
6 分布式表格系统
Google Bigtable 是分布式表格系统的始祖,采用双层结构,底层采用 GFS 作为持久化存储层。GFS + Bigtable 双层架构是一种里程碑式的架构。
6.1 Google Bigtable
Bigtable 是 Google 开发的基于 GFS 和 Chubby 的分布式表格系统。
Web 索引、卫星图像数据等在内的海量结构化和半结构化数据,都存储在 Bigtable 中。
Bigtable 是一个分布式多维映射表:
(row:string, column:string, timestamp:int64) -> string OCAML |
Bigtable 将多个列组织成列族(column family),这样,列名由 2 个部分组成:(column family, qualifier)。列族是 Bigtable 中访问控制的基本单元。
6.1.1 架构
Bigtable 构架在 GFS 之上,为文件系统增加一层分布式索引层。另外,Bigtable 依赖 Google 的 Chubby(分布式锁服务)进行服务器选举及全局信息维护。
Bigtable 将大表划分为大小在 100 - 200 MB 的子表(tablet),每个子表对应一个连续的数据范围。Bigtable 主要由 3 个部分组成:
- 客户端程序库(client):Bigtable 到应用程序的接口。但数据内容是都客户端和子表服务器之间直接传送。
- 一个主控服务器(Master):管理所有子表服务器,包括分配子表给子表服务器,指导子表服务器实现子表的合并,接受来自子表服务器的子表分裂消息,监控子表服务器,在子表服务器之间进行负载均衡并实现子表服务器的故障恢复等。
- 多个子表服务器(tablet Server):实现子表的装载、卸载、表格内容的读写,子表的合并和分裂。操作日志以及每个子表上的 sstable 数据存储在底层的 GFS 中。
Bigtable 依赖 Chubby 锁服务实现如下功能:
- 选取并保证同一时间只有一个主控服务器;
- 存储 Bigtable 系统引导信息;
- 用于配合主控服务器发现子表服务器加入和下线;
- 获取 Bigtable 表格的 schema 信息及访问控制信息。
Chubby 是一个分布式锁服务,底层算法核心是 Paxos。典型部署为:** 两地三中心五副本,同城的两个数据中心分别部署两个副本,异地的数据中心部署一个副本,** 任何一个数据中心整体发生故障都不影响正常服务。
Bigtable 包含三种类型的表格:
- 用户表(User Table):存储用户实际数据
- 元数据表(Meta Table):存储用户表的元数据,如子表位置信息、SSTable 及操作日志文件编号、日志回放点等
- 根表(Root Table):存储元数据表的元数据。根表的元数据,也就是根表的位置信息,又称 Bigtable 引导信息,存放在 Chubby 系统中。客户端、主控服务器以及子表服务器执行过程中都需要依赖 Chubby 服务,如果 Chubby 发生故障,Bigtable 整体不可用。
6.1.2 数据分布
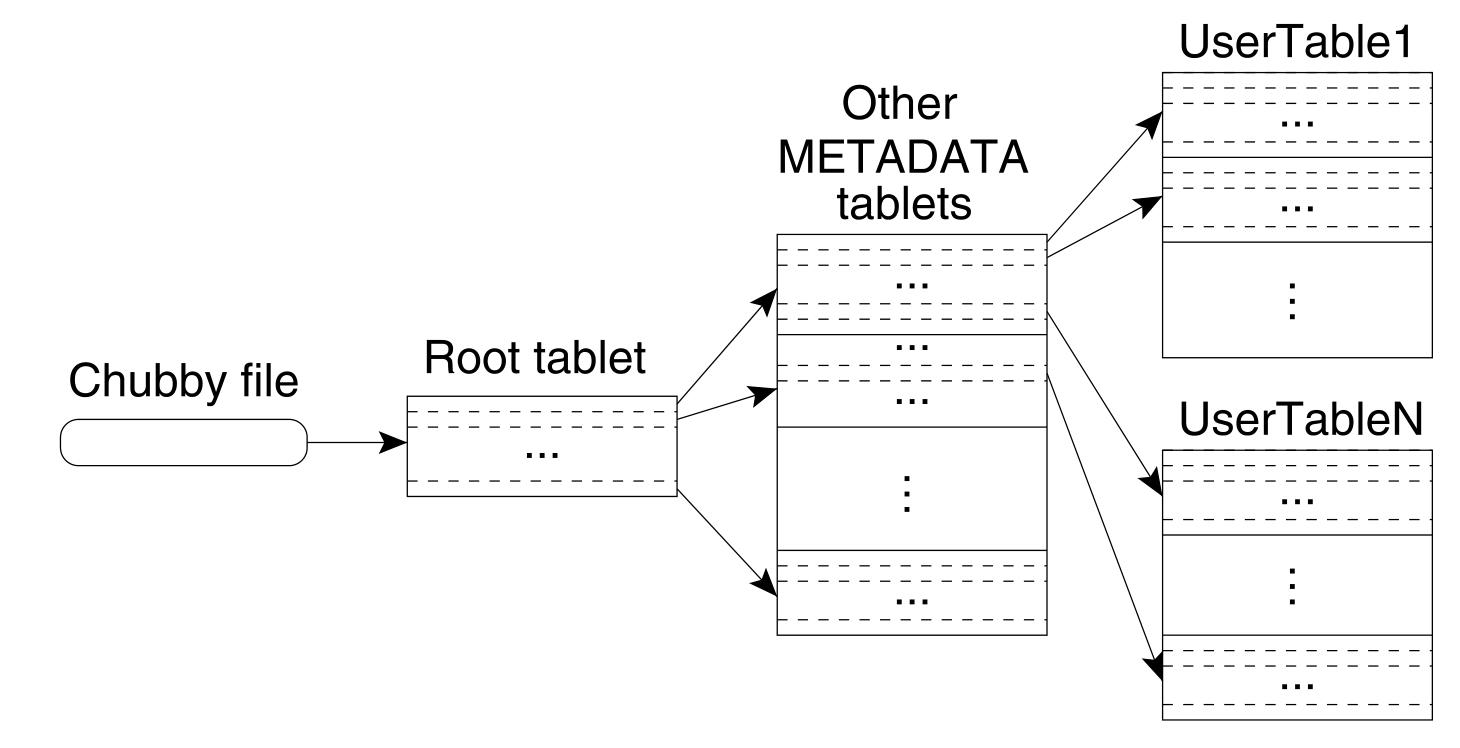
假设平均一个子表为 128MB,每个子表的元信息为 1KB,那么一级元数据能够支持的数据量为 128MB * (128MB/1KB) = 16TB,两级元数据能够 支持的数据量为 16TB*(128MB/1KB)=2048 PB, 满足几乎所有业务的数据量需求。
客户端使用了缓存(cache)和预取(prefetch)技术。
6.1.3 复制与一致性
Bigtable 系统保证强一致性,同一时刻同一个子表只能被一台 TabletServer 服务。通过 Chubby 互斥锁实现的。
Bigtable 写入 GFS 的数据分为 2 种:
- 操作日志。
- 每个子表包含的 SSTable 数据。
6.1.4 容错
6.1.5 负载均衡
子表是 Bigtable 负载均衡的基本单位。
负载均衡:子表迁移。
6.1.6 分裂与合并
6.1.7 单机存储
Bigtable 采用 Merge-dump 引擎。随机读取和顺序读取都只需要访问一次磁盘。
6.1.8 垃圾回收
标记删除(mark-and-sweep)
6.1.9 讨论
GFS + Bigtable 兼顾系统的强一致性和可用性。
底层 GFS 弱一致性,可用性和性能很好;上层的表格系统 Bigtable 通过多级分布式索引使得对外整体表现为强一致性。
Bigtable 最大的优势在于线性可扩展。
Bigtable 架构面临一些问题:
- 单副本服务。Bigtable 架构适合离线或半线上应用。
- SSD 使用。
- 架构的复杂性导致 Bug 定位困难
6.2 Google Megastore
在 Bigtable 系统之上提供友好的数据库功能支持,增强易用性。Megastore 接入传统的关系型数据库和 NoSQL 之间的存储技术。
6.2.1 系统架构
6.2.2 实体组
6.2.3 并发控制
6.2.4 复制
6.2.5 索引
- 局部索引
- 全局索引
- STORING 子句
- 可重复索引
6.2.6 协调者
6.2.7 读取流程
6.2.8 写入流程
6.2.9 讨论
分布式存储系统的两个目标:
- 可扩展性,最终目标是线性可扩展;
- 功能,最终目标是支持全功能 SQL。




