Hibernate查询语言(HQL)是一种面向对象的查询语言,它模仿了SQL的语法,但与SQL有着本质的区别。本文将对比HQL与SQL,探讨HQL作为SQL替代品的优势,并通过示例代码展示HQL在实际应用中的便捷性。
SQL(Structured Query Language)是一种广泛使用的数据库查询语言,它主要用于关系型数据库管理系统。SQL语句直接操作数据库表和视图,通过关键字、条件表达式和函数等实现对数据的查询、更新、插入和删除操作。以下是一个简单的SQL查询示例:
SELECT * FROM employee WHERE age > 30;
与此相比,HQL(Hibernate Query Language)是Hibernate框架提供的一种查询语言,它更加面向对象。HQL查询的是对象及其属性,而不是数据库表和列。以下是一个与上述SQL示例等效的HQL查询:
String hql = "FROM Employee e WHERE e.age > 30";
Query query = session.createQuery(hql);
List results = query.list();
从上述示例可以看出,HQL与SQL在语法上的相似性,但它们在以下几个方面存在显著差异:
- 操作对象不同:SQL操作的是数据库表和列,而HQL操作的是持久化类及其属性。这使得HQL更加符合面向对象编程的思想,降低了程序员在编写查询时的复杂性。
- 类型安全:HQL在编译时就能检查出类型错误,而SQL在运行时才能发现错误。这提高了程序的健壮性,减少了运行时错误。
- 易于维护:由于HQL与Java类的属性直接关联,当数据库表结构发生变化时,只需修改映射文件,无需修改HQL语句。而SQL语句则需要根据表结构的变动进行相应调整。
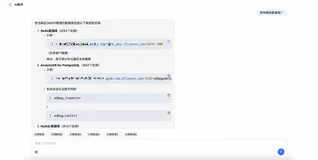
以下是一个更复杂的HQL查询示例,展示了HQL在关联查询方面的优势:
对应的SQL查询可能如下:String hql = "SELECT DISTINCT e FROM Employee e JOIN e.department d WHERE d.name = '研发部'"; Query query = session.createQuery(hql); List<Employee> employees = query.list();
从上述示例可以看出,HQL在处理关联查询时更加直观,易于理解。而SQL则需要编写复杂的JOIN语句,容易出错。SELECT DISTINCT e.* FROM employee e JOIN department d ON e.department_id = d.id WHERE d.name = '研发部';
此外,HQL还具备以下优势: - 支持面向对象的高级特性:如继承、多态等,这使得HQL在处理复杂业务逻辑时更加得心应手。
- 内置大量函数和聚合操作:HQL提供了丰富的内置函数,如SUM、AVG、MAX等,方便进行数据统计和分析。
- 灵活的查询结果:HQL支持查询结果的投影,可以轻松实现查询部分属性或计算新的属性值。
总之,Hibernate查询语言HQL作为一种面向对象的查询语言,在很大程度上可以替代SQL。它简化了数据库操作,提高了开发效率,降低了维护成本。在实际项目中,合理使用HQL将有助于我们更好地实现业务需求。然而,需要注意的是,HQL并非万能,对于一些复杂的数据库操作,SQL仍然具有不可替代的优势。因此,在实际开发中,应根据具体场景选择合适的查询语言。