免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector

是否需要一个向量数据库,往往取决于你的应用场景。举个例子,你的选择是否去一家五星级餐厅用餐,或者是快餐店,往往取决于你的期望;想为自己的个人网站快速搭建一个问答机器人,或者为相册里的十万张照片建立一个索引,你可以选择你最熟悉和便捷的方法,但是,如果目标是一个品质高端的晚宴,你可能会选择一个五星级餐厅,这就如同构建一个企业级的向量检索应用,你的数据量超过千万级,要求延迟在10ms以下,需要使用高级功能如标量过滤,动态架构,多租户,实时更新/删除,批量导入等,就需要用到向量检索了。
为什么应用里需要向量检索
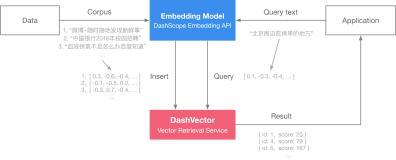
向量检索并非新鲜概念,实际上在过去的十年中,向量检索在大量稠密向量数据中寻找最相近的TopK个相似向量已被广泛应用于推荐系统,图片搜索,风险控制,问答机器人等领域。经过适当训练的神经网络已被证实能够生成代表图像、文本等语义内容的嵌入向量,这大大提高了对非结构化数据语义信息的提取能力。

以图为例,上述图片通过预训练的Resnet-50模型进行特征提取,可以得到一个维度为2048的特征向量[0.1392, 0.3572, 0.1988, ..., 0.2888, 0.6611, 0.2909]。根据这个向量在高维空间中的分布,我们可以轻松地理解和检索非结构化数据的语义。以下是我们对部分照片进行Embedding提取和检索后得到的结果:

基于不同照片进行最近邻匹配得到的可视化结果

嵌入向量对于自然语言数据的映射
在高维空间中,“东京”和“日本”的距离要比“东京”和“中国”的距离更近,因为在预训练的语料库中,“东京”和“日本”共同出现的频率更高。借助模型的先验知识,向量检索能轻易地回溯相关的文本,图片,音频,甚至是图文,文音等多模态数据查询。
向量检索最近的流行与大模型能力的爆发是密切相关的。大模型通常能更有效地理解和生成更高维度、更复杂的数据表示,这为向量检索提供了更精确、更丰富的语义信息。反过来,向量检索也能为大模型提供信息的补全和长上下文的处理能力,从而进一步提升模型的表现。此外,向量检索在大模型的训练和应用中发挥着关键作用。虽然向量数据库并非进行向量检索的唯一途径,但它确实是所有方式中最高效、最便捷的一种。
五分钟入门向量检索
前提条件
- 已创建Cluster:创建Cluster。
- 已获得API-KEY:API-KEY管理。
- 已安装最新版SDK:安装DashVector SDK。
说明
1.需要使用您的api-key替换示例中的YOUR_API_KEY、您的Cluster Endpoint替换示例中的YOUR_CLUSTER_ENDPOINT,代码才能正常运行。
2.Cluster Endpoint,可在控制台“Cluster详情”中查看。
Step1. 创建Client
使用HTTP API时可跳过本步骤。
以下为Python示例:
import dashvector client = dashvector.Client( api_key='YOUR_API_KEY', endpoint='YOUR_CLUSTER_ENDPOINT' ) assert client
Step2. 创建Collection
创建一个名称为quickstart,向量维度为4的collection。
client.create(name='quickstart', dimension=4) collection = client.get('quickstart') assert collection
说明
1.在未指定距离度量参数时,将使用默认的Cosine距离度量方式。
2.在未指定向量数据类型时,将使用默认的Float数据类型。
Step3. 插入Doc
from dashvector import Doc # 通过dashvector.Doc对象,插入单条数据 collection.insert(Doc(id='1', vector=[0.1, 0.2, 0.3, 0.4])) # 通过dashvector.Doc对象,批量插入2条数据 collection.insert( [ Doc(id='2', vector=[0.2, 0.3, 0.4, 0.5], fields={'age': 20, 'name': 'zhangsan'}), Doc(id='3', vector=[0.3, 0.4, 0.5, 0.6], fields={'anykey': 'anyvalue'}) ] )
Step4. 相似性检索
rets = collection.query([0.1, 0.2, 0.3, 0.4], topk=2) print(rets)
Step5. 删除Doc
# 删除1条数据 collection.delete(ids=['1'])
Step6. 查看Collection统计信息
stats = collection.stats() print(stats)
Step7. 删除Collection
client.delete('quickstart')
了解阿里云向量检索服务DashVector的使用方法,请点击:
https://help.aliyun.com/product/2510217.html?spm=a2c4g.2510217.0.0.54fe155eLs1wkT