免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector
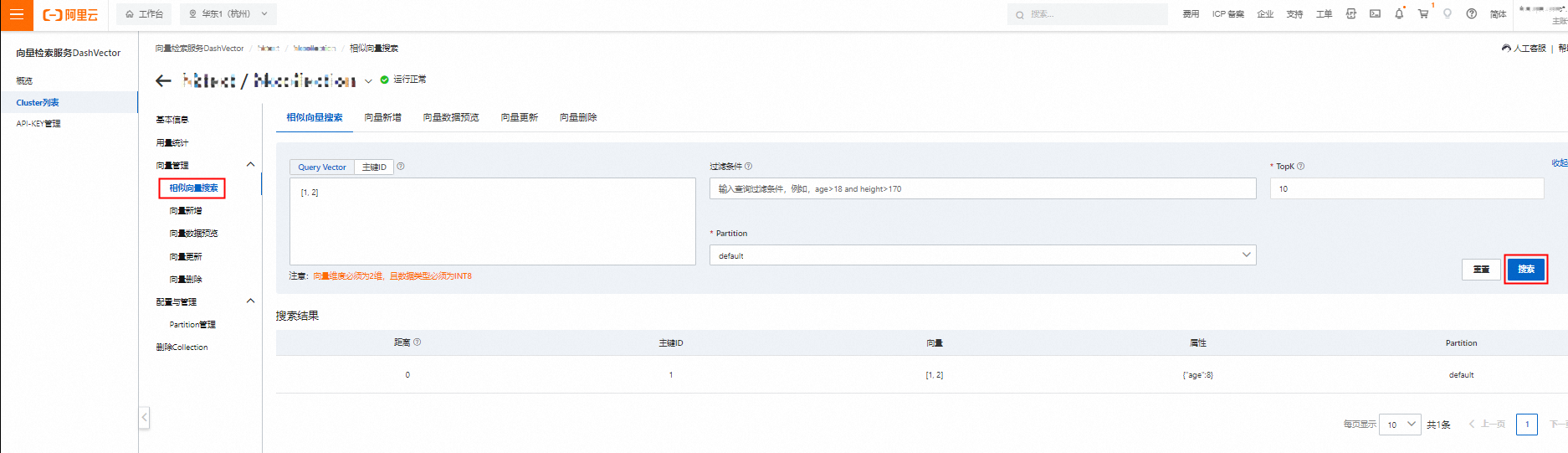
控制台方式
- 登录向量检索服务控制台。
- 在左侧导航栏单击Cluster列表,选中需要检索向量的Collection,单击Collection详情。

- 在左侧二级导航栏,单击相似向量搜索,填写相应内容后,单击搜索,即可返回相似向量结果。
SDK方式
Python SDK方式
前提条件
- 已创建Cluster:创建Cluster。
- 已获得API-KEY:API-KEY管理。
- 已安装最新版SDK:安装DashVector SDK。
接口定义
Collection.query( vector: Optianal[Union[List[Union[int, float]], np.ndarray]] = None, id: Optional[str] = None, topk: int = 10, filter: Optional[str] = None, include_vector: bool = False, partition: Optional[str] = None, output_fields: Optional[List[str]] = None, sparse_vector: Optional[Dict[int, float]] = None, async_req: False ) -> DashVectorResponse
使用示例
说明
- 需要使用您的api-key替换示例中的YOUR_API_KEY、您的Cluster Endpoint替换示例中的YOUR_CLUSTER_ENDPOINT,代码才能正常运行。
- 本示例需要参考新建Collection-使用示例提前创建好名称为
quickstart的Collection,并参考插入Doc提前插入部分数据。
import dashvector import numpy as np client = dashvector.Client( api_key='YOUR_API_KEY', endpoint='YOUR_CLUSTER_ENDPOINT' ) collection = client.get(name='quickstart')
根据向量进行相似性检索
ret = collection.query( vector=[0.1, 0.2, 0.3, 0.4] ) # 判断query接口是否成功 if ret: print('query success') print(len(ret)) for doc in ret: print(doc) print(doc.id) print(doc.vector) print(doc.fields) ret = collection.query( vector=[0.1, 0.2, 0.3, 0.4], topk=100, output_fields=['name', 'age'], # 仅返回name、age这2个Field include_vector=True )
根据主键(对应的向量)进行相似性检索
ret = collection.query( id='1' ) # 判断query接口是否成功 if ret: print('query success') print(len(ret)) for doc in ret: print(doc) print(doc.id) print(doc.vector) print(doc.fields) ret = collection.query( id='1', topk=100, output_fields=['name', 'age'], # 仅返回name、age这2个Field include_vector=True )
带过滤条件的相似性检索
# 根据向量或者主键进行相似性检索 + 条件过滤 ret = collection.query( vector=[0.1, 0.2, 0.3, 0.4], # 向量检索,也可设置主键检索 topk=100, filter='age > 18', # 条件过滤,仅对age > 18的Doc进行相似性检索 output_fields=['name', 'age'], # 仅返回name、age这2个Field include_vector=True )
带有Sparse Vector的向量检索
说明
Sparse Vector(稀疏向量)可用于关键词权重表示,实现带关键词感知能力的向量检索。
# 根据向量进行相似性检索 + 稀疏向量 ret = collection.query( vector=[0.1, 0.2, 0.3, 0.4], # 向量检索 sparse_vector={1: 0.3, 20: 0.7} )
通过过滤条件进行匹配查询
# 支持向量和主键都不传入,那么只进行条件过滤 ret = collection.query( topk=100, filter='age > 18', # 条件过滤,仅对age > 18的Doc进行匹配查询 output_fields=['name', 'age'], # 仅返回name、age这2个Field include_vector=True )
Java SDK方式
前提条件
- 已创建Cluster:创建Cluster。
- 已获得API-KEY:API-KEY管理。
- 已安装最新版SDK:安装DashVector SDK。
接口定义
// class DashVectorCollection // 同步接口 public Response<List<Doc>> query(QueryDocRequest queryDocRequest); // 异步接口 public ListenableFuture<Response<List<Doc>>> queryAsync(QueryDocRequest queryDocRequest);
使用示例
说明
- 需要使用您的api-key替换示例中的YOUR_API_KEY、您的Cluster Endpoint替换示例中的YOUR_CLUSTER_ENDPOINT,代码才能正常运行。
- 本示例需要参考新建Collection-使用示例提前创建好名称为
quickstart的Collection,并参考插入Doc提前插入部分数据。
根据向量进行相似性检索
import com.aliyun.dashvector.DashVectorClient; import com.aliyun.dashvector.DashVectorCollection; import com.aliyun.dashvector.common.DashVectorException; import com.aliyun.dashvector.models.Doc; import com.aliyun.dashvector.models.Vector; import com.aliyun.dashvector.models.requests.QueryDocRequest; import com.aliyun.dashvector.models.responses.Response; import java.util.Arrays; import java.util.List; public class Main { public static void main(String[] args) throws DashVectorException { DashVectorClient client = new DashVectorClient("YOUR_API_KEY", "YOUR_CLUSTER_ENDPOINT"); DashVectorCollection collection = client.get("quickstart"); // 构建Vector Vector vector = Vector.builder().value(Arrays.asList(0.1f, 0.2f, 0.3f, 0.4f)).build(); // 构建QueryDocRequest QueryDocRequest request = QueryDocRequest.builder() .vector(vector) .topk(100) .includeVector(true) .build(); // 进行Doc检索 Response<List<Doc>> response = collection.query(request); // 判断请求是否成功 // assert response.isSuccess() System.out.println(response); // example output: // { // "code":0, // "message":"Success", // "requestId":"b26ce0b8-0caf-4836-8136-df889d79ae91", // "output":[ // { // "id":"1", // "vector":{ // "value":[ // 0.10000000149011612, // 0.20000000298023224, // 0.30000001192092896, // 0.4000000059604645 // ] // }, // "fields":{ // "name":"zhangsan", // "age":20, // "weight":100.0, // "anykey1":"String", // "anykey2":1, // "anykey3":true, // "anykey4":3.1415926 // }, // "score":1.1920929E-7 // } // ] // } } }
根据主键(对应的向量)进行相似性检索
// 构建QueryDocRequest QueryDocRequest request = QueryDocRequest.builder() .id("1") .topk(100) .outputFields(Arrays.asList("name", "age")) // 仅返回name、age这2个Field .includeVector(true) .build(); // 根据主键(对应的向量)进行相似性检索 Response<List<Doc>> response = collection.query(request); // 判断检索是否成功 assert response.isSuccess()
带过滤条件的相似性检索
Vector vector = Vector.builder().value(Arrays.asList(0.1f, 0.2f, 0.3f, 0.4f)).build(); // 构建QueryDocRequest QueryDocRequest request = QueryDocRequest.builder() .vector(vector) // 向量检索,也可设置主键检索 .topk(100) .filter("age > 18") // 条件过滤,仅对age > 18的Doc进行相似性检索 .outputFields(Arrays.asList("name", "age")) // 仅返回name、age这2个Field .includeVector(true) .build(); // 根据向量或者主键进行相似性检索 + 条件过滤 Response<List<Doc>> response = collection.query(request); // 判断检索是否成功 assert response.isSuccess()
带有Sparse Vector的向量检索
说明
Sparse Vector(稀疏向量)可用于关键词权重表示,实现带关键词感知能力的向量检索。
Vectorvector=Vector.builder().value(Arrays.asList(0.1f, 0.2f, 0.3f, 0.4f)).build(); // 构建带有Sparse Vector的QueryDocRequestQueryDocRequestrequest=QueryDocRequest.builder() .vector(vector) // 向量检索 .sparseVector( newMap<Integer, Float>() { { put(1, 0.4f); put(10000, 0.6f); put(222222, 0.8f); } }) // 稀疏向量 .build(); // 根据向量进行相似性检索 + 稀疏向量Response<List<Doc>>response=collection.query(request); // 判断检索是否成功assertresponse.isSuccess()
通过过滤条件进行匹配查询
// 构建只携带过滤条件,不包含主键或向量的QueryDocRequest QueryDocRequest request = QueryDocRequest.builder() .topk(100) .filter("age > 18") // 条件过滤,仅对age > 18的Doc进行相似性检索 .outputFields(Arrays.asList("name", "age")) // 仅返回name、age这2个Field .includeVector(true) .build(); // 支持向量和主键都不传入,那么只进行条件过滤 Response<List<Doc>> response = collection.query(request); // 判断检索是否成功 assert response.isSuccess()
API方式
前提条件
- 已创建Cluster:创建Cluster。
- 已获得API-KEY:API-KEY管理。
- 已安装最新版SDK:安装DashVector SDK。
Method与URL
POST https://{Endpoint}/v1/collections/{CollectionName}/query
使用示例
说明
- 需要使用您的api-key替换示例中的YOUR_API_KEY、您的Cluster Endpoint替换示例中的YOUR_CLUSTER_ENDPOINT,代码才能正常运行。
- 本示例需要参考新建Collection-使用示例提前创建好名称为
quickstart的Collection。
根据向量进行相似性检索
curl -XPOST \ -H 'dashvector-auth-token: YOUR_API_KEY' \ -H 'Content-Type: application/json' \ -d '{ "vector": [0.1, 0.2, 0.3, 0.4], "topk": 10, "include_vector": true }' https://YOUR_CLUSTER_ENDPOINT/v1/collections/quickstart/query # example output: # { # "code": 0, # "request_id": "2cd1cac7-f1ee-4d15-82a8-b65e75d8fd13", # "message": "Success", # "output": [ # { # "id": "1", # "vector":[ # 0.10000000149011612, # 0.20000000298023224, # 0.30000001192092896, # 0.4000000059604645 # ], # "fields": { # "name": "zhangshan", # "weight": null, # "age": 20, # "anykey": "anyvalue" # }, # "score": 0.3 # } # ] # }
根据主键(对应的向量)进行相似性检索
curl -XPOST \ -H 'dashvector-auth-token: YOUR_API_KEY' \ -H 'Content-Type: application/json' \ -d '{ "id": "1", "topk": 1, "include_vector": true }' https://YOUR_CLUSTER_ENDPOINT/v1/collections/quickstart/query # example output: # { # "code":0, # "request_id":"fab4e8a2-15e4-4b55-816f-3b66b7a44962", # "message":"Success", # "output":[ # { # "id":"1", # "vector":[ # 0.10000000149011612, # 0.20000000298023224, # 0.30000001192092896, # 0.4000000059604645 # ], # "fields": { # "name": "zhangshan", # "weight": null, # "age": 20, # "anykey": "anyvalue" # }, # "score": 0.3 # } # ] # }
带过滤条件的相似性检索
curl -XPOST \ -H 'dashvector-auth-token: YOUR_API_KEY' \ -H 'Content-Type: application/json' \ -d '{ "filter": "age > 18", "topk": 1, "include_vector": true }' https://YOUR_CLUSTER_ENDPOINT/v1/collections/quickstart/query # example output: # { # "code":0, # "request_id":"4c7331d8-fba1-4c3a-8673-124568670de7", # "message":"Success", # "output":[ # { # "id":"1", # "vector":[ # 0.10000000149011612, # 0.20000000298023224, # 0.30000001192092896, # 0.4000000059604645 # ], # "fields": { # "name": "zhangshan", # "weight": null, # "age": 20, # "anykey": "anyvalue" # }, # "score": 0.0 # } # ] # }
带有Sparse Vector的向量检索
curl -XPOST \ -H 'dashvector-auth-token: YOUR_API_KEY' \ -H 'Content-Type: application/json' \ -d '{ "vector": [0.1, 0.2, 0.3, 0.4], "sparse_vector":{"1":0.4, "10000":0.6, "222222":0.8}, "topk": 1, "include_vector": true }' https://YOUR_CLUSTER_ENDPOINT/v1/collections/quickstart/query # example output: # { # "code":0, # "request_id":"ad84f7a0-b4b2-4023-ae80-b6f092609a53", # "message":"Success", # "output":[ # { # "id":"2", # "vector":[ # 0.10000000149011612, # 0.20000000298023224, # 0.30000001192092896, # 0.4000000059604645 # ], # "fields":{"name":null,"weight":null,"age":null}, # "score":1.46, # "sparse_vector":{ # "10000":0.6, # "1":0.4, # "222222":0.8 # } # } # ] # }
向量检索服务 DashVector免费试用进行中,玩转大模型搜索,快来试试吧~
了解更多信息,请点击:https://www.aliyun.com/product/ai/dashvector