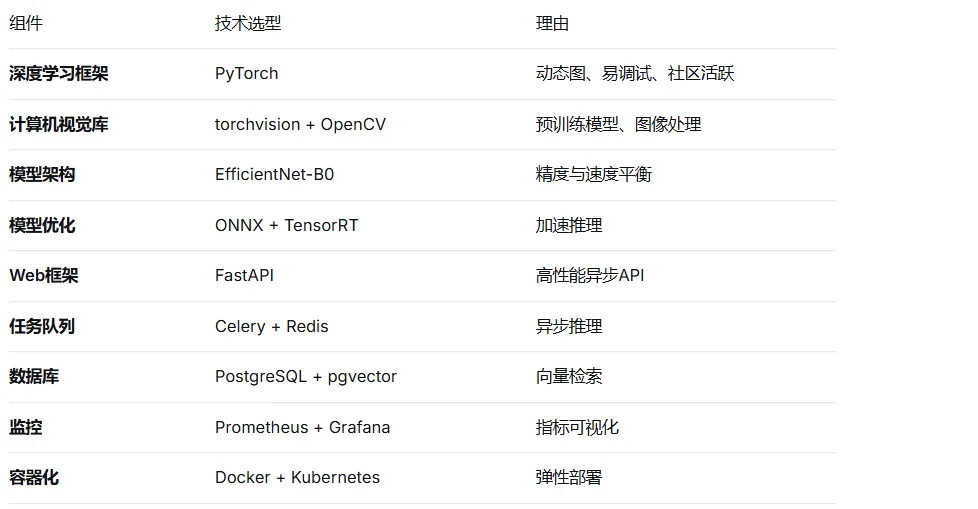
第二部分:环境搭建与数据准备
2.1 项目结构
ai-product-classifier/
├── README.md
├── requirements.txt
├── .env.example
├── docker-compose.yml
│
├── config/ # 配置文件
│ ├── __init__.py
│ ├── settings.py
│ └── model_config.yaml
│
├── data/ # 数据目录
│ ├── raw/ # 原始图片
│ ├── processed/ # 处理后图片
│ ├── train/ # 训练集
│ ├── val/ # 验证集
│ └── test/ # 测试集
│
├── notebooks/ # Jupyter Notebook
│ ├── 01_data_exploration.ipynb
│ ├── 02_model_training.ipynb
│ └── 03_model_evaluation.ipynb
│
├── src/ # 源代码
│ ├── __init__.py
│ ├── data/ # 数据处理
│ │ ├── dataset.py
│ │ ├── augmentations.py
│ │ └── preprocessing.py
│ ├── models/ # 模型定义
│ │ ├── __init__.py
│ │ ├── efficientnet.py
│ │ ├── resnet.py
│ │ └── ensemble.py
│ ├── train/ # 训练相关
│ │ ├── trainer.py
│ │ ├── metrics.py
│ │ └── callbacks.py
│ ├── inference/ # 推理相关
│ │ ├── predictor.py
│ │ ├── onnx_predictor.py
│ │ └── tensorrt_predictor.py
│ ├── api/ # API服务
│ │ ├── app.py
│ │ ├── routes.py
│ │ └── schemas.py
│ ├── tasks/ # 异步任务
│ │ ├── celery_app.py
│ │ └── inference_tasks.py
│ └── utils/ # 工具函数
│ ├── logger.py
│ ├── metrics.py
│ └── viz.py
│
├── models/ # 保存的模型
│ ├── best_model.pth
│ ├── best_model.onnx
│ └── labels.json
│
├── scripts/ # 脚本
│ ├── download_data.py
│ ├── train.py
│ ├── evaluate.py
│ ├── export_onnx.py
│ └── benchmark.py
│
├── tests/ # 测试
│ ├── test_data.py
│ ├── test_model.py
│ └── test_api.py
│
└── deploy/ # 部署配置
├── Dockerfile
├── Dockerfile.cpu
├── Dockerfile.gpu
└── kubernetes/
2.2 环境配置
# 创建虚拟环境
python -m venv venv
source venv/bin/activate # Linux/Mac
# venv\Scripts\activate # Windows
# 安装依赖
pip install -r requirements.txt
# requirements.txt
# ========== 深度学习框架 ==========
torch==2.1.0
torchvision==0.16.0
torchaudio==2.1.0
# ========== 模型优化 ==========
onnx==1.14.0
onnxruntime-gpu==1.16.0 # GPU版本
# onnxruntime==1.16.0 # CPU版本
tensorrt==8.6.1 # NVIDIA TensorRT
# ========== 计算机视觉 ==========
opencv-python==4.8.1
pillow==10.1.0
scikit-image==0.22.0
albumentations==1.3.1
# ========== 数据处理 ==========
numpy==1.24.3
pandas==2.1.0
scikit-learn==1.3.0
# ========== Web框架 ==========
fastapi==0.104.0
uvicorn[standard]==0.24.0
python-multipart==0.0.6
# ========== 异步任务 ==========
celery==5.3.4
redis==5.0.1
# ========== 数据库 ==========
psycopg2-binary==2.9.9
sqlalchemy==2.0.22
# ========== 监控 ==========
prometheus-client==0.19.0
# ========== 工具 ==========
python-dotenv==1.0.0
loguru==0.7.2
tqdm==4.66.1
mlflow==2.8.0 # 实验跟踪
wandb==0.15.12 # 实验跟踪(可选)
# ========== 开发工具 ==========
jupyter==1.0.0
ipython==8.17.0
pytest==7.4.3
black==23.11.0
flake8==6.1.0
mypy==1.7.0
2.3 数据准备
# scripts/download_data.py
"""
下载数据集脚本
使用公开数据集 Fashion Product Images (Kaggle)
包含 44,000 张商品图片,44个类别
"""
import os
import zipfile
import requests
from tqdm import tqdm
from pathlib import Path
def download_file(url, dest_path):
"""下载文件并显示进度条"""
response = requests.get(url, stream=True)
total_size = int(response.headers.get('content-length', 0))
with open(dest_path, 'wb') as f:
with tqdm(total=total_size, unit='B', unit_scale=True, desc=dest_path.name) as pbar:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
pbar.update(len(chunk))
def extract_zip(zip_path, extract_to):
"""解压ZIP文件"""
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
zip_ref.extractall(extract_to)
def organize_dataset(data_dir):
"""
组织数据集结构
原始结构:
data/raw/
├── images/
│ ├── 1.jpg
│ └── ...
└── styles.csv # 标签文件
目标结构:
data/
├── train/
│ ├── category1/
│ │ ├── image1.jpg
│ │ └── ...
│ └── category2/
├── val/
└── test/
"""
import pandas as pd
import shutil
from sklearn.model_selection import train_test_split
# 读取标签
labels_df = pd.read_csv(data_dir / 'raw' / 'styles.csv')
# 创建类别目录
categories = labels_df['masterCategory'].unique()
# 划分训练集、验证集、测试集
train_df, temp_df = train_test_split(labels_df, test_size=0.3, random_state=42, stratify=labels_df['masterCategory'])
val_df, test_df = train_test_split(temp_df, test_size=0.5, random_state=42, stratify=temp_df['masterCategory'])
# 复制文件到对应目录
for split, df in [('train', train_df), ('val', val_df), ('test', test_df)]:
for _, row in df.iterrows():
src = data_dir / 'raw' / 'images' / f"{row['id']}.jpg"
dst = data_dir / split / row['masterCategory'] / f"{row['id']}.jpg"
dst.parent.mkdir(parents=True, exist_ok=True)
shutil.copy(src, dst)
print(f"数据集划分完成:")
print(f" 训练集: {len(train_df)} 张图片, {train_df['masterCategory'].nunique()} 个类别")
print(f" 验证集: {len(val_df)} 张图片")
print(f" 测试集: {len(test_df)} 张图片")
if __name__ == '__main__':
data_dir = Path('data')
data_dir.mkdir(exist_ok=True)
# 下载数据集(需要Kaggle API)
# 这里使用示例数据,实际项目中需要下载真实数据
print("请下载数据集到 data/raw/ 目录")

