
Python 深度学习第二版(GPT 重译)(三)(1)https://developer.aliyun.com/article/1485269
7.3.1 编写自己的指标
指标对于衡量模型性能至关重要——特别是用于衡量模型在训练数据和测试数据上性能差异的指标。用于分类和回归的常用指标已经是内置的 keras.metrics 模块的一部分,大多数情况下您会使用它们。但是,如果您正在做一些与众不同的事情,您将需要能够编写自己的指标。这很简单!
Keras 指标是 keras.metrics.Metric 类的子类。像层一样,指标在 TensorFlow 变量中存储内部状态。与层不同,这些变量不会通过反向传播进行更新,因此您必须自己编写状态更新逻辑,这发生在 update_state() 方法中。
例如,这里有一个简单的自定义指标,用于测量均方根误差(RMSE)。
列表 7.18 通过子类化Metric类实现自定义指标
import tensorflow as tf class RootMeanSquaredError(keras.metrics.Metric): # ❶ def __init__(self, name="rmse", **kwargs): # ❷ super().__init__(name=name, **kwargs) # ❷ self.mse_sum = self.add_weight(name="mse_sum", initializer="zeros")# ❷ self.total_samples = self.add_weight( # ❷ name="total_samples", initializer="zeros", dtype="int32") # ❷ def update_state(self, y_true, y_pred, sample_weight=None): # ❸ y_true = tf.one_hot(y_true, depth=tf.shape(y_pred)[1]) # ❹ mse = tf.reduce_sum(tf.square(y_true - y_pred)) self.mse_sum.assign_add(mse) num_samples = tf.shape(y_pred)[0] self.total_samples.assign_add(num_samples)
❶ 子类化 Metric 类。
❷ 在构造函数中定义状态变量。就像对于层一样,你可以访问add_weight()方法。
❸ 在update_state()中实现状态更新逻辑。y_true参数是一个批次的目标(或标签),而y_pred表示模型的相应预测。你可以忽略sample_weight参数——我们这里不会用到它。
❹ 为了匹配我们的 MNIST 模型,我们期望分类预测和整数标签。
你可以使用result()方法返回指标的当前值:
def result(self): return tf.sqrt(self.mse_sum / tf.cast(self.total_samples, tf.float32))
与此同时,你还需要提供一种方法来重置指标状态,而不必重新实例化它——这使得相同的指标对象可以在训练的不同时期或在训练和评估之间使用。你可以使用reset_state()方法来实现这一点:
def reset_state(self): self.mse_sum.assign(0.) self.total_samples.assign(0)
自定义指标可以像内置指标一样使用。让我们试用我们自己的指标:
model = get_mnist_model() model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy", RootMeanSquaredError()]) model.fit(train_images, train_labels, epochs=3, validation_data=(val_images, val_labels)) test_metrics = model.evaluate(test_images, test_labels)
现在你可以看到fit()进度条显示你的模型的 RMSE。
7.3.2 使用回调
在大型数据集上进行数十个时期的训练运行,使用model.fit()有点像发射纸飞机:过了初始冲动,你就无法控制它的轨迹或着陆点。如果你想避免不良结果(从而浪费纸飞机),更明智的做法是使用不是纸飞机,而是一架可以感知环境、将数据发送回操作员并根据当前状态自动做出转向决策的无人机。Keras 的回调API 将帮助你将对model.fit()的调用从纸飞机转变为一个智能、自主的无人机,可以自我反省并动手采取行动。
回调是一个对象(实现特定方法的类实例),它在对fit()的模型调用中传递给模型,并在训练过程中的各个时刻被模型调用。它可以访问有关模型状态和性能的所有可用数据,并且可以采取行动:中断训练、保存模型、加载不同的权重集,或者以其他方式改变模型的状态。
以下是一些使用回调的示例:
- 模型检查点——在训练过程中保存模型的当前状态。
- 提前停止——当验证损失不再改善时中断训练(当然,保存在训练过程中获得的最佳模型)。
- 在训练过程中动态调整某些参数的值——比如优化器的学习率。
- 在训练过程中记录训练和验证指标,或者在更新时可视化模型学习到的表示——你熟悉的
fit()进度条实际上就是一个回调!
keras.callbacks模块包括许多内置回调(这不是一个详尽的列表):
keras.callbacks.ModelCheckpoint keras.callbacks.EarlyStopping keras.callbacks.LearningRateScheduler keras.callbacks.ReduceLROnPlateau keras.callbacks.CSVLogger
让我们回顾其中的两个,以便让你了解如何使用它们:EarlyStopping和ModelCheckpoint。
EarlyStopping 和 ModelCheckpoint 回调
当你训练一个模型时,有很多事情是你无法从一开始就预测的。特别是,你无法知道需要多少个时期才能达到最佳的验证损失。到目前为止,我们的例子采用了训练足够多个时期的策略,以至于你开始过拟合,使用第一次运行来确定适当的训练时期数量,然后最终启动一个新的训练运行,使用这个最佳数量。当然,这种方法是浪费的。更好的处理方式是在测量到验证损失不再改善时停止训练。这可以通过EarlyStopping回调来实现。
EarlyStopping回调会在监控的目标指标停止改进一定数量的时期后中断训练。例如,此回调允许您在开始过拟合时立即中断训练,从而避免不得不为更少的时期重新训练模型。此回调通常与ModelCheckpoint结合使用,后者允许您在训练过程中持续保存模型(可选地,仅保存迄今为止的当前最佳模型:在时期结束时表现最佳的模型版本)。
列表 7.19 在fit()方法中使用callbacks参数
callbacks_list = [ # ❶ keras.callbacks.EarlyStopping( # ❷ monitor="val_accuracy", # ❸ patience=2, # ❹ ), keras.callbacks.ModelCheckpoint( # ❺ filepath="checkpoint_path.keras", # ❻ monitor="val_loss", # ❼ save_best_only=True, # ❼ ) ] model = get_mnist_model() model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy"]) # ❽ model.fit(train_images, train_labels, # ❾ epochs=10, # ❾ callbacks=callbacks_list, # ❾ validation_data=(val_images, val_labels)) # ❾
❶ 回调通过fit()方法中的 callbacks 参数传递给模型,该参数接受一个回调函数列表。您可以传递任意数量的回调函数。
❷ 当改进停止时中断训练
❸ 监控模型的验证准确率
❹ 当准确率连续两个时期没有改善时中断训练
❺ 在每个时期结束后保存当前权重
❻ 目标模型文件的路径
❼ 这两个参数意味着除非 val_loss 有所改善,否则您不会覆盖模型文件,这样可以保留训练过程中看到的最佳模型。
❽ 您正在监视准确率,因此它应该是模型指标的一部分。
❾ 请注意,由于回调将监视验证损失和验证准确率,您需要将 validation_data 传递给 fit()调用。
请注意,您也可以在训练后手动保存模型——只需调用model.save('my_checkpoint_path')。要重新加载保存的模型,只需使用
model = keras.models.load_model("checkpoint_path.keras")
7.3.3 编写自己的回调函数
如果您需要在训练过程中执行特定操作,而内置回调函数没有涵盖,您可以编写自己的回调函数。通过继承keras.callbacks.Callback类来实现回调函数。然后,您可以实现以下任意数量的透明命名方法,这些方法在训练过程中的各个时刻调用:
on_epoch_begin(epoch, logs) # ❶ on_epoch_end(epoch, logs) # ❷ on_batch_begin(batch, logs) # ❸ on_batch_end(batch, logs) # ❹ on_train_begin(logs) # ❺ on_train_end(logs) # ❻
❶ 在每个时期开始时调用
❷ 在每个时期结束时调用
❸ 在处理每个批次之前调用
❹ 在处理每个批次后立即调用
❺ 在训练开始时调用
❻ 在训练结束时调用
这些方法都带有一个logs参数,其中包含有关先前批次、时期或训练运行的信息——训练和验证指标等。on_epoch_*和on_batch_*方法还将时期或批次索引作为它们的第一个参数(一个整数)。
这里有一个简单的示例,它保存了训练过程中每个批次的损失值列表,并在每个时期结束时保存了这些值的图表。
列表 7.20 通过继承Callback类创建自定义回调
from matplotlib import pyplot as plt class LossHistory(keras.callbacks.Callback): def on_train_begin(self, logs): self.per_batch_losses = [] def on_batch_end(self, batch, logs): self.per_batch_losses.append(logs.get("loss")) def on_epoch_end(self, epoch, logs): plt.clf() plt.plot(range(len(self.per_batch_losses)), self.per_batch_losses, label="Training loss for each batch") plt.xlabel(f"Batch (epoch {epoch})") plt.ylabel("Loss") plt.legend() plt.savefig(f"plot_at_epoch_{epoch}") self.per_batch_losses = []
让我们试驾一下:
model = get_mnist_model() model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy"]) model.fit(train_images, train_labels, epochs=10, callbacks=[LossHistory()], validation_data=(val_images, val_labels))
我们得到的图表看起来像图 7.5。
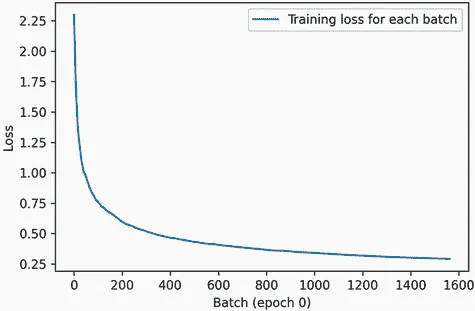
图 7.5 我们自定义历史绘图回调的输出
7.3.4 使用 TensorBoard 进行监控和可视化
要进行良好的研究或开发良好的模型,您需要在实验过程中获得关于模型内部情况的丰富、频繁的反馈。这就是进行实验的目的:获取有关模型表现的信息——尽可能多的信息。取得进展是一个迭代过程,一个循环——您从一个想法开始,并将其表达为一个实验,试图验证或否定您的想法。您运行此实验并处理它生成的信息。这激发了您的下一个想法。您能够运行此循环的迭代次数越多,您的想法就会变得越精细、更强大。Keras 帮助您在最短的时间内从想法到实验,快速的 GPU 可以帮助您尽快从实验到结果。但是处理实验结果呢?这就是 TensorBoard 的作用(见图 7.6)。
图 7.6 进展的循环
TensorBoard(www.tensorflow.org/tensorboard)是一个基于浏览器的应用程序,您可以在本地运行。这是在训练过程中监视模型内部所有活动的最佳方式。使用 TensorBoard,您可以
- 在训练过程中可视化监控指标
- 可视化您的模型架构
- 可视化激活和梯度的直方图
- 在 3D 中探索嵌入
如果您监控的信息不仅仅是模型的最终损失,您可以更清晰地了解模型的作用和不作用,并且可以更快地取得进展。
使用 TensorBoard 与 Keras 模型和fit()方法的最简单方法是使用keras.callbacks.TensorBoard回调。
在最简单的情况下,只需指定回调写入日志的位置,然后就可以开始了:
model = get_mnist_model() model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy"]) tensorboard = keras.callbacks.TensorBoard( log_dir="/full_path_to_your_log_dir", ) model.fit(train_images, train_labels, epochs=10, validation_data=(val_images, val_labels), callbacks=[tensorboard])
一旦模型开始运行,它将在目标位置写入日志。如果您在本地计算机上运行 Python 脚本,则可以使用以下命令启动本地 TensorBoard 服务器(请注意,如果您通过pip安装了 TensorFlow,则tensorboard可执行文件应该已经可用;如果没有,则可以通过pip install tensorboard手动安装 TensorBoard):
tensorboard --logdir /full_path_to_your_log_dir
然后,您可以转到命令返回的 URL 以访问 TensorBoard 界面。
如果您在 Colab 笔记本中运行脚本,则可以作为笔记本的一部分运行嵌入式 TensorBoard 实例,使用以下命令:
%load_ext tensorboard %tensorboard --logdir /full_path_to_your_log_dir
在 TensorBoard 界面中,您将能够监视训练和评估指标的实时图表(参见图 7.7)。
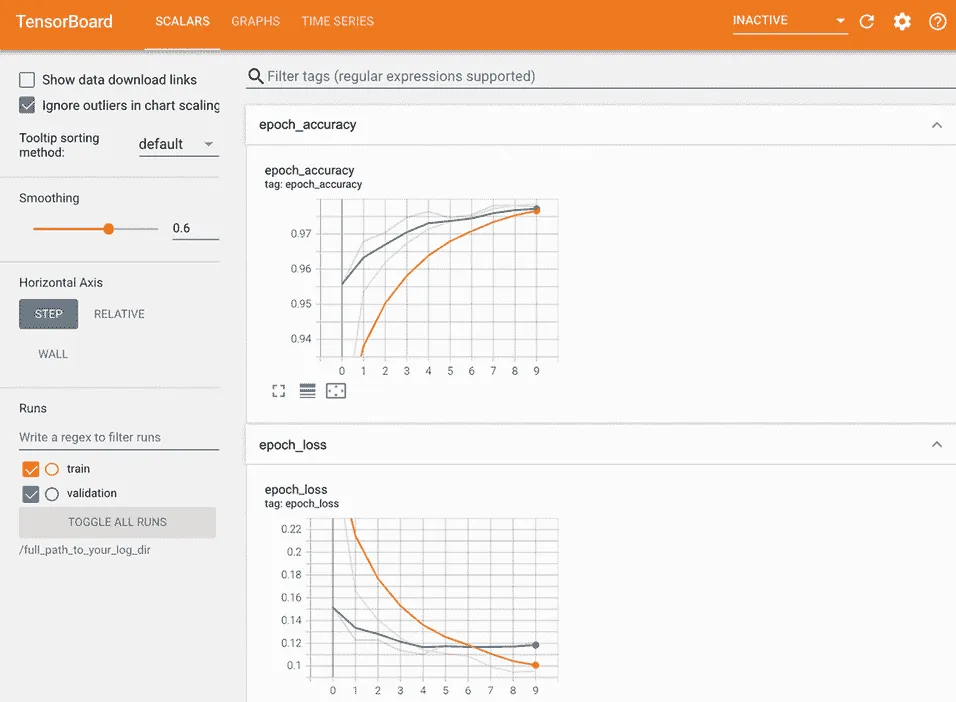
图 7.7 TensorBoard 可用于轻松监控训练和评估指标。
7.4 编写自己的训练和评估循环
fit()工作流在易用性和灵活性之间取得了很好的平衡。这是您大部分时间将使用的方法。但是,即使使用自定义指标、自定义损失和自定义回调,它也不意味着支持深度学习研究人员可能想要做的一切。
毕竟,内置的fit()工作流仅专注于监督学习:一种已知目标(也称为标签或注释)与输入数据相关联的设置,您根据这些目标和模型预测的函数计算损失。然而,并非所有形式的机器学习都属于这一类别。还有其他设置,其中没有明确的目标,例如生成学习(我们将在第十二章中讨论)、自监督学习(目标来自输入)和强化学习(学习受偶尔“奖励”驱动,类似训练狗)。即使您正在进行常规监督学习,作为研究人员,您可能希望添加一些需要低级灵活性的新颖功能。
每当您发现内置的fit()不够用时,您将需要编写自己的自定义训练逻辑。您已经在第二章和第三章看到了低级训练循环的简单示例。作为提醒,典型训练循环的内容如下:
- 运行前向传播(计算模型的输出)在梯度磁带内以获得当前数据批次的损失值。
- 检索损失相对于模型权重的梯度。
- 更新模型的权重以降低当前数据批次上的损失值。
这些步骤将根据需要重复多个批次。这基本上是fit()在幕后执行的操作。在本节中,您将学习如何从头开始重新实现fit(),这将为您提供编写任何可能想出的训练算法所需的所有知识。
让我们详细了解一下。
7.4.1 训练与推断
在你迄今为止看到的低级训练循环示例中,第 1 步(前向传播)通过predictions = model(inputs)完成,第 2 步(检索梯度)通过gradients = tape.gradient(loss, model.weights)完成。在一般情况下,实际上有两个你需要考虑的细微之处。
一些 Keras 层,比如Dropout层,在训练和推理(当你用它们生成预测时)时有不同的行为。这些层在它们的call()方法中暴露了一个training布尔参数。调用dropout(inputs, training=True)会丢弃一些激活条目,而调用dropout(inputs, training=False)则不会做任何操作。扩展到 Functional 和 Sequential 模型,它们的call()方法中也暴露了这个training参数。记得在前向传播时传递training=True给 Keras 模型!因此我们的前向传播变成了predictions = model(inputs, training=True)。
另外,请注意,当你检索模型权重的梯度时,不应该使用tape.gradients(loss, model.weights),而应该使用tape .gradients(loss, model.trainable_weights)。实际上,层和模型拥有两种权重:
- 可训练权重—这些权重通过反向传播来更新,以最小化模型的损失,比如
Dense层的核和偏置。 - 不可训练权重—这些权重在前向传播过程中由拥有它们的层更新。例如,如果你想让一个自定义层记录到目前为止处理了多少批次,那么这些信息将存储在不可训练权重中,每个批次,你的层会将计数器加一。
在 Keras 内置层中,唯一具有不可训练权重的层是BatchNormalization层,我们将在第九章讨论。BatchNormalization层需要不可训练权重来跟踪通过它的数据的均值和标准差的信息,以便执行特征归一化的在线近似(这是你在第六章学到的概念)。
考虑到这两个细节,监督学习训练步骤最终看起来像这样:
def train_step(inputs, targets): with tf.GradientTape() as tape: predictions = model(inputs, training=True) loss = loss_fn(targets, predictions) gradients = tape.gradients(loss, model.trainable_weights) optimizer.apply_gradients(zip(model.trainable_weights, gradients))
7.4.2 指标的低级使用
在低级训练循环中,你可能想要利用 Keras 指标(无论是自定义的还是内置的)。你已经了解了指标 API:只需为每个目标和预测批次调用update_state(y_true, y_pred),然后使用result()来查询当前指标值:
metric = keras.metrics.SparseCategoricalAccuracy() targets = [0, 1, 2] predictions = [[1, 0, 0], [0, 1, 0], [0, 0, 1]] metric.update_state(targets, predictions) current_result = metric.result() print(f"result: {current_result:.2f}")
你可能还需要跟踪标量值的平均值,比如模型的损失。你可以通过keras.metrics.Mean指标来实现这一点:
values = [0, 1, 2, 3, 4] mean_tracker = keras.metrics.Mean() for value in values: mean_tracker.update_state(value) print(f"Mean of values: {mean_tracker.result():.2f}")
当你想要重置当前结果(在训练周期的开始或评估的开始)时,请记得使用metric.reset_state()。
7.4.3 完整的训练和评估循环
让我们将前向传播、反向传播和指标跟踪结合到一个类似于fit()的训练步骤函数中,该函数接受一批数据和目标,并返回fit()进度条显示的日志。
列表 7.21 编写逐步训练循环:训练步骤函数
model = get_mnist_model() loss_fn = keras.losses.SparseCategoricalCrossentropy() # ❶ optimizer = keras.optimizers.RMSprop() # ❷ metrics = [keras.metrics.SparseCategoricalAccuracy()] # ❸ loss_tracking_metric = keras.metrics.Mean() # ❹ def train_step(inputs, targets): with tf.GradientTape() as tape: # ❺ predictions = model(inputs, training=True) # ❺ loss = loss_fn(targets, predictions) # ❺ gradients = tape.gradient(loss, model.trainable_weights) # ❻ optimizer.apply_gradients(zip(gradients, model.trainable_weights)) # ❻ logs = {} # ❼ for metric in metrics: # ❼ metric.update_state(targets, predictions) # ❼ logs[metric.name] = metric.result() # ❼ loss_tracking_metric.update_state(loss) # ❽ logs["loss"] = loss_tracking_metric.result() # ❽ return logs # ❾
❶ 准备损失函数。
❷ 准备优化器。
❸ 准备要监视的指标列表。
❹ 准备一个 Mean 指标追踪器来跟踪损失的平均值。
❺ 进行前向传播。注意我们传递了training=True。
❻ 进行反向传播。注意我们使用了model.trainable_weights。
❼ 跟踪指标。
❽ 跟踪损失平均值。
❾ 返回当前的指标值和损失。
我们需要在每个周期开始和运行评估之前重置指标的状态。这里有一个实用函数来做到这一点。
列表 7.22 编写逐步训练循环:重置指标
def reset_metrics(): for metric in metrics: metric.reset_state() loss_tracking_metric.reset_state()
现在我们可以布置完整的训练循环。请注意,我们使用tf.data.Dataset对象将我们的 NumPy 数据转换为一个迭代器,该迭代器按大小为 32 的批次迭代数据。
列表 7.23 编写逐步训练循环:循环本身
training_dataset = tf.data.Dataset.from_tensor_slices( (train_images, train_labels)) training_dataset = training_dataset.batch(32) epochs = 3 for epoch in range(epochs): reset_metrics() for inputs_batch, targets_batch in training_dataset: logs = train_step(inputs_batch, targets_batch) print(f"Results at the end of epoch {epoch}") for key, value in logs.items(): print(f"...{key}: {value:.4f}")
这就是评估循环:一个简单的for循环,反复调用test_step()函数,该函数处理一个数据批次。test_step()函数只是train_step()逻辑的一个子集。它省略了处理更新模型权重的代码——也就是说,所有涉及GradientTape和优化器的内容。
列表 7.24 编写逐步评估循环
def test_step(inputs, targets): predictions = model(inputs, training=False) # ❶ loss = loss_fn(targets, predictions) logs = {} for metric in metrics: metric.update_state(targets, predictions) logs["val_" + metric.name] = metric.result() loss_tracking_metric.update_state(loss) logs["val_loss"] = loss_tracking_metric.result() return logs val_dataset = tf.data.Dataset.from_tensor_slices((val_images, val_labels)) val_dataset = val_dataset.batch(32) reset_metrics() for inputs_batch, targets_batch in val_dataset: logs = test_step(inputs_batch, targets_batch) print("Evaluation results:") for key, value in logs.items(): print(f"...{key}: {value:.4f}")
❶ 注意我们传递了 training=False。
恭喜你——你刚刚重新实现了fit()和evaluate()!或几乎:fit()和evaluate()支持许多更多功能,包括大规模分布式计算,这需要更多的工作。它还包括几个关键的性能优化。
让我们来看看其中一个优化:TensorFlow 函数编译。
7.4.4 使用 tf.function 使其更快
你可能已经注意到,尽管实现了基本相同的逻辑,但自定义循环的运行速度明显比内置的fit()和evaluate()慢。这是因为,默认情况下,TensorFlow 代码是逐行执行的,急切执行,类似于 NumPy 代码或常规 Python 代码。急切执行使得调试代码更容易,但从性能的角度来看远非最佳选择。
将你的 TensorFlow 代码编译成一个可以全局优化的计算图更有效。要做到这一点的语法非常简单:只需在要执行之前的任何函数中添加@tf.function,如下面的示例所示。
列表 7.25 为我们的评估步骤函数添加@tf.function装饰器
@tf.function # ❶ def test_step(inputs, targets): predictions = model(inputs, training=False) loss = loss_fn(targets, predictions) logs = {} for metric in metrics: metric.update_state(targets, predictions) logs["val_" + metric.name] = metric.result() loss_tracking_metric.update_state(loss) logs["val_loss"] = loss_tracking_metric.result() return logs val_dataset = tf.data.Dataset.from_tensor_slices((val_images, val_labels)) val_dataset = val_dataset.batch(32) reset_metrics() for inputs_batch, targets_batch in val_dataset: logs = test_step(inputs_batch, targets_batch) print("Evaluation results:") for key, value in logs.items(): print(f"...{key}: {value:.4f}")
❶ 这是唯一改变的一行。
在 Colab CPU 上,我们从运行评估循环需要 1.80 秒,降低到只需要 0.8 秒。速度更快!
记住,在调试代码时,最好急切地运行它,不要添加任何@tf.function装饰器。这样更容易跟踪错误。一旦你的代码运行正常并且想要加快速度,就在你的训练步骤和评估步骤或任何其他性能关键函数中添加@tf.function装饰器。
7.4.5 利用 fit() 与自定义训练循环
在之前的章节中,我们完全从头开始编写自己的训练循环。这样做为你提供了最大的灵活性,但同时你会写很多代码,同时错过了fit()的许多便利功能,比如回调或内置的分布式训练支持。
如果你需要一个自定义训练算法,但仍想利用内置 Keras 训练逻辑的强大功能,那么实际上在fit()和从头编写的训练循环之间有一个中间地带:你可以提供一个自定义训练步骤函数,让框架来处理其余部分。
你可以通过重写Model类的train_step()方法来实现这一点。这个函数是fit()为每个数据批次调用的函数。然后你可以像往常一样调用fit(),它将在幕后运行你自己的学习算法。
这里有一个简单的例子:
- 我们创建一个继承
keras.Model的新类。 - 我们重写了方法
train_step(self,data)。它的内容几乎与我们在上一节中使用的内容相同。它返回一个将度量名称(包括损失)映射到它们当前值的字典。 - 我们实现了一个
metrics属性,用于跟踪模型的Metric实例。这使得模型能够在每个时期开始和在调用evaluate()开始时自动调用reset_state()模型的度量,因此你不必手动执行。
列表 7.26 实现一个自定义训练步骤以与fit()一起使用
loss_fn = keras.losses.SparseCategoricalCrossentropy() loss_tracker = keras.metrics.Mean(name="loss") # ❶ class CustomModel(keras.Model): def train_step(self, data): # ❷ inputs, targets = data with tf.GradientTape() as tape: predictions = self(inputs, training=True) # ❸ loss = loss_fn(targets, predictions) gradients = tape.gradient(loss, model.trainable_weights) optimizer.apply_gradients(zip(gradients, model.trainable_weights)) loss_tracker.update_state(loss) # ❹ return {"loss": loss_tracker.result()} # ❺ @property def metrics(self): # ❻ return [loss_tracker] # ❻
❶ 这个度量对象将用于跟踪训练和评估过程中每个批次损失的平均值。
❷ 我们重写了 train_step 方法。
❸ 我们使用self(inputs, training=True)而不是model(inputs, training=True),因为我们的模型就是类本身。
❹ 我们更新跟踪平均损失的损失跟踪器指标。
❺ 通过查询损失跟踪器指标返回到目前为止的平均损失。
❻ 任何你想要在不同 epoch 之间重置的指标都应该在这里列出。
现在,我们可以实例化我们的自定义模型,编译它(我们只传递了优化器,因为损失已经在模型外部定义),并像往常一样使用fit()进行训练:
inputs = keras.Input(shape=(28 * 28,)) features = layers.Dense(512, activation="relu")(inputs) features = layers.Dropout(0.5)(features) outputs = layers.Dense(10, activation="softmax")(features) model = CustomModel(inputs, outputs) model.compile(optimizer=keras.optimizers.RMSprop()) model.fit(train_images, train_labels, epochs=3)
有几点需要注意:
- 这种模式不会阻止你使用 Functional API 构建模型。无论你是构建 Sequential 模型、Functional API 模型还是子类化模型,都可以做到这一点。
- 当你重写
train_step时,不需要使用@tf.function装饰器—框架会为你做这件事。
现在,关于指标,以及如何通过compile()配置损失呢?在调用compile()之后,你可以访问以下内容:
self.compiled_loss—你传递给compile()的损失函数。self.compiled_metrics—对你传递的指标列表的包装器,允许你调用self.compiled_metrics.update_state()一次性更新所有指标。self.metrics—你传递给compile()的实际指标列表。请注意,它还包括一个跟踪损失的指标,类似于我们之前手动使用loss_tracking_metric所做的。
因此,我们可以写下
class CustomModel(keras.Model): def train_step(self, data): inputs, targets = data with tf.GradientTape() as tape: predictions = self(inputs, training=True) loss = self.compiled_loss(targets, predictions) # ❶ gradients = tape.gradient(loss, model.trainable_weights) optimizer.apply_gradients(zip(gradients, model.trainable_weights)) self.compiled_metrics.update_state(targets, predictions) # ❷ return {m.name: m.result() for m in self.metrics} # ❸
❶ 通过self.compiled_loss计算损失。
❷ 通过self.compiled_metrics更新模型的指标。
❸ 返回一个将指标名称映射到它们当前值的字典。
让我们试试:
inputs = keras.Input(shape=(28 * 28,)) features = layers.Dense(512, activation="relu")(inputs) features = layers.Dropout(0.5)(features) outputs = layers.Dense(10, activation="softmax")(features) model = CustomModel(inputs, outputs) model.compile(optimizer=keras.optimizers.RMSprop(), loss=keras.losses.SparseCategoricalCrossentropy(), metrics=[keras.metrics.SparseCategoricalAccuracy()]) model.fit(train_images, train_labels, epochs=3)
这是很多信息,但现在你已经了解足够多的内容来使用 Keras 做几乎任何事情了。
摘要
- Keras 提供了一系列不同的工作流程,基于逐步透露复杂性的原则。它们之间可以平滑地互操作。
- 你可以通过
Sequential类、Functional API 或通过子类化Model类来构建模型。大多数情况下,你会使用 Functional API。 - 训练和评估模型的最简单方法是通过默认的
fit()和evaluate()方法。 - Keras 回调提供了一种简单的方法,在调用
fit()期间监视模型,并根据模型的状态自动采取行动。 - 你也可以通过重写
train_step()方法完全控制fit()的行为。 - 除了
fit(),你还可以完全从头开始编写自己的训练循环。这对于实现全新训练算法的研究人员非常有用。
八、计算机视觉深度学习简介
本章涵盖
- 理解卷积神经网络(卷积网络)
- 使用数据增强来减轻过拟合
- 使用预训练的卷积网络进行特征提取
- 对预训练的卷积网络进行微调
计算机视觉是深度学习最早也是最大的成功故事。每天,你都在与深度视觉模型互动——通过 Google 照片、Google 图像搜索、YouTube、相机应用中的视频滤镜、OCR 软件等等。这些模型也是自动驾驶、机器人、AI 辅助医学诊断、自动零售结账系统甚至自动农业等尖端研究的核心。
计算机视觉是在 2011 年至 2015 年间导致深度学习初次崛起的问题领域。一种称为卷积神经网络的深度学习模型开始在那个时候在图像分类竞赛中取得非常好的结果,首先是 Dan Ciresan 在两个小众竞赛中获胜(2011 年 ICDAR 汉字识别竞赛和 2011 年 IJCNN 德国交通标志识别竞赛),然后更引人注目的是 2012 年秋季 Hinton 的团队赢得了备受关注的 ImageNet 大规模视觉识别挑战赛。在其他计算机视觉任务中,很快也涌现出更多有希望的结果。
有趣的是,这些早期的成功并不足以使深度学习在当时成为主流——这花了几年的时间。计算机视觉研究社区花了很多年投资于除神经网络之外的方法,他们并不准备放弃这些方法,只因为有了一个新的玩家。在 2013 年和 2014 年,深度学习仍然面临着许多资深计算机视觉研究人员的强烈怀疑。直到 2016 年,它才最终占据主导地位。我记得在 2014 年 2 月,我曾劝告我的一位前教授转向深度学习。“这是下一个大事!”我会说。“嗯,也许只是一时的热潮,”他回答。到了 2016 年,他的整个实验室都在做深度学习。一个时机已经成熟的想法是无法阻挡的。
本章介绍了卷积神经网络,也被称为卷积网络,这种深度学习模型现在几乎在计算机视觉应用中被普遍使用。你将学会将卷积网络应用于图像分类问题,特别是涉及小训练数据集的问题,如果你不是一个大型科技公司,这是最常见的用例。
Python 深度学习第二版(GPT 重译)(三)(3)https://developer.aliyun.com/article/1485271




