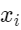作者:Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
时间:2017

首先,transformer模型架构起初是由Vaswani等人在2017年一篇名为 "Attention is all you need"的论文中提出来的;其本质是利用self-attention去代替循环神经网络RNN和卷积神经网络CNN的一种sequence-to-sequence,encoder-decoder神经网络模型;
一、完整代码
这里使用基础tensorflow代码来构建一个transformer模型
import tensorflow as tf import keras_nlp import matplotlib.pyplot as plt import numpy as np plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False # 准备dataset dataset = tf.data.TextLineDataset('data.tsv') def process_data(x): res = tf.strings.split(x, '\t') return res[1], res[3] dataset.map(process_data).take(1).get_single_element() dataset = dataset.map(process_data).batch(64) vocab_chinese = keras_nlp.tokenizers.compute_word_piece_vocabulary( dataset.map(lambda x, y: x), vocabulary_size=20000, lowercase=True, strip_accents=True, split_on_cjk=True, reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"], ) vocab_english = keras_nlp.tokenizers.compute_word_piece_vocabulary( dataset.map(lambda x, y: y), vocabulary_size=20000, lowercase=True, strip_accents=True, split_on_cjk=True, reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"], ) chinese_tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(vocabulary=vocab_chinese, oov_token="[UNK]") english_tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(vocabulary=vocab_english, oov_token="[UNK]") def process_data_(ch, en, maxtoken=128): ch = chinese_tokenizer(ch)[:,:maxtoken] en = english_tokenizer(tf.strings.lower(en))[:,:maxtoken] ch = tf.concat([tf.ones(shape=(64,1), dtype='int32'), ch, tf.ones(shape=(64,1), dtype='int32')*2], axis=-1).to_tensor() en = tf.concat([tf.ones(shape=(64,1), dtype='int32'), en, tf.ones(shape=(64,1), dtype='int32')*2], axis=-1) en_inputs = en[:, :-1].to_tensor() # Drop the [END] tokens en_labels = en[:, 1:].to_tensor() # Drop the [START] tokens return (ch, en_inputs), en_labels dataset = dataset.batch(64).map(process_data_) train_dataset = dataset.take(1000) val_dataset = dataset.skip(500).take(300) # 定义Transformer def positional_encoding(length, depth): depth = depth/2 positions = np.arange(length)[:, np.newaxis] # (seq, 1) depths = np.arange(depth)[np.newaxis, :]/depth # (1, depth) angle_rates = 1 / (10000**depths) # (1, depth) angle_rads = positions * angle_rates # (pos, depth) pos_encoding = np.concatenate([np.sin(angle_rads), np.cos(angle_rads)],axis=-1) return tf.cast(pos_encoding, dtype=tf.float32) class PositionEmbedding(tf.keras.layers.Layer): def __init__(self, vocabulary_size, d_model): super().__init__() self.d_model = d_model self.embedding = tf.keras.layers.Embedding(vocabulary_size, d_model, mask_zero=True) self.pos_encoding = positional_encoding(length=2048, depth=d_model) def compute_mask(self, *args, **kwargs): return self.embedding.compute_mask(*args, **kwargs) def call(self, x): length = tf.shape(x)[1] x = self.embedding(x) x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32)) x = x + self.pos_encoding[tf.newaxis, :length, :] return x class BaseAttention(tf.keras.layers.Layer): def __init__(self, **kwargs): super().__init__() self.mha = tf.keras.layers.MultiHeadAttention(**kwargs) self.layernorm = tf.keras.layers.LayerNormalization() self.add = tf.keras.layers.Add() class CrossAttention(BaseAttention): def call(self, x, context): attn_output, attn_scores = self.mha( query=x, key=context, value=context, return_attention_scores=True) # Cache the attention scores for plotting later. self.last_attn_scores = attn_scores x = self.add([x, attn_output]) x = self.layernorm(x) return x class GlobalSelfAttention(BaseAttention): def call(self, x): attn_output = self.mha( query=x, value=x, key=x) x = self.add([x, attn_output]) x = self.layernorm(x) return x class CausalSelfAttention(BaseAttention): def call(self, x): attn_output = self.mha( query=x, value=x, key=x, use_causal_mask = True) x = self.add([x, attn_output]) x = self.layernorm(x) return x class FeedForward(tf.keras.layers.Layer): def __init__(self, d_model, dff, dropout_rate=0.1): super().__init__() self.seq = tf.keras.Sequential([ tf.keras.layers.Dense(dff, activation='relu'), tf.keras.layers.Dense(d_model), tf.keras.layers.Dropout(dropout_rate) ]) self.add = tf.keras.layers.Add() self.layer_norm = tf.keras.layers.LayerNormalization() def call(self, x): x = self.add([x, self.seq(x)]) x = self.layer_norm(x) return x class EncoderLayer(tf.keras.layers.Layer): def __init__(self, *, d_model, num_heads, dff, dropout=0.1): super().__init__() self.self_attention = GlobalSelfAttention( num_heads = num_heads, key_dim = d_model, dropout = dropout ) self.ffn = FeedForward(d_model, dff) def call(self, x): x = self.self_attention(x) x = self.ffn(x) return x class Encoder(tf.keras.layers.Layer): def __init__(self, *, vocabulary_size, d_model, num_heads, dff, num_layers=6, dropout=0.1): super().__init__() # 给Encoder添加属性,便于辨识 self.d_model = d_model self.num_layers = num_layers self.pos_embedding = PositionEmbedding(vocabulary_size, d_model) self.encoder_layers = [EncoderLayer(d_model=d_model, num_heads=num_heads, dff=dff, dropout=dropout) for _ in range(num_layers)] self.dropout = tf.keras.layers.Dropout(dropout) def call(self, x): x = self.pos_embedding(x) x = self.dropout(x) for encoder_layer in self.encoder_layers: x = encoder_layer(x) return x class DecoderLayer(tf.keras.layers.Layer): def __init__(self, *, d_model, num_heads, dff, dropout=0.1): super().__init__() self.causal_self_attention = CausalSelfAttention(num_heads=num_heads, key_dim=d_model, dropout=dropout) self.cross_attention = CrossAttention(num_heads=num_heads, key_dim=d_model, dropout=dropout) self.ffn = FeedForward(d_model, dff) def call(self, x, context): x = self.causal_self_attention(x) x = self.cross_attention(x, context) # 这里存储最后的注意力分数为了后面的画图 self.last_attn_scores = self.cross_attention.last_attn_scores x = self.ffn(x) return x class Decoder(tf.keras.layers.Layer): def __init__(self, *, vocabulary_size, d_model, num_heads, dff, num_layers=6, dropout=0.1): super(Decoder, self).__init__() self.d_model = d_model self.num_layers = num_layers self.pos_embedding = PositionEmbedding(vocabulary_size=vocabulary_size, d_model=d_model) self.decoder_layers = [DecoderLayer(d_model=d_model, num_heads=num_heads, dff=dff, dropout=dropout) for _ in range(num_layers)] self.dropout = tf.keras.layers.Dropout(rate=dropout) self.last_attn_scores = None def call(self, x, content): x = self.pos_embedding(x) x = self.dropout(x) for decoder_layer in self.decoder_layers: x = decoder_layer(x, content) self.last_attn_scores = self.decoder_layers[-1].last_attn_scores return x class Transformer(tf.keras.Model): def __init__(self, *, num_layers, d_model, num_heads, dff, input_vocabulary_size, target_vocabulary_size, dropout=0.1): super().__init__() self.encoder = Encoder(vocabulary_size=input_vocabulary_size, d_model=d_model, num_layers=num_layers, num_heads=num_heads, dff=dff) self.decoder = Decoder(vocabulary_size=target_vocabulary_size, d_model=d_model, num_layers=num_layers, num_heads=num_heads, dff=dff) self.final_layer = tf.keras.layers.Dense(target_vocabulary_size, activation='softmax') def call(self, inputs): context, x = inputs context = self.encoder(context) x = self.decoder(x, context) logits = self.final_layer(x) # 不太理解 try: # Drop the keras mask, so it doesn't scale the losses/metrics. # b/250038731 del logits._keras_mask except AttributeError: pass return logits # 定义超参 num_layers = 4 d_model = 128 dff = 512 num_heads = 8 dropout = 0.1 MAX_TOKENS = 128 # 准备模型 model = Transformer(num_layers=num_layers, d_model=d_model, num_heads=num_heads, dff=dff, input_vocabulary_size=chinese_tokenizer.vocabulary_size(), target_vocabulary_size=english_tokenizer.vocabulary_size(), dropout=dropout) # build模型 (ch, input_en), output_en = dataset.take(1).get_single_element() model.predict((ch, input_en)).shape model.summary() # 模型loss,optimizer定义 class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule): def __init__(self, d_model, warmup_steps=4000): super().__init__() self.d_model = d_model self.d_model = tf.cast(self.d_model, tf.float32) self.warmup_steps = warmup_steps def __call__(self, step): step = tf.cast(step, dtype=tf.float32) arg1 = tf.math.rsqrt(step) arg2 = step * (self.warmup_steps ** -1.5) return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2) learning_rate = CustomSchedule(d_model) optimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98, epsilon=1e-9) def masked_loss(label, pred): mask = label != 0 loss_object = tf.keras.losses.SparseCategoricalCrossentropy(reduction='none') loss = loss_object(label, pred) mask = tf.cast(mask, dtype=loss.dtype) loss *= mask loss = tf.reduce_sum(loss)/tf.reduce_sum(mask) return loss def masked_accuracy(label, pred): pred = tf.argmax(pred, axis=2) label = tf.cast(label, pred.dtype) match = label == pred mask = label != 0 match = match & mask match = tf.cast(match, dtype=tf.float32) mask = tf.cast(mask, dtype=tf.float32) return tf.reduce_sum(match)/tf.reduce_sum(mask) model.compile( loss=masked_loss, optimizer=optimizer, metrics=[masked_accuracy]) # 训练模型 model.fit(train_dataset, epochs=10, validation_data=val_dataset) # 推理 class Translator(tf.Module): def __init__(self, tokenizers, transformer): self.tokenizers = tokenizers self.transformer = transformer def __call__(self, sentence, max_length=MAX_TOKENS): # sentence是中文,因此需要tokenizer并且加上<start>:1和<end>:2 assert isinstance(sentence, tf.Tensor) if len(sentence.shape) == 0: sentence = sentence[tf.newaxis] sentence = self.tokenizers(sentence) sentence = tf.concat([tf.ones(shape=[sentence.shape[0], 1], dtype='int32'), sentence, tf.ones(shape=[sentence.shape[0], 1], dtype='int32')*2], axis=-1).to_tensor() encoder_input = sentence # As the output language is English, initialize the output with the start = tf.constant(1, dtype='int64')[tf.newaxis] end = tf.constant(2, dtype='int64')[tf.newaxis] # tf.TensorArray 类似于python中的列表 output_array = tf.TensorArray(dtype=tf.int64, size=0, dynamic_size=True) # 在index=0的位置写入start output_array = output_array.write(0, start) for i in tf.range(max_length): output = tf.transpose(output_array.stack()) predictions = self.transformer([encoder_input, output], training=False) # Shape `(batch_size, seq_len, vocab_size)` # 从seq_len中的最后一个维度选择last token predictions = predictions[:, -1:, :] # Shape `(batch_size, 1, vocab_size)`. predicted_id = tf.argmax(predictions, axis=-1) # `predicted_id`加入到output_array中作为一个新的输入 output_array = output_array.write(i+1, predicted_id[0]) # 如果输出end就表明停止 if predicted_id == end: break output = tf.transpose(output_array.stack()) # 重新计算一下最外面的循环,得到最后的注意力得分 self.transformer([encoder_input, output[:,:-1]], training=False) attention_weights = self.transformer.decoder.last_attn_scores lst = [] for item in output[0].numpy(): lst.append(english_tokenizer.vocabulary[item]) translated_text = ' '.join(lst) translated_tokens = output[0] return translated_text, translated_tokens, attention_weights translator = Translator(chinese_tokenizer, model) # 普通推理 def print_translation(sentence, tokens, ground_truth): print(f'{"Input:":15s}: {sentence}') print(f'{"Prediction":15s}: {tokens}') print(f'{"Ground truth":15s}: {ground_truth}') sentence = '我們試試看!' ground_truth = "Let's try it." translated_text, translated_tokens, attention_weights = translator(tf.constant(sentence)) print_translation(sentence, translated_text, ground_truth) # 注意力可视化 def plot_attention_head(in_tokens, translated_tokens, attention): # 模型在输出中不产生<START>,我们直接忽略 translated_tokens = translated_tokens[1:] ax = plt.gca() ax.matshow(attention) ax.set_xticks(range(len(in_tokens))) ax.set_yticks(range(len(translated_tokens))) labels = [vocab_chinese[label] for label in in_tokens.numpy()] ax.set_xticklabels(labels, rotation=90) labels = [vocab_english[label] for label in translated_tokens.numpy()] ax.set_yticklabels(labels) plt.show() sentence = '我們試試看!' ground_truth = "Let's try it." translated_text, translated_tokens, attention_weights = translator(tf.constant(sentence)) in_tokens = tf.concat([tf.constant(1)[tf.newaxis], chinese_tokenizer(tf.constant(sentence)), tf.constant(2)[tf.newaxis]], axis=-1) attention = tf.squeeze(attention_weights, 0) plot_attention_head(in_tokens, translated_tokens, attention[0])
二、论文解读
2.1 模型架构

Transformers的优点:
- Transformers在处理序列数据表现出色;
- 与RNN不同的是,Transformers是可以并行处理的,这可以使模型在GPU/TPU上训练起来更加的高效;主要原因是Transformers用self-attention代替了循环结构,许多计算不彼此依赖,可以同时计算;
- 与RNN和CNN不同的是,Transformers能够有效的捕获inputs和outputs字符序列中长距离的上下文及其依赖关系,这是CNN和RNN不足的地方,CNN收到kernel_size的限制,RNN受到distance的限制,长距离文本需要经过一系列的流程才能学到;
- Transformers无需对数据之间的时间信息或者空间信息做出任何假设;
2.2 位置编码
词嵌入和位置编码的地方一共有两处,一处是Input,一处是Output(shifted right);两处的流程是一致的,首先进入Embedding层,然后进行位置编码,这里两处采用位置编码的方式是一样的;

位置编码的方式如下:

为什么要采用位置编码:因为模型不包含任何循环或卷积层。它需要一些方法来识别单词顺序,否则它会将输入序列看作无序的;例如:how are you, how you are, you how are,注意力机制无法识别顺序,若不采用位置编码,其得到的结果是一样的,这显然不是我们想要的结果;
为什么这样处理:首先看下面这张图,其为上述位置编码方法的可视化表示:

其生成的代码如下:
def positional_encoding(length, depth): depth = depth/2 positions = np.arange(length)[:, np.newaxis] # (seq, 1) depths = np.arange(depth)[np.newaxis, :]/depth # (1, depth) angle_rates = 1 / (10000**depths) # (1, depth) angle_rads = positions * angle_rates # (pos, depth) pos_encoding = np.concatenate( [np.sin(angle_rads), np.cos(angle_rads)], axis=-1) return tf.cast(pos_encoding, dtype=tf.float32) pos_encoding = positional_encoding(length=2048, depth=512) plt.pcolormesh(pos_encoding.numpy().T, cmap='RdBu') plt.ylabel('Depth') plt.xlabel('Position') plt.colorbar() plt.show()
当然实际每一列是交叉组合的,这里图像是把sine弄在一起; cosine弄在一起,计算不涉及到 position内部 depth的位置关系,所以这样并没有什么实际影响;
以上是该论文位置编码方案的可视化展示,这里要明确一个合理的位置编码应该满足什么条件,合理的位置编码满足的条件如下Transformer的位置编码_transformer 位置编码器-CSDN博客:
- 每一个时间步都有一个唯一且明确的编码,其目的是分辨每一个时间步;
- 不同长度的句子中,对应相同位置的两个时间步的距离是一定的,而且能够随着两个时间步距离的变化单调变化,其目的是知道时间步之间的关系;(这是最重要的)
- 由于位置编码其值的大小在程序中对应权重,所以应该有上下界,不能特别大;
这里固定 Postion=1000,分别对每一个 Positon做点积,可以发现距离1000越近的 Position之间的点积就越大;又因为是三角函数正好满足所有条件,所有采用三角函数是最好的;

有些解释是这样的,但我认为不对,其解释如下:how are you中how的值可以被其他的值线性表示;

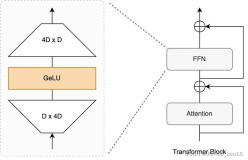
2.3 残差连接和层归一化
可以看到Add & Norm遍布了整个模型,其有什么作用呢?

残差连接如下:

对其求导与直接对 f(x)求导来说多了一个1,而正是这一个1,可以使每一次学习是更新而不是替换,这就是残差连接的好处;
归一化可以使输出的结果保持相同的尺寸;
[transformer]论文实现:Attention Is All You Need(下)https://developer.aliyun.com/article/1504070?spm=a2c6h.13148508.setting.43.36834f0eMJOehx