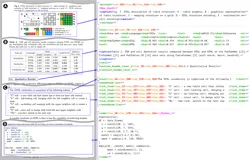
票证检测矫正模型在实际生活中有着广泛的需求,例如信息抽取、图像质量判断、证件扫描、票据审计等领等场景,可以大幅提高工作效率和准确性。
读光-票证检测矫正模型
日前,读光团队 开源的商用票证检测矫正模型,基于海量的真实数据训练,可以从容应对多种复杂场景的票证检测矫正任务,该模型具有以下优点:
- 支持任意角度、多卡证票据等混贴场景,同时检测输入图像任意角度的多个子图区域
- 基于海量真实数据训练,效果满足国内常见的卡证票据的检测矫正需求
- 支持子图区域复印件判断、四方向判断,准确率高达 99%
模型链接:
https://modelscope.cn/models/damo/cv_resnet18_card_correction/summary
下图是模型的实现流程:
输入图片,基于 Resnet18-FPN 提取特征后,在 1/4 尺寸处通过三条分支分别识别出票证的中心点、偏移量(中心点到4个顶点距离)、中心点偏移量(为了得到精准的中心点),即可解码数出票证区域的四边形框;再用透视变换将票证拉平得到矫正后的票证信息;与此同时,分类分支识别出子图朝向,用于而切割的子图转正。

下图是模型效果:

接下来,介绍如何利用读光-检测矫正模型结合更多开源模型组合 DIY 票证信息抽取 应用:
实操教程:DIY票证信息抽取
票证信息抽取的流程包括:
● 预处理:对采集到的图像进行预处理操作,以提高后续处理的准确性。这包括图像去噪、二值化、旋转校正、尺寸标准化等操作。
● 文本检测:使用文本检测算法(如OCR技术)对处理后的图像进行分析,检测出图像中的文字区域。
● 文本识别:将检测到的文字区域进行识别,将图像中的文字转换成电子文本形式。
● 信息抽取:对识别出的文本进行分析,根据票据或证件的特定格式提取出关键信息,如发票号码、金额、日期等。
● 信息验证:对抽取出的信息进行验证,确保信息的准确性。这可能包括与数据库中的信息进行比对、检查信息的格式等。

1. 首先使用读光票证检测矫正模型,将图片中多个证件切分出来,并把对其方向进行旋转和矫正。
推荐模型
读光-票证检测矫正模型:https://modelscope.cn/models/damo/cv_resnet18_card_correction/summary
card_detection_correction = pipeline(Tasks.card_detection_correction, model='damo/cv_resnet18_card_correction') card_result = card_detection_correction(file) array_imgs = card_result['output_imgs']
2. 第二步使用读光文字检测模型,将每个证件中的文字按照行检测出来。使用ICGN效果会更好,使用DBNet调试更方便。
推荐模型
读光-文字检测-DBNet行检测模型-中英-通用领域:
https://modelscope.cn/models/damo/cv_resnet18_ocr-detection-db-line-level_damo/summary
ocr_detection = pipeline(Tasks.ocr_detection, model='damo/cv_resnet18_ocr-detection-db-line-level_damo') for img in array_imgs: o_img = img det_result = ocr_detection(o_img)
3. 第三步使用读光文字识别模型,将每个检测框中的文字识别出来。
推荐模型:
读光-文字识别-行识别模型-中英-通用领域:
https://modelscope.cn/models/damo/cv_convnextTiny_ocr-recognition-general_damo/summary
ocr_recognition = pipeline(Tasks.ocr_recognition, model='damo/cv_convnextTiny_ocr-recognition-general_damo') for ori_pts in det_result['polygons']: pts = order_point(ori_pts) image_crop = crop_image(o_img, pts) line_result = ocr_recognition(image_crop)['text'][0] text_all = text_all+';'+line_result
4. 最后使用大模型或者NER模型将文字内容中实体信息抽取出来。
推荐模型:
通义千问-7B-Chat:https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary
model_dir = snapshot_download("qwen/Qwen-7B-Chat", revision = 'v1.1.4') tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval() model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True) response, history = model.chat(tokenizer, "你好", history=None) response, history = model.chat(tokenizer, "请告诉我下面这段文字的发票代码,发票号码,发票金额,发票印制地名称:"+text_all, history=None)
下图是结果,展示了检测和识别的内容,以及使用千问chat提问的结果:

更多开源
读光团队在工业界和学术界上开源出了一系列的模型,这些模型贯穿了从基础的预训练模型,到核心图文处理模型,再到行业应用模型。具体地,在图像预处理方面开源了证件和票据检测矫正模型。

读光团队会在ModelScope上全栈布局,并将最新的研究成果公开,最终能够促进行业落地。希望这些开源的模型能够在学术界和工业界为大家提供帮助和启迪。
附:读光团队
文字检测模型:
● ICGN:
https://modelscope.cn/models/damo/cv_resnet18_ocr-detection-line-level_damo/summary
● DB:
https://modelscope.cn/models/damo/cv_resnet18_ocr-detection-db-line-level_damo/summary
● DB-轻量化:
https://modelscope.cn/models/damo/cv_proxylessnas_ocr-detection-db-line-level_damo/summary
文字识别模型:
● ConvNextVit-中英:
https://modelscope.cn/models/damo/cv_convnextTiny_ocr-recognition-general_damo/summary
● ConvNextVit-文档:
https://modelscope.cn/models/damo/cv_convnextTiny_ocr-recognition-document_damo/summary
● ConvNextVit-手写:
https://modelscope.cn/models/damo/cv_convnextTiny_ocr-recognition-handwritten_damo/summary
● CRNN-通用:
https://modelscope.cn/models/damo/cv_crnn_ocr-recognition-general_damo/summary
● LightweightEdge-轻量化:https://modelscope.cn/models/damo/cv_LightweightEdge_ocr-recognitoin-general_damo/summary
表格:
● 有线表格:
https://modelscope.cn/models/damo/cv_dla34_table-structure-recognition_cycle-centernet/summary
● 无线表格:
https://modelscope.cn/models/damo/cv_resnet-transformer_table-structure-recognition_lore/summary
卡证:
● 透视矫正:
https://modelscope.cn/models/damo/cv_resnet18_card_correction/summary
点击链接查看更多社区ocr模型实践案例