免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector

一、定义
1.1 近邻检索(Nearest Neighbor Search)
给定一个查询向量q和一个向量数据集  ,找出距离q最近目标(Nearest Neighbor Search,NNS)。近邻检索问题也可以拓展至Top-K版本,也就是KNN问题。一般来说,近邻检索的最朴素的做法是线性查找,就是输入向量跟库中所有的向量进行距离计算,最后选出topk返回,能保证绝对精确检索,但线性查找的时间复杂度是
,找出距离q最近目标(Nearest Neighbor Search,NNS)。近邻检索问题也可以拓展至Top-K版本,也就是KNN问题。一般来说,近邻检索的最朴素的做法是线性查找,就是输入向量跟库中所有的向量进行距离计算,最后选出topk返回,能保证绝对精确检索,但线性查找的时间复杂度是  (向量的维数是D,搜索集里含有N个向量),计算量太大,这个效率在绝大多数场景是不能接受的。线性查找比较低效,我们往往更关注近似近邻检索:
(向量的维数是D,搜索集里含有N个向量),计算量太大,这个效率在绝大多数场景是不能接受的。线性查找比较低效,我们往往更关注近似近邻检索:

1.2 近似近邻检索(Approximate Nearest Neighbor Search)
基本思路:通过牺牲一小部分精度,来换取几个量级检索速度提升。具体就是通过预先将数据以某一种形式组织好,这个可以类比于对一个
数组进行排序,排好序的数据相比于无序的数据,可以用二分查找的方式加快查询效率,但因为向量集对比数组问题会复杂一些,所以在组
织或查找的时候导致一些精度的损失。
基本方案:
- 缩短距离计算的时间 – 量化
- 减少距离计算的次数 – 树、哈希、倒排、图
学术界近似近邻检索方法分类:树方法、哈希方法、矢量量化方法、图方法
学术界近似近邻检索方法分类:

二、度量/距离
这里列举一些比较常用的距离度量计算方法
- 欧式距离(Euclidean Distance)
- 余弦距离(Cosine Distance)
- 杰卡德距离(Jaccard Distance)
- 汉明距离(Hamming Distance)
- 内积(Inner Product)
三、树方法
3.1 KD树
基本思路
把数据按照平面分割,并构造二叉树代表这种分割。
建树过程
- 沿着笛卡尔坐标,选择方差最大的维度进行划分。
- 每个维度采用中位数作为划分点,划分并分配数据至叶子结点。
- 每个叶子结点重复建树过程,直至叶子结点只有一个数据点。

搜索过程
- 依据二叉树搜索算法找到搜索点所在的叶子节点空间,计算叶子节点上的数据点与搜索点之间的距离,记作当前最短距离。
- 回溯父结点,判断搜索点当前最短距离构成的超球体与父结点的另一个结点构成的超矩形是否相交,如果没有相交,继续回溯直至根节点,否则递归搜索另一个结点。

KD树因为有回溯的机制,它能够保证搜索回来的点是精确的,同时相比与线性查找,它计算距离的次数是减少了,但它只适合用于低维数据的检索,维度越高,搜索点当前最短距离构成的超球体与超矩形的相交概率越大,此时就趋近于线性的搜索。(搜索时间复杂度为  ,维度很大时(D >= 20),检索效率趋于线性查找)
,维度很大时(D >= 20),检索效率趋于线性查找)
3.2 Annoy
建树过程
- 随机选择两个点,确定划分超平面,划分为两个子空间。
- 每个子空间按相同方式递归迭代划分,直至子空间数据量少于K。
存在问题:实际最近邻可能跨越到相邻节点。
优化:通过建立多颗树,由于每次划分都是随机的,所以形成的树也是不一样的。
检索过程
- 每颗树按树结构进行检索得到候选集(多颗树的检索可并行)。
- 合并候选集,线性计算结果。
优化:在搜寻叶子节点的过程中,如果搜索点与当前的节点的距离小于指定阈值,那么就是不做选择了,对两个子树进行搜索,最终可能会搜索到多个叶子节点,把这些叶子节点的数据点就构成一个候选点集。

Annoy建树过程

Annoy检索过程
四、哈希方法
4.1 局部敏感哈希(Locality-Sensitive Hashing,LSH)
哈希函数满足局部敏感:两个点距离越近,哈希值相同概率越高。
 哈希方法最主流的方法就是局部敏感哈希,它跟普通哈希的主要区别在于普通哈希要避免哈希碰撞,而局部敏感哈希是希望两个点距离越近,碰撞概率也就是哈希值相同概率越高。
哈希方法最主流的方法就是局部敏感哈希,它跟普通哈希的主要区别在于普通哈希要避免哈希碰撞,而局部敏感哈希是希望两个点距离越近,碰撞概率也就是哈希值相同概率越高。
它的原理比较简单,主要就是找到一系列符合局部敏感的哈希函数,然后将距离相近的点映射到同一个桶里,构成一个哈希表,搜索的时候就是把搜索点,通过同样的哈希函数映射到某个桶里,对桶里的所有数据点求距离得到最近的数据点,因为只对一个桶里的数据做计算,而不是对所有数据计算,所以大大减少了距离计算的次数,提高了效率,而且因为同一个桶都是哈希敏感的,桶里的点大概率是相近的点,因此这种计算方式对精度的影响也不会很大;同时它可以通过构建多个哈希表的形式,把每个哈希表碰撞到的桶的数据做一个并集,再线性计算距离即可,避免出现单个哈希表把相近的数据点划分到不同桶里影响精度。

哈希方法-几种常见哈希
五、矢量量化方法
5.1 矢量量化(Vector Quantization,VQ)
一般应用于信号数据压缩领域,也可用于近似近邻检索(压缩向量以缩短距离计算的时间)。
VQ量化过程:用K-means聚类得到K个聚类中心,用距离最近的聚类中心ID编码每个向量。

不同粒度量化
矢量量化一般应用于信号数据压缩领域,也可用于近似近邻检索,它主要是通过压缩向量的形式来缩短距离计算的时间,从而加快近邻检索的速度,所以它一般是用于较高维的场景;最简单的量化过程就是通过kmeans聚类的方式得到k个聚类中心,然后用距离最近的聚类中心ID来编码每个向量。
这种做法会损失一部分精度,还有一些方法是基于这种方法的改进,比如PQ。
5.2 乘积量化(Product Quantization,PQ)
向量表示:将高维浮点型向量进行分段,每段分别进行VQ量化,最后转为低维整型向量表示(向量压缩)。
距离计算(近似距离)
- 对称距离:请求向量所属的聚类中心与所有样本所属聚类中心的距离。
- 非对称距离:请求向量与所有样本所属聚类中心的距离。

量化过程
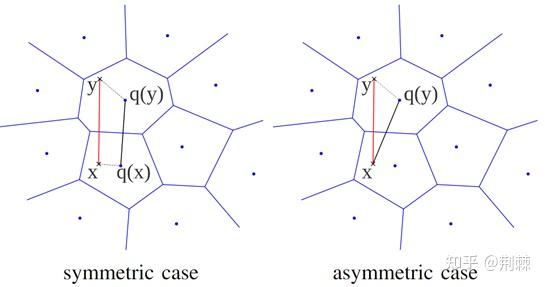
对称距离/非对称距离

距离计算复杂度
5.3 倒排乘积量化(IVF-PQ)
思路:通过快速定位到与查询向量更近的样本减少距离计算次数来加快近邻检索过程。

IVF-PQ
六、图方法
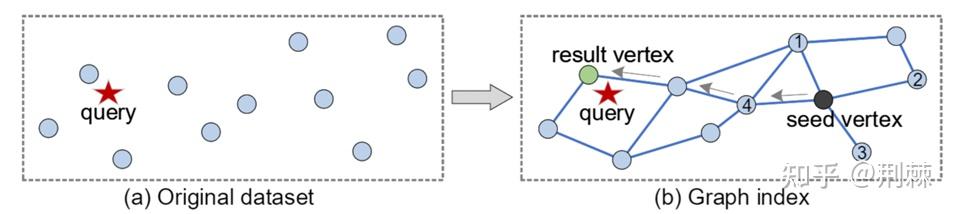
图方法
6.1 基本思想:将最近邻查找转化为图遍历
各种图算法在检索上步骤基本上是一致的(贪婪搜索法):
- 选择入口点,随机选一个点或者选择中心点。
- 遍历入口点邻居,比较是否有离query更近的点,如果有则将该点切换为入口点。
- 重复步骤2,直至入口点不变。
6.2 四种基图
- 德劳内图(DG):以x,y,z三个点形成的三条边的外接圆内不能有其他样本点。
- 相对邻图(RNG):两个点以他们距离半径构成的两个圆的重合部分不能有其他点。
- K 近邻图(KNNG):每个样本点与它最近的K个邻居相连。
- 最小生成树(MST):所有边的距离加起来是最小的。
主要区别在于选边策略

四种基图
6.3 可导航小世界(Navigable Small World, NSW)
构图过程(选边策略):增量插入式,每插入一个样本点,选择距离最近K个样本相连(开始样本较少,能和距离较远的样本能连上边,形成少量长程连接,随着样本点增多,不容易与远处点相连,逐渐形成了比较多的短连接)。
优点:
- 丰富的短连接:提升检索准确率。
- 少量的长程连接(高速公路):提升检索效率。
缺点:图平均度数偏高,计算效率低。

构图过程

检索过程
6.4 分层的可导航小世界(Hierarchical Navigable Small World, HNSW)
- 层次化:借鉴类似链表中跳表形式的分层结构(随机算法确定插入点的层)。
- 选边策略:采用简单连接和启发式连接。
- 裁边策略:限制每个结点的最高度数。

分层结构

免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector