
下载地址:http://lanzou.co/ib7119f02
项目编译入口:
package.json
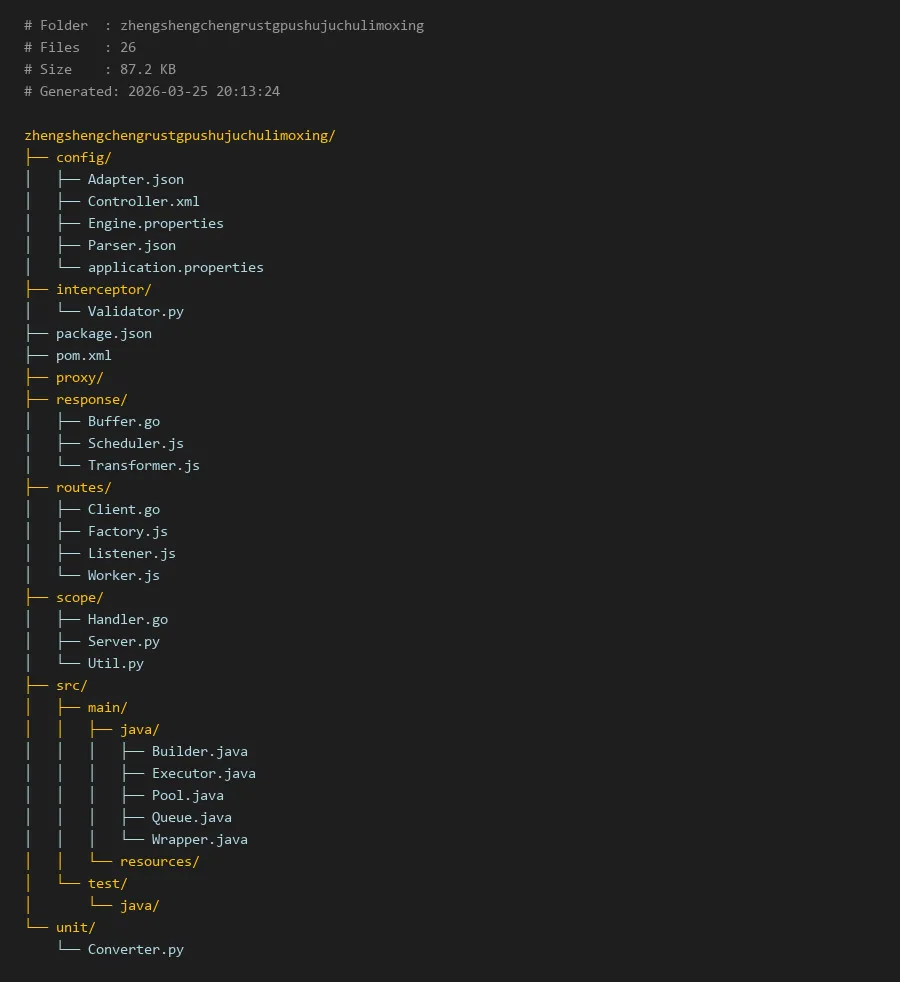
# Folder : zhengshengchengrustgpushujuchulimoxing
# Files : 26
# Size : 87.2 KB
# Generated: 2026-03-25 20:13:24
zhengshengchengrustgpushujuchulimoxing/
├── config/
│ ├── Adapter.json
│ ├── Controller.xml
│ ├── Engine.properties
│ ├── Parser.json
│ └── application.properties
├── interceptor/
│ └── Validator.py
├── package.json
├── pom.xml
├── proxy/
├── response/
│ ├── Buffer.go
│ ├── Scheduler.js
│ └── Transformer.js
├── routes/
│ ├── Client.go
│ ├── Factory.js
│ ├── Listener.js
│ └── Worker.js
├── scope/
│ ├── Handler.go
│ ├── Server.py
│ └── Util.py
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Builder.java
│ │ │ ├── Executor.java
│ │ │ ├── Pool.java
│ │ │ ├── Queue.java
│ │ │ └── Wrapper.java
│ │ └── resources/
│ └── test/
│ └── java/
└── unit/
└── Converter.py
zhengshengchengrustgpushujuchulimoxing:GPU数据处理模型的技术实现
简介
zhengshengchengrustgpushujuchulimoxing是一个专注于GPU加速数据处理的技术框架,采用多语言混合架构设计,充分利用各种编程语言在特定领域的优势。该项目通过模块化设计实现了数据处理、任务调度、模型适配等核心功能,特别适合大规模数据并行处理场景。
框架的核心设计理念是将数据处理流程分解为可配置的组件,通过配置文件动态组合处理管道,同时利用GPU的并行计算能力加速数据处理过程。项目结构清晰,各目录承担特定职责,便于维护和扩展。
核心模块说明
项目主要包含以下几个核心模块:
- config/ - 配置文件目录,包含各种组件的配置参数
- interceptor/ - 拦截器模块,负责数据验证和预处理
- proxy/ - 代理层,处理网络通信和数据转发
- response/ - 响应处理模块,包含缓冲、调度和转换功能
- routes/ - 路由模块,定义数据处理流程和任务分发
- scope/ - 作用域管理模块,处理请求生命周期和资源管理
每个模块使用最适合其任务特性的编程语言实现,例如Go语言用于高性能网络处理,Python用于数据验证,JavaScript用于任务调度等。
代码示例
配置文件示例
首先,让我们查看主要的配置文件结构。application.properties定义了全局配置:
# GPU数据处理模型全局配置
gpu.enabled=true
gpu.device.count=4
gpu.memory.per.device=8192
data.batch.size=1024
data.pipeline.workers=8
data.compression.enabled=true
model.cache.size=2048
model.update.interval=3600
logging.level=INFO
logging.path=/var/log/gpu-processor/
Engine.properties配置计算引擎参数:
# 计算引擎配置
engine.type=cuda
engine.version=11.0
engine.max_threads_per_block=1024
engine.shared_memory_size=49152
kernel.optimization.level=3
kernel.cache.enabled=true
kernel.precompile=true
memory.pinned.enabled=true
memory.stream.count=4
数据验证拦截器
interceptor/Validator.py实现数据格式验证:
import json
import numpy as np
from typing import Dict, Any, Optional
class DataValidator:
def __init__(self, config_path: str):
with open(config_path, 'r') as f:
self.config = json.load(f)
self.schema = self.config.get("data_schema", {
})
self.thresholds = self.config.get("validation_thresholds", {
})
def validate_batch(self, data_batch: Dict[str, Any]) -> Dict[str, Any]:
"""验证数据批次"""
validation_result = {
"is_valid": True,
"errors": [],
"warnings": [],
"processed_count": 0
}
# 检查数据维度
if "tensor_data" in data_batch:
tensor_data = data_batch["tensor_data"]
expected_shape = self.schema.get("tensor_shape")
if expected_shape and tensor_data.shape != tuple(expected_shape):
validation_result["is_valid"] = False
validation_result["errors"].append(
f"Tensor shape mismatch: expected {expected_shape}, got {tensor_data.shape}"
)
# 检查数值范围
if "metadata" in data_batch:
metadata = data_batch["metadata"]
for key, value in metadata.items():
threshold = self.thresholds.get(key)
if threshold:
min_val, max_val = threshold
if value < min_val or value > max_val:
validation_result["warnings"].append(
f"Value {key}={value} outside threshold [{min_val}, {max_val}]"
)
if validation_result["is_valid"]:
validation_result["processed_count"] = len(data_batch.get("items", []))
return validation_result
def normalize_data(self, data: np.ndarray) -> np.ndarray:
"""数据标准化"""
mean = self.schema.get("normalization_mean", 0.0)
std = self.schema.get("normalization_std", 1.0)
if std > 0:
return (data - mean) / std
return data
GPU数据处理路由
routes/Worker.js实现GPU工作线程管理:
```javascript
const { EventEmitter } = require('events');
class GPUWorker extends EventEmitter {
constructor(workerId, gpuConfig) {
super();
this.workerId = workerId;
this.gpuConfig = gpuConfig;
this.isBusy = false;
this.taskQueue = [];
this.results = new Map();
this.initGPUContext();
}
initGPUContext() {
// 初始化GPU上下文
this.gpuContext = {
deviceId: this.workerId % this.gpuConfig.deviceCount,
memoryLimit: this.gpuConfig.memoryPerDevice,
stream: null,
kernelCache: new Map()
};
console.log(`Worker ${this.workerId}: GPU context initialized on device ${this.gpuContext.deviceId}`);
}
async processTask(task) {
this.isBusy = true;
try {
const { taskId, operation, data, parameters } = task;

