Highlight
- 新发布Serverless Computing,提升大任务稳定性,同时可降低20%计算成本
- 引擎性能优化,TPC-H 1TB测试相对V1.X 提升100%
- 实时湖仓加速架构升级,支持Paimon,直读ORC、Parquet数据性能提升5倍以上
- 新增实例监控指标,可观测性全面提升,新增SQL指纹、Query洞察、SQL 与表索引诊断等
- 流量分析场景新增路径函数,支持跨可用区容灾、OpenAPI能力升级
升级说明:Hologres支持热升级,可以在实例后台进行自助升级与升级准备。升级流程请查看>>>
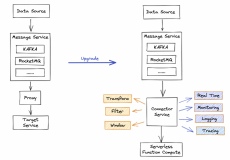
一、新发布Serverless Computing,提供大作业隔离与弹性处理
功能说明:
通过共享Serverless资源执行DML任务,保证大任务隔离与高可用,降低成本并提升性能。同时支持设置单条SQL使用Serverless的资源上限,支持设置使用Serverless资源的SQL优先级。详细请查看>>>
应用场景:
- 隔离与稳定性。计算资源开销大的任务,不会有争抢资源,OOM等问题。
- 成本降低。无需为大任务单独购买预付费资源,实际应用可降低20%计算成本。

当前发布地域和可用区:华东1(杭州)的可用区J、华南1(深圳)的可用区F、华东2(上海)的可用区E、华北2(北京)的可用区I。
二、多种引擎能力优化,TPC-H 性能测试结果提升 100%
Hologres V2.2 提升了查询优化器和查询引擎的能力,1.1 版本使用 96CU 在 TPC-H 1T 的总查询耗时为 223.08 秒,在V2.2版本中,测试结果为111.53 秒,性能提升达到100%。详细结果请查看>>>

引擎性能优化包含:
向量执行引擎HQE能力提升
- Runtime Filter能力增强,在Join场景上,支持多种过滤类型,无需手动设置,引擎自适应,在减少数据扫描量的同时也能减少join的计算量和数据的网络传输量,有效提升Join的查询效率约30%。
- 优化HQE的RPC连边机制,每个Worker内数据先合并再进行Worker间分发,显著降低网络开销,在带有Shuffle的场景上,查询性能提升8%。
查询优化器性能提升,SQL在Plan阶段的处理速度提升40%
- 优化内存分配机制和Join算法,提升多Join场景的查询性能。
- 优化DATE_PART函数行为,提升对带有时间属性的字段(如年份)的查询效率。
- 优化DATE和TIMESTAMP类型字段的比较行为,提升时间字段的查询效率。
- 优化复杂函数中带有Filter的运算行为,通过调整多个Filter的顺序,减少数据计算量,提升查询效率。
三、实时湖仓架构升级,性能提升5倍,外表元数据自动加载提升分析体验
HologresV2.2版本针对实时湖仓架构进行重构,显著提升了数据湖的查询性能,并通过外表元数据自动加载(Auto Load) 提升实时湖仓的用户使用体验。
实时湖仓架构升级包含:
- 实现HQE引擎直读OSS上的ORC、Parquet数据,相较于原引擎有5倍以上的性能提升
- 针对ORC、Parquet格式的外部表支持谓词下推过滤,减少数据扫描量,提升查询效率
- 支持使用内置高速磁盘和内存实现多级缓存
外表元数据自动加载(Auto Load)能力增强:
支持一键绑定外部数据源,实现DB或者schema级别的映射,简化和降低外表创建成本,包含:
- 支持MaxCompute三层模型Project,可以将MaxCompute三层Project中的一个或多个指定schema 数据按需或者全量映射到Hologres
- 支持MaxCompute外部表的Schema Evolution(如增加列、删除列、修改列名及列顺序)
- 支持通过DLF元数据自动加载,来加速查询存储于OSS的数据

四、实例诊断能力提升,新增SQL指纹、Query洞察、SQL 与表索引诊断等
新增SQL指纹,快速定位Bad Query
SQL指纹是Hologres提供的一种自动Query聚类分析能力。V2.2版本在存放慢Query查询日志的系统表中,新增digest列以展示SQL指纹。对于SELECT/INSERT/DELETE/UPDATE类型的Query,系统会计算一个MD5哈希值作为该Query的SQL指纹,帮助业务快速识别占用资源的Query以及异常Query等。详情请查看>>>
新增Query洞察可视化,全方位获取查询诊断信息
在holoweb-诊断与优化中,通过Query ID就能快速获取当前Query的执行信息,例如Query进程的资源消耗、Query所涉及的表的元数据,以及Query对应的执行计划(plan)。同时可以通过Query洞察快速判断当前Query是否产生了DDL冲突,以及表锁情况,辅助业务进一步排查问题和处理问题。详情请查看>>>

新增SQL诊断和表索引诊断,快速完成实例治理
在holoweb-诊断与优化中,SQL诊断通过对不同维度的Query趋势、明细分析,可以辅助您了解实例的使用情况并做相应的优化,以达到更好的效果。详情请查看>>>

在holoweb-诊断与优化中,表索引诊断对当前实例的Table Group、表、索引等进行诊断,帮助业务进行实例治理,从而辅助提升实例的稳定性和性能。例如:
- 一个Table Group的内表总数不建议超过1W张,优化后将提升DDL性能。
- 对于分区子表超过1W张的分区表,建议使用冷热分层 ,以节约存储成本。

实例监控信息新增15+Metrics,可观测性得到增强
在实例列表-监控信息中,新增15+metric指标,提供不同执行引擎的QPS、RPS、Latencty等以及可观测Binlog、Serverless等功能的运行情况,以方便及时了解任务的负载。同时也提供Locks、Analyze等健康度指标,可以帮助业务快速观测实例运行健康状态,及时处理异常。

五、新增路径分析函数,更加丰富流量分析场景函数能力
在流量分析场景,需要计算访问每个流程/步骤的路径分布和情况,以及每个步骤的流入流出情况,原有SQL计算方式较为复杂,并且影响计算性能。Hologres通过一个路径分析函数即可实现路径分析,简化用户路径分析流程,与之前推出的漏斗函数、留存函数、明细圈人函数、Roaring Bitmap函数、BSI函数等结合,实现完整、丰富的流量数据分析方案。详情请查看>>>

六、支持跨可用区容灾,提升生产业务稳定性
跨可用区(AZ)容灾,即在同Region不同可用区部署同构的Hologres容灾实例,如果生产实例所处的地理位置发生自然灾害,或者实例内部出现了故障导致生产实例无法正常对外提供读写服务,那么容灾实例可以切换为生产实例,从而保障业务连续性。详情请查看>>>
例如:杭州Region某个可用区(例如可用区H)中的Hologres实例无法正常运行时,可通过已配置的容灾关系,将同Region其他可用区(例如可用区J)的Hologres实例切换为生产实例,保障业务正常运行。
七、OpenAPI能力升级,提升实例运维管理能力
新增计算组列表与详情、数据湖加速功能、更新实例资源组等OpenAPI,在severless、数据湖分析等场景下,提升实例运维以及管理能力。详情请查看>>>