


谷歌(微博)自主开发定制化芯片,以加速其机器学习算法,这已不是什么秘密了。早在2016年5月,该公司就在其I/O开发者大会上首次公布了这款名为Tensor Processing Units(简称TPU)的芯片。但是,该公司从未详细地介绍过它们,只是声称这些芯片是专门为其TensorFlow机器学习框架度身定做的。
但是在周三,谷歌首次详细地介绍了这种芯片的相关信息。
谷歌的大卫-帕特森(David Patterson)不仅与人联合发表了有关TPU芯片的文章,而且在美国国家工程院于加利福尼亚州山景城举行的一次活动中作了相关演讲。这篇有关TPU芯片的文章总共有高达75名联合署名作者。
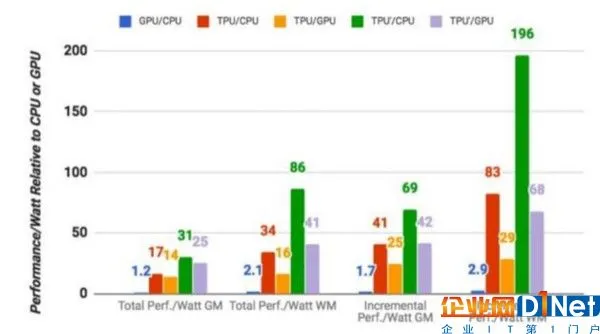
芯片设计师可以上述文章中找到详细的有关TPU的运行原理。根据谷歌自己的衡量标准,TPU执行谷歌一般机器学习任务的平均速度是标准GPU/CPU芯片(这里指英特尔Haswell芯片和英伟达K80 GPU)的15到30倍。由于数据中心的耗电量也是一个重要的考量,TPU的每瓦计算能力是GPU/CPU芯片的30到80倍。
谷歌还指出,虽然大多数工程师针对卷积神经网络改造了其芯片,但是这些网络仅占谷歌数据中心工作量的大约5%,因为该公司的大多数应用程序均使用多层感知器神经网络。
谷歌声称,早在2006年,它就开始研究如何在其数据中心使用GPU、FPGA(现场可编程门阵列)和定制化ASIC(实际上就是TPU)。但是在当时,并没有多少应用程序可以从这种特殊的芯片受益,因为大多数任务均可以通过数据中心提供的额外的芯片进行处理。
“在2013年,情况发生了改变。我们预计,由于深度神经网络(DNN)变得如何非常流行,它可能要求我们把数据中心的计算能力提高一倍。如果采用传统的CPU芯片,成本就会变得极其昂贵。”谷歌在其文件中称,“因此,我们开始优先开发定制化ASIC。”
谷歌研究人员称,他们的目标就是“将其性价比提高到GPU芯片的10倍。”
谷歌从2015年起就一直在公司内部使用TPU芯片,而且它以后也可能只会让自己使用这种芯片。但是该公司指出,它希望其他公司能够借鉴吸收它的研究成果,“打造下一代更高标准的芯片”。
在过去五年中,AMD和英伟达等公司的GPU芯片已成为了经济型深度学习技术的默认基础架构。但是,谷歌、微软和其他公司还开始探索其他类型的芯片,包括处理各种不同人工智能任务的FPGA。谷歌知名硬件工程师诺姆-久皮(Norm Jouppi)在一篇博文中称,谷歌的TPU芯片已开始支持Google Image Search(图片搜索)、Google Photos(谷歌照片)和Google Cloud Vision(图像识别平台)应用编程接口等等。
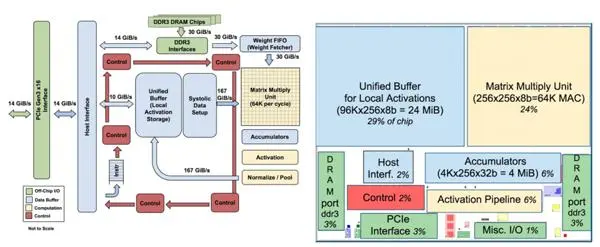
相对而言,TPU芯片的单片存储器容量是英伟达K80 GPU的3.5倍,但是它的体积相对更小。目前,谷歌可以在一台服务器中整合两个TPU芯片。
“为了减少延缓部署的概率,TPU芯片并没有与CPU进行整合,而是被设计成PCIe I/O总线上的协处理器。这使得它能够直接插入现有的服务器中,就像GPU芯片一样。而且,为了让硬件设计和故障排除过程变得更为简单,托管服务器会发送指令给TPU芯片执行,而不是让TPU芯片自己获取指令。因此,从设计理念上来说,TPU芯片更接近于FPU协处理器,而不是GPU。”上述文章称。
本文转自d1net(转载)



