
ChatDB 框架包含三个主要阶段:input processing(输入处理),chain-of-memory(记忆链),和 response summary(总结回复),如图 2 所示。
1 输入处理:对于用户的输入,如果不涉及使用记忆模块,则直接生成回复;如果需要记忆模块,如查询或者更新数据库,语言模型则生成与记忆模块交互的一系列 SQL 语句。2 记忆链:执行一系列记忆操作来与符号性记忆模块交互。ChatDB 按照先前生成的一系列 SQL 语句依次操作符号性记忆模块,包括插入、更新、选择、删除等操作。外部数据库执行相应的 SQL 语句,更新数据库并返回结果。值得注意的是,在执行每一步记忆操作之前,ChatDB 会根据先前 SQL 语句的结果决定是否更新当前记忆操作。ChatDB 按照此过程执行每一步记忆操作,直到所有记忆操作完成。3 总结回复: 语言模型综合与数据库交互得到的结果,并对用户的输入做出总结回复。

其中 Chain-of-Memory(CoM,记忆链)是一个新提出的方法,以更有效地操作符号性记忆模块,从而进一步增强 LLMs 的推理能力。记忆链方法将用户输入转化为一系列中间记忆操作步骤,将复杂的问题用多个记忆操作步骤来解决,每个中间步骤涉及一个或多个 SQL 语句,大大降低了解决问题的复杂度。
实验和结果
实验设置:为了验证 ChatDB 中将数据库作为符号性记忆模块来增强大语言模型的有效性,并与其他的模型进行定量比较,作者构造了一个模拟一家水果店的运营管理的合成数据集。该数据命名为 “水果商店数据集”,其中包含了 70 条按时间顺序生成的商店记录,总共约有 3.3k 个 tokens(小于 ChatGPT 最大上下文窗口长度 4096)。这些记录包含水果店的四种常见操作:采购、销售、价格调整和退货。为了评估模型的性能,作者针对销售记录收集了 50 个问题,并为这些问题标注了标准答案。这些问题主要涉及商店数据的分析和管理,它们难度各不相同,既包括需要进行多次推理的困难问题,也包括只需从历史数据中检索信息的简单问题。其中包含了 15 个简单问题和 35 个困难问题。
模型对比:ChatDB 模型中的 LLM 模块使用了 ChatGPT (GPT-3.5 Turbo),温度参数设置为 0,并使用 MySQL 数据库作为其外部符号性记忆模块。对比的基线模型为 ChatGPT (GPT-3.5 Turbo),最大的上下文长度为 4096,温度参数也设置为 0。
指标结果:作者在水果商店问答数据集上进行了实验,相对于 ChatGPT,ChatDB 在这些问题的解答上展现出了显著的优势。

表 1:回答水果商店数据集中问题的正确率
作者表示目前实验还只是在一个简单的合成数据集上进行的,之后会在更复杂更贴近现实需求的场景下进行实验,拓展 ChatDB 的应用价值。
Demo 展示
下面是用大语言模型作为店长经营一家水果商店的例子:
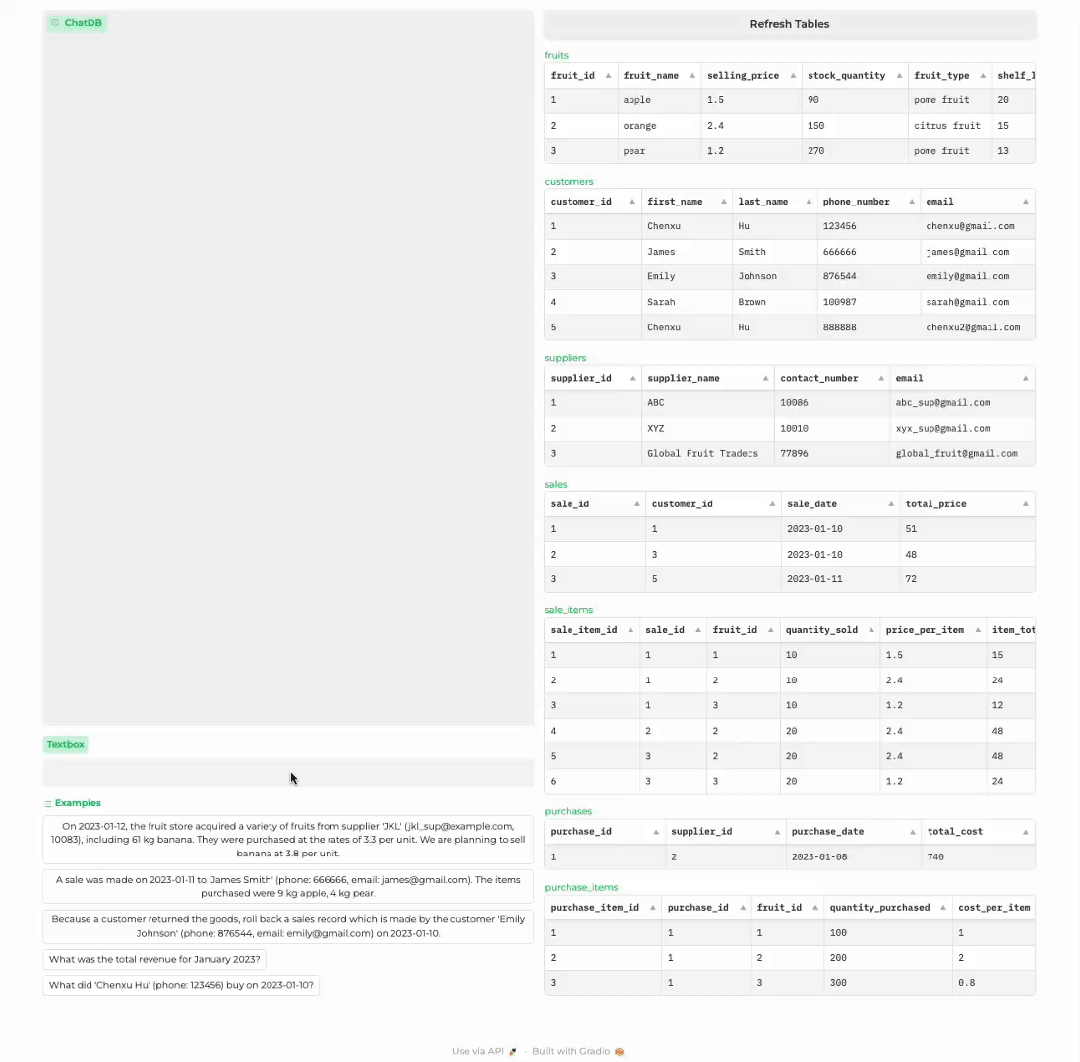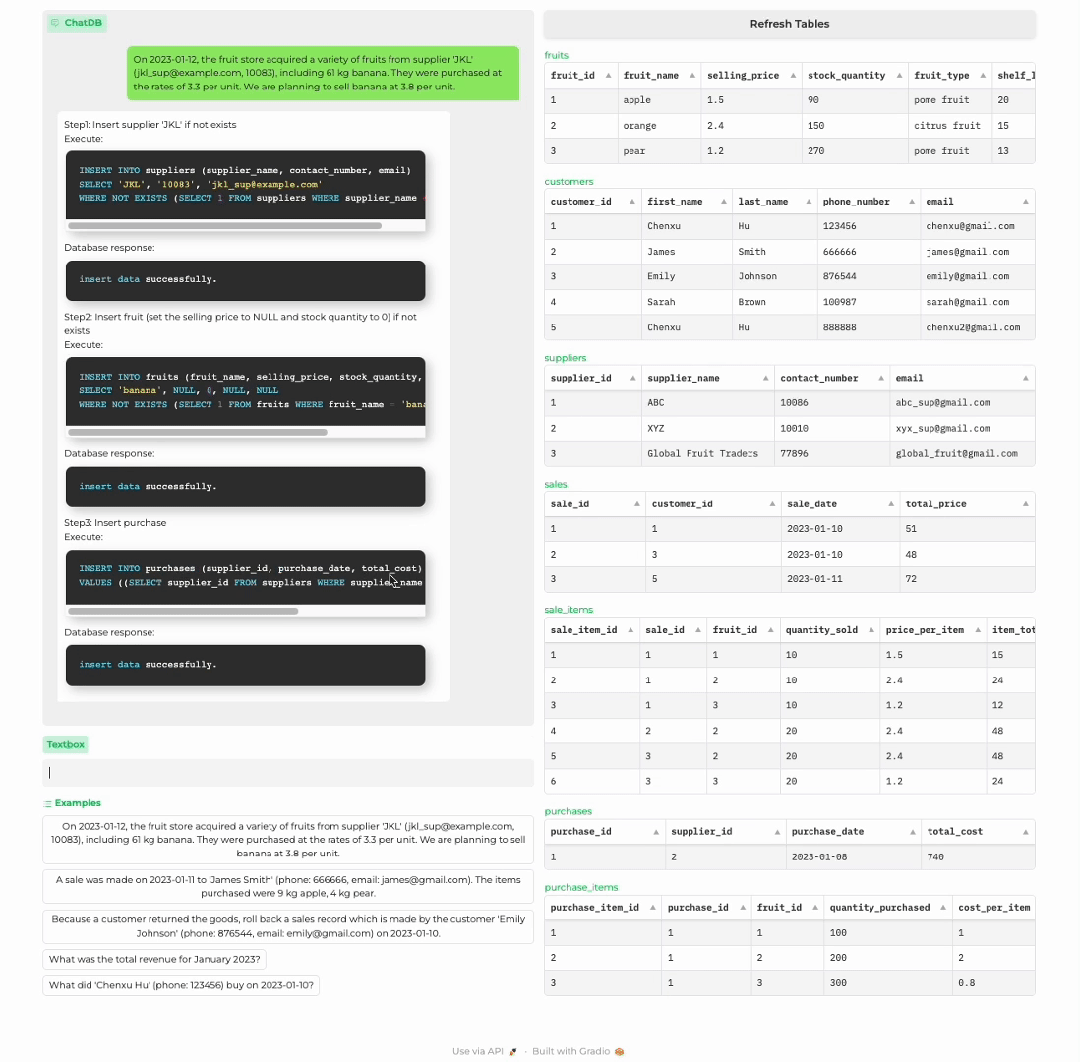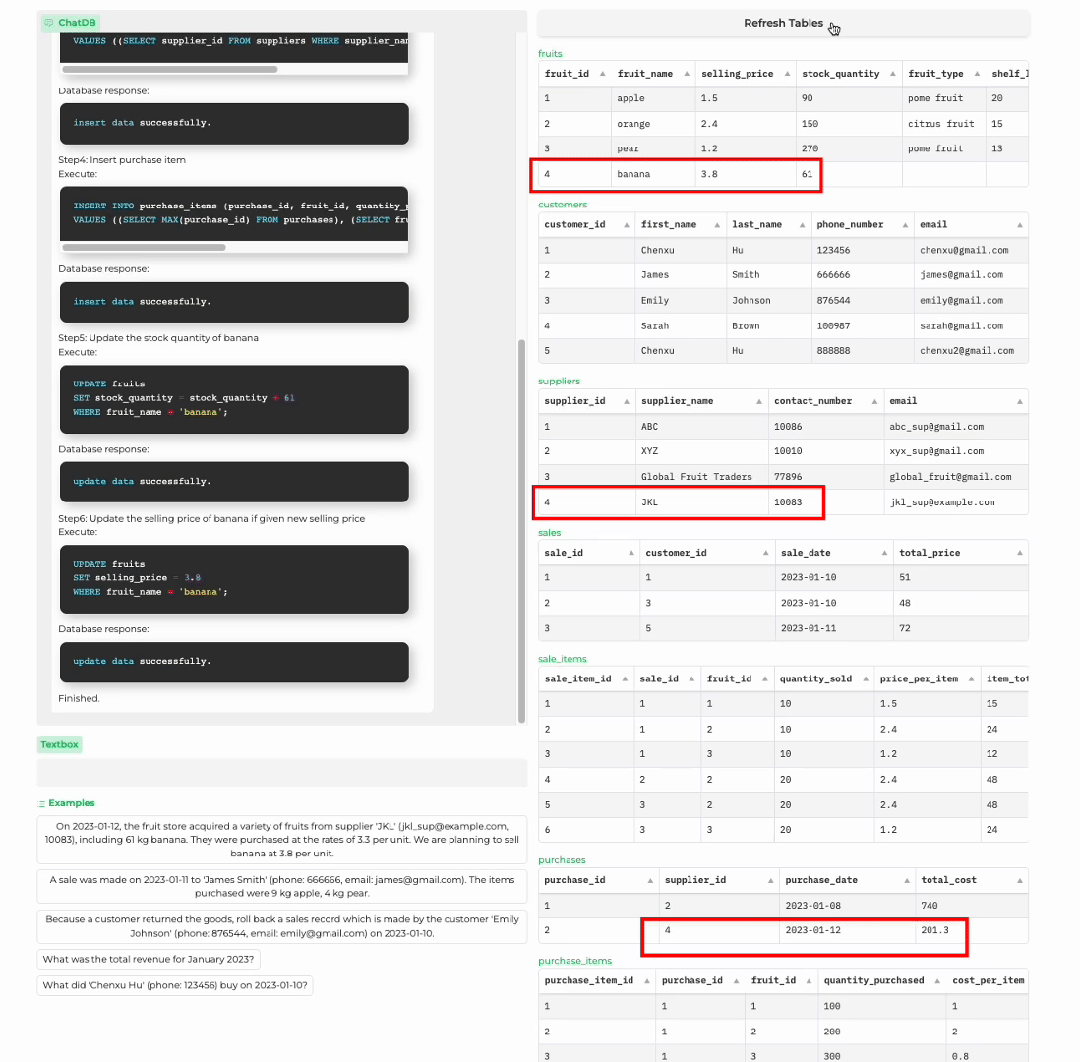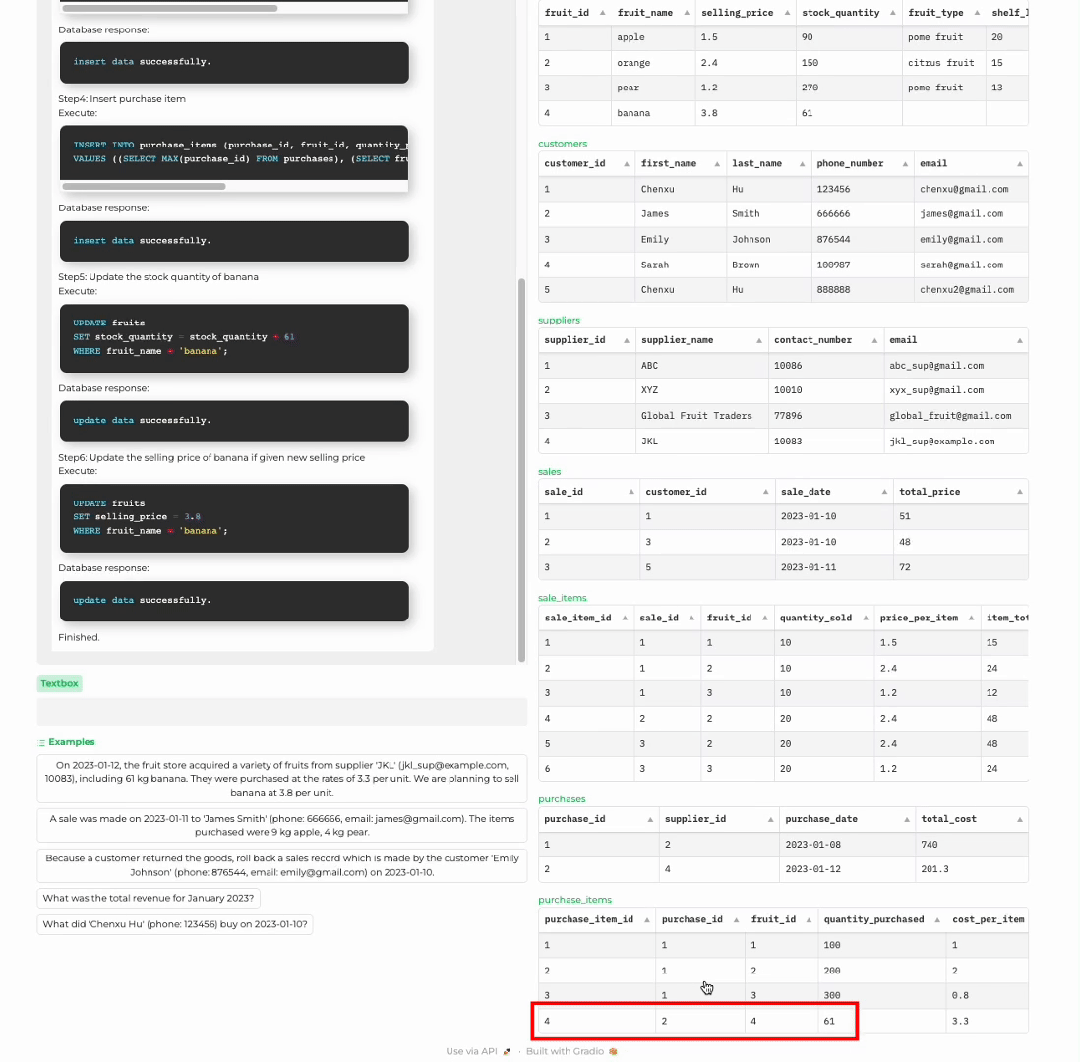
商店进货
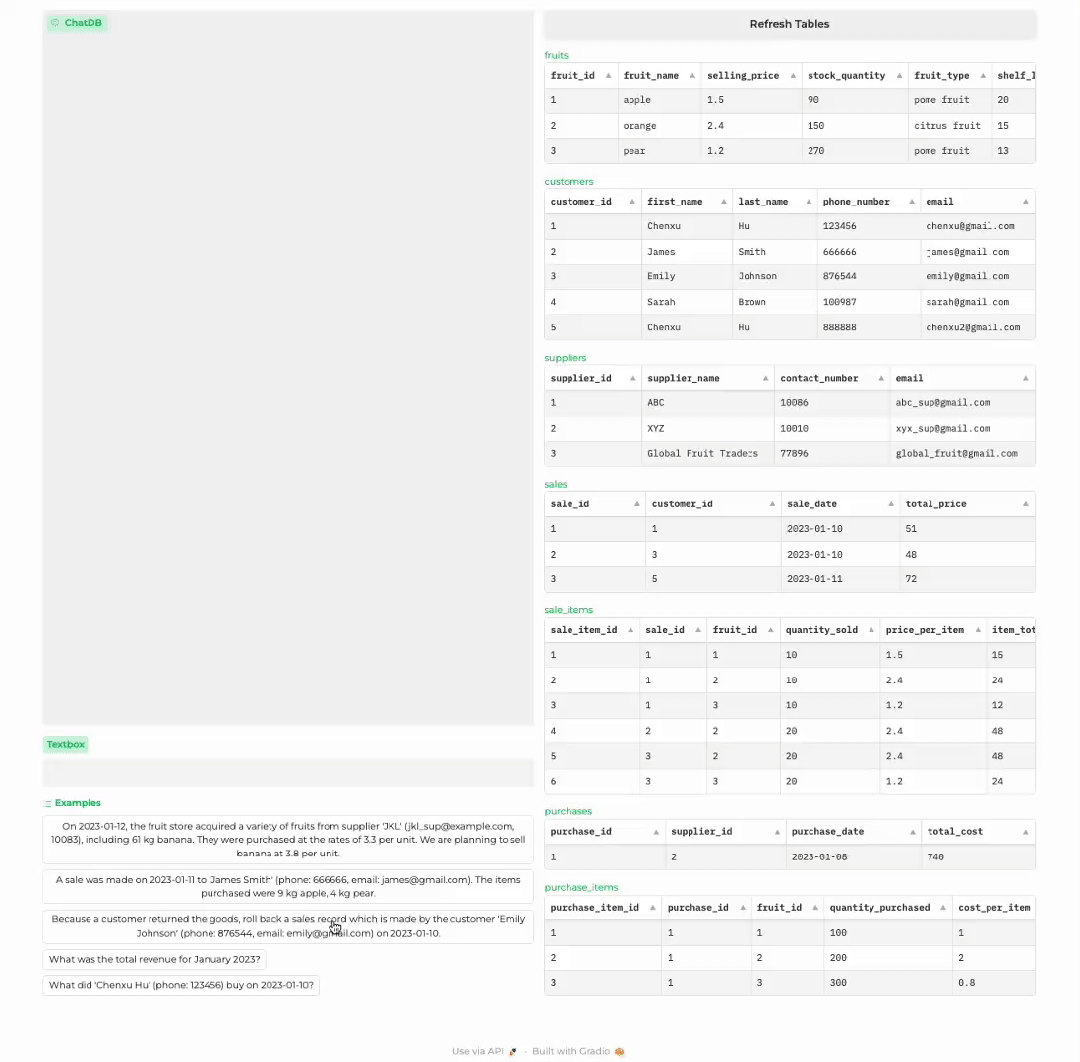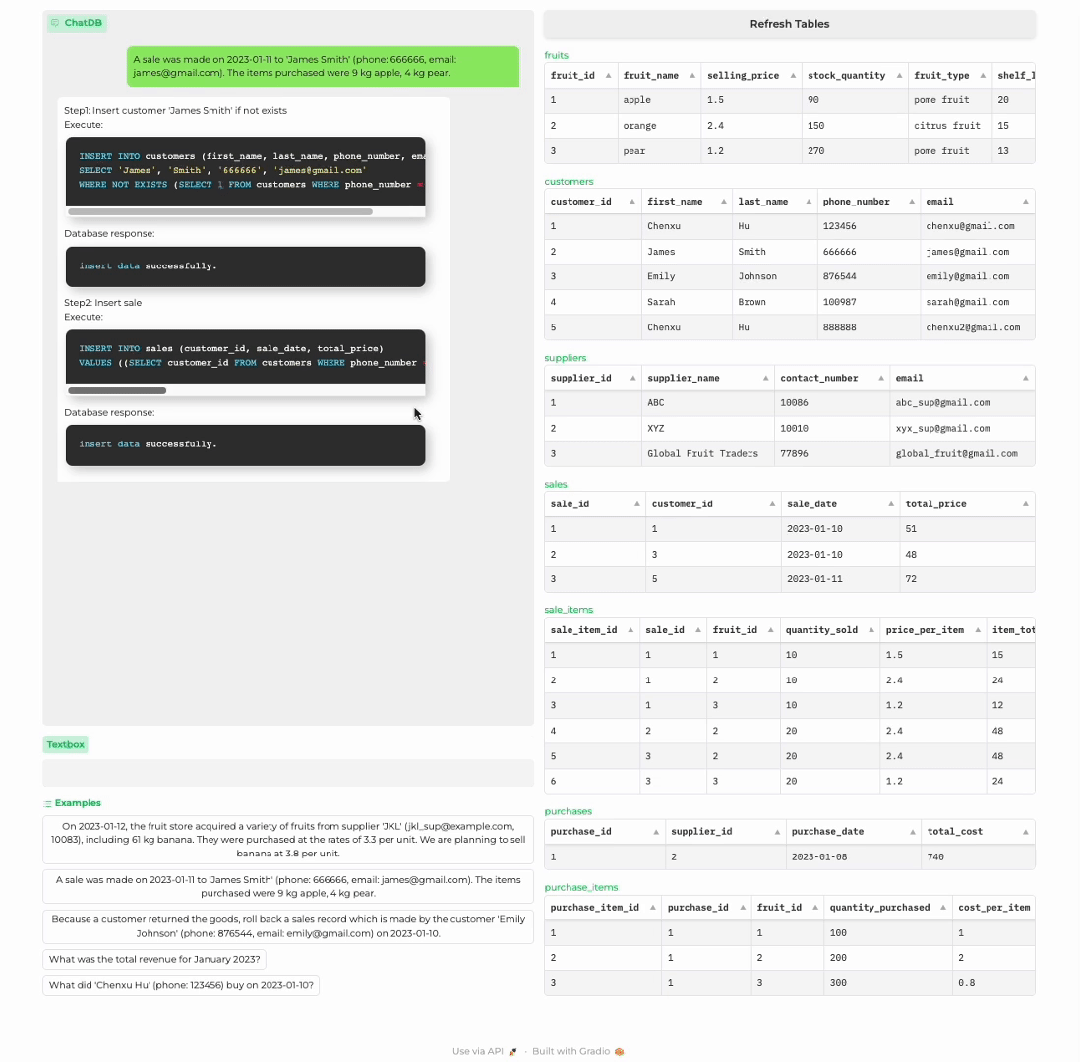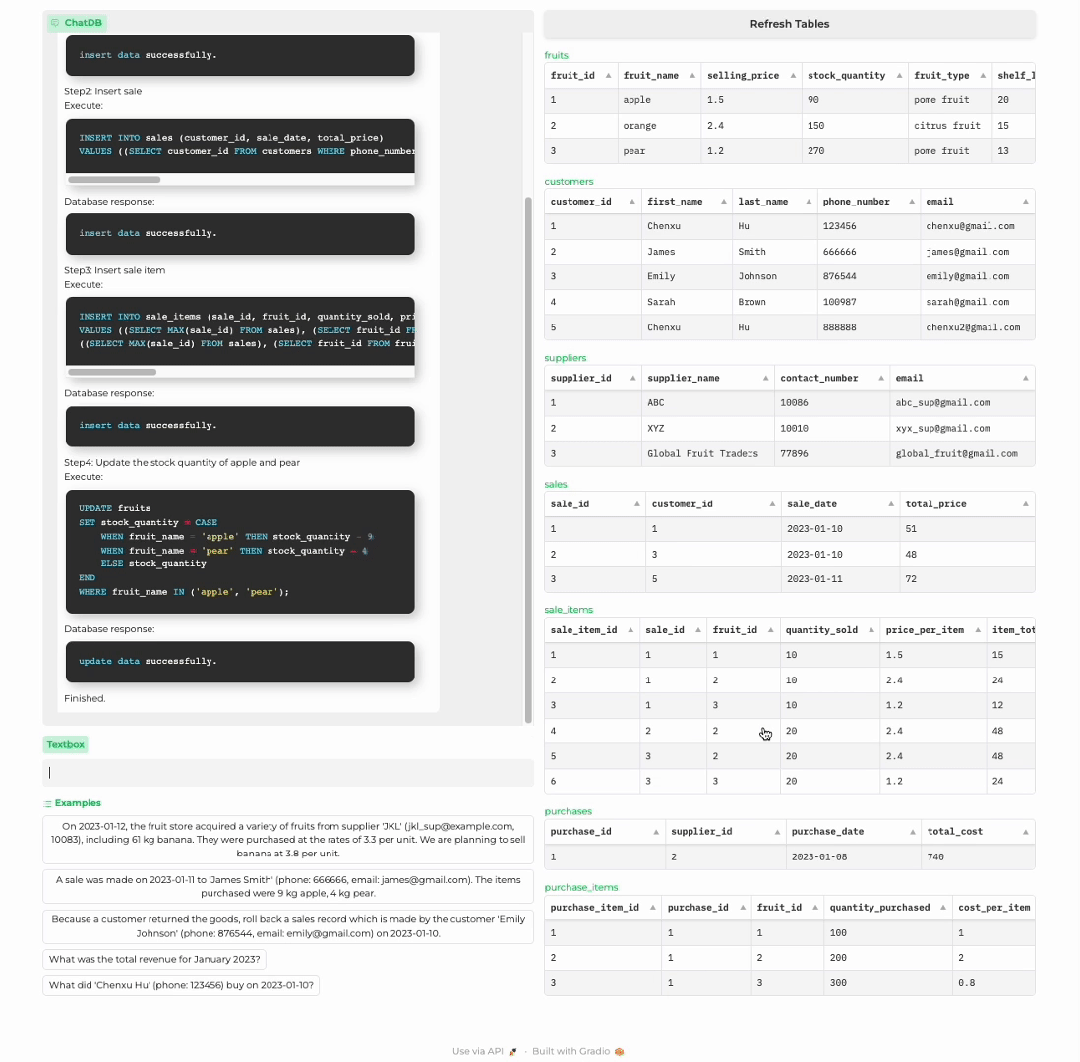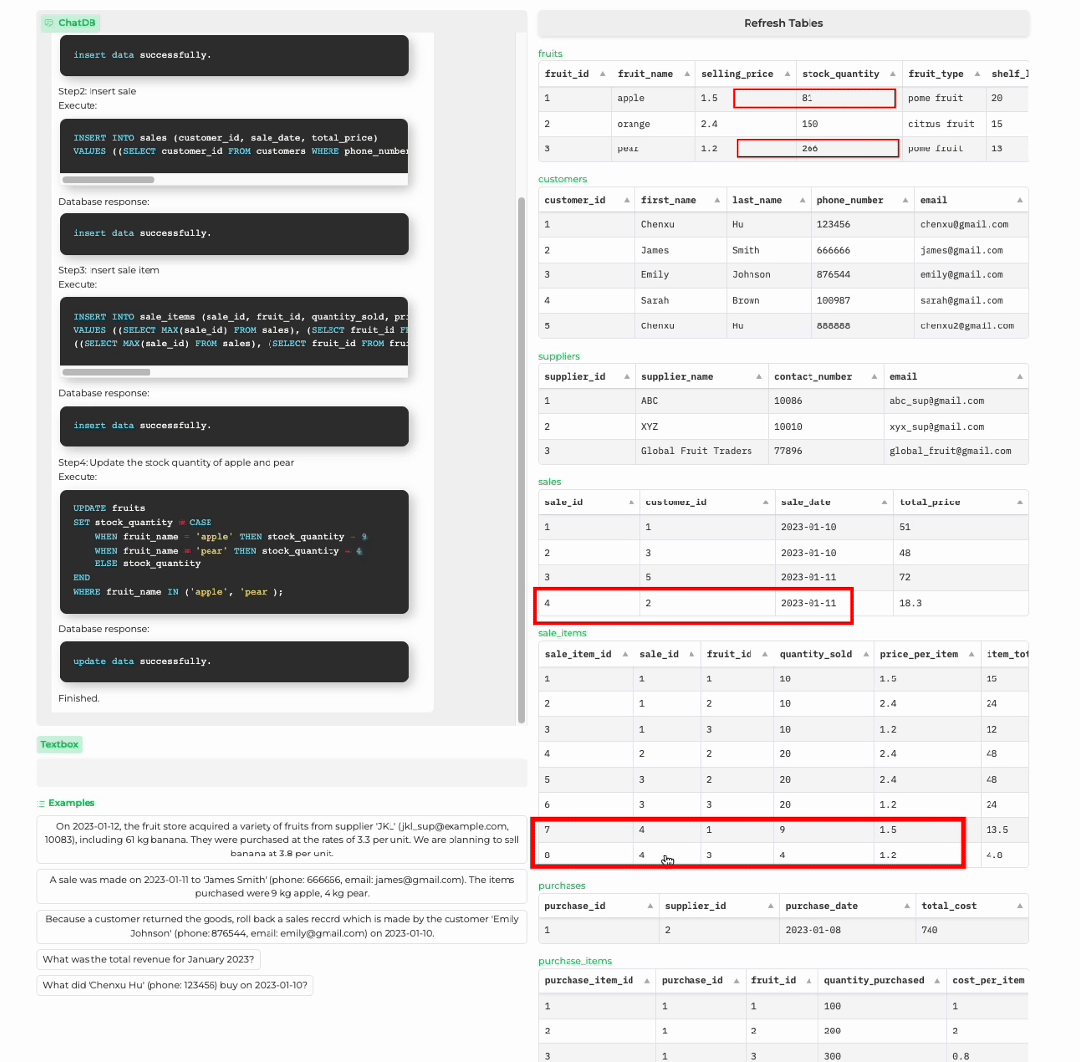
顾客购买商品
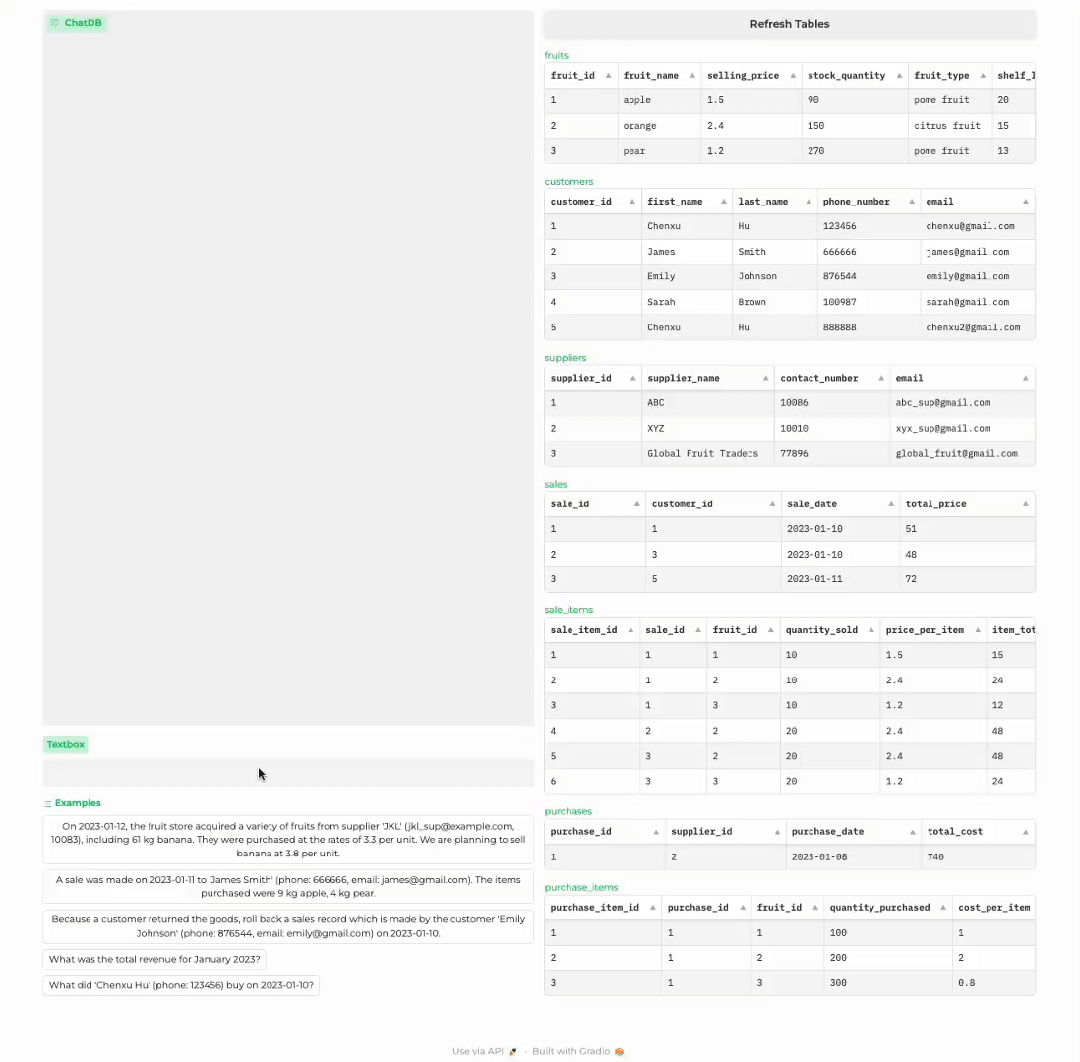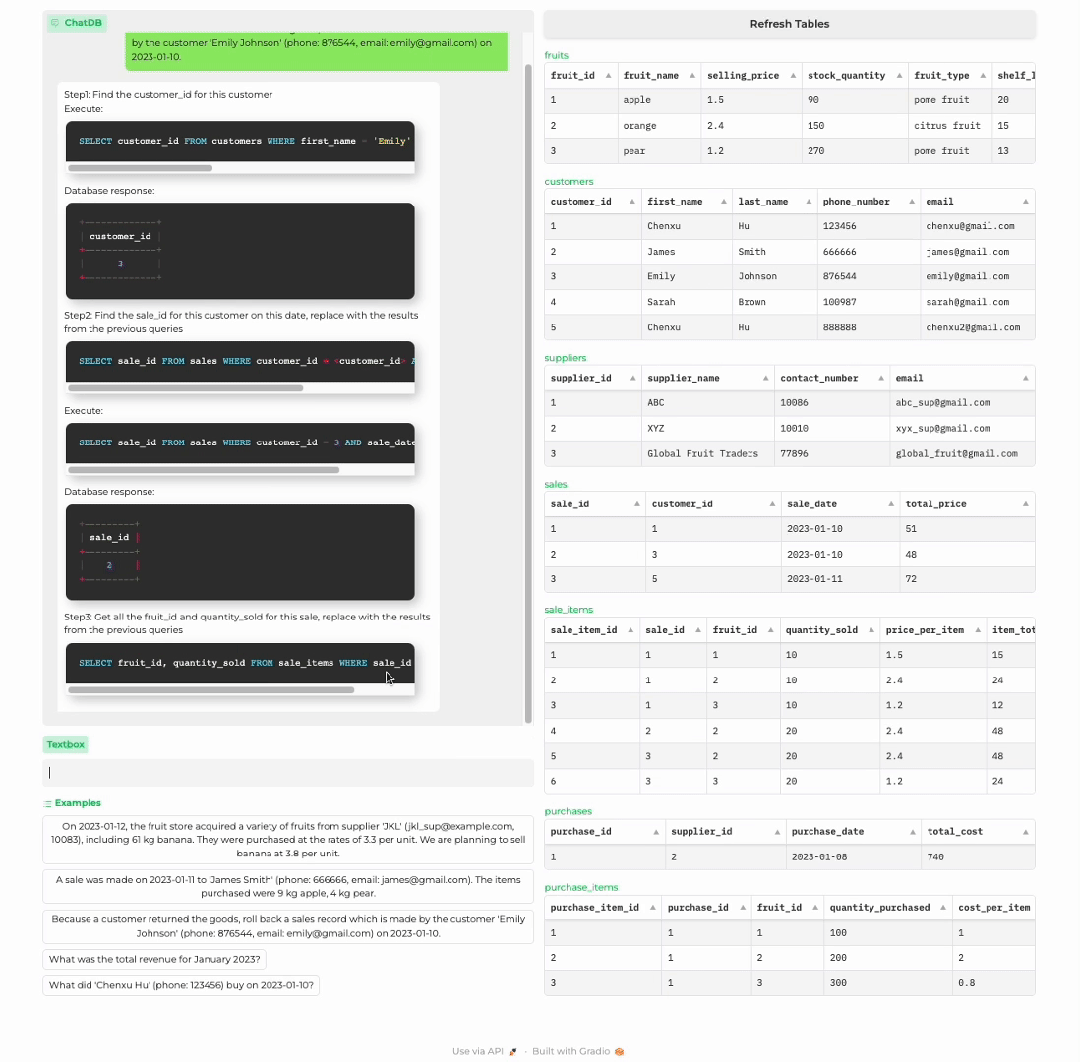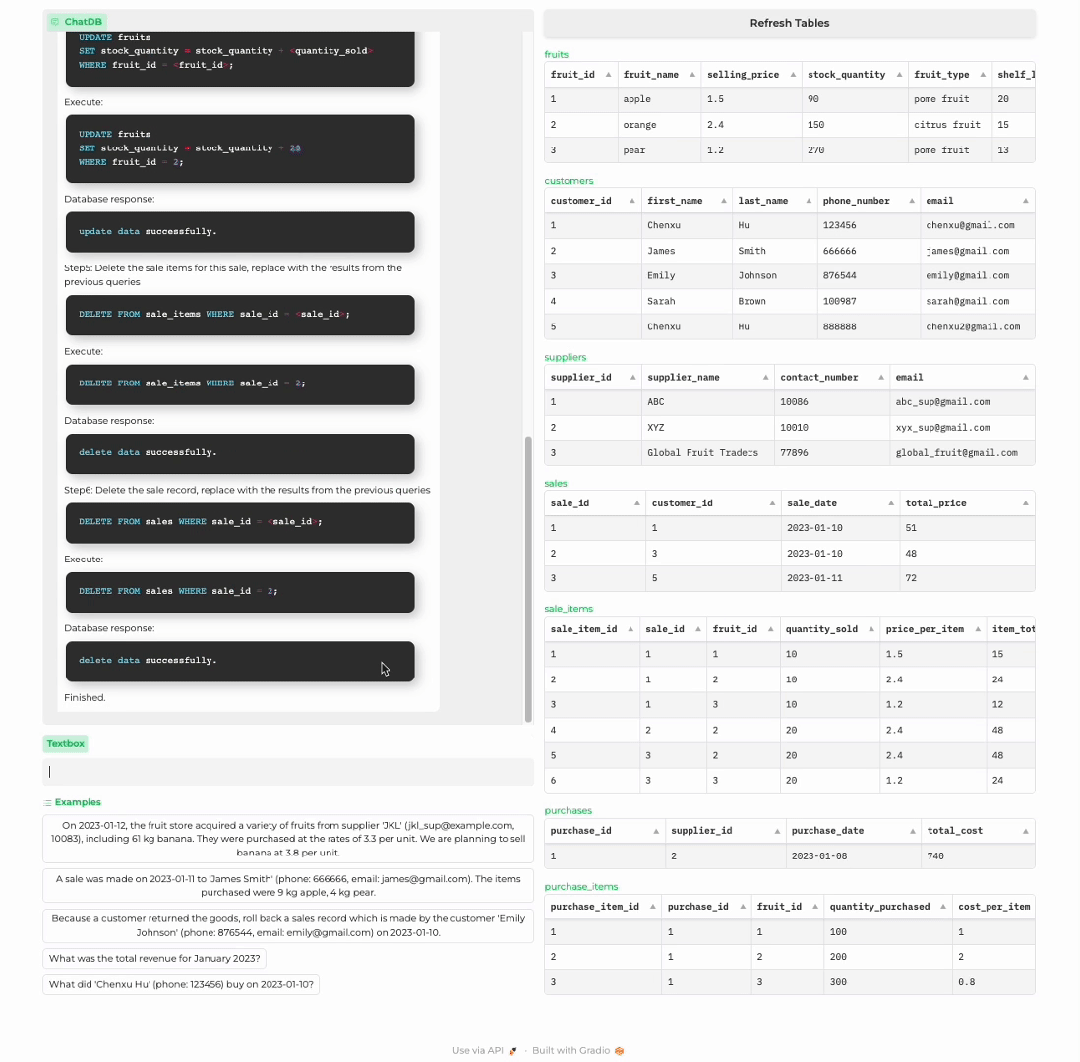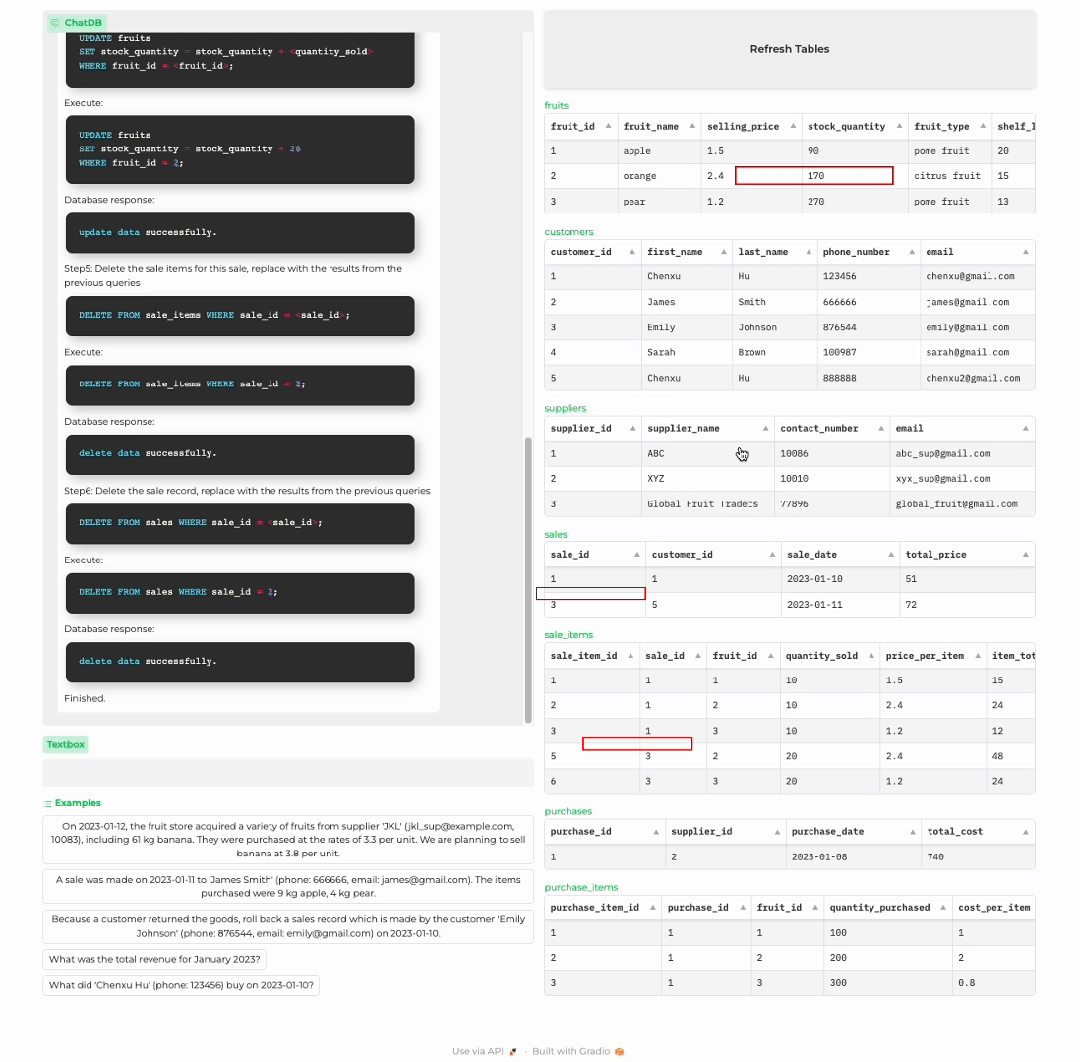
顾客退货
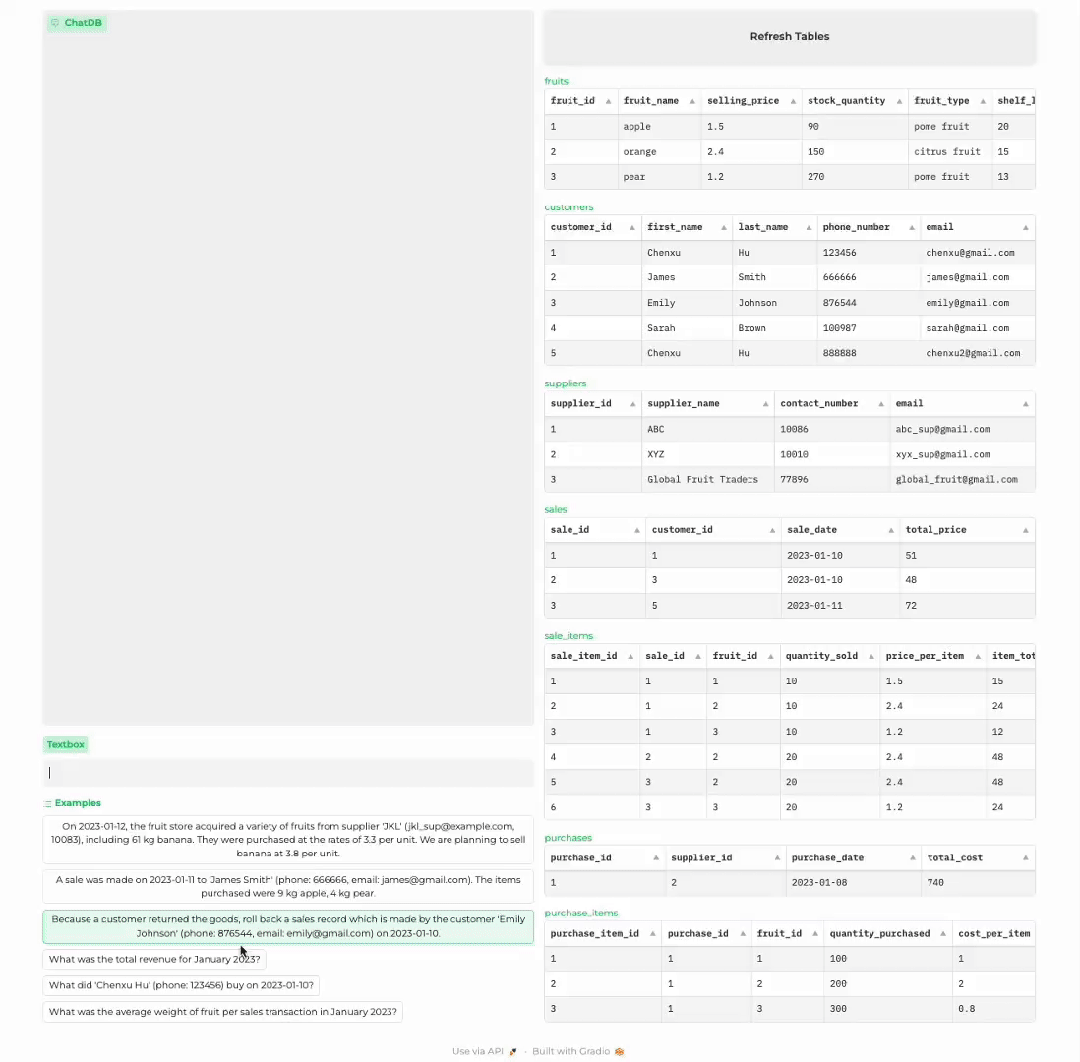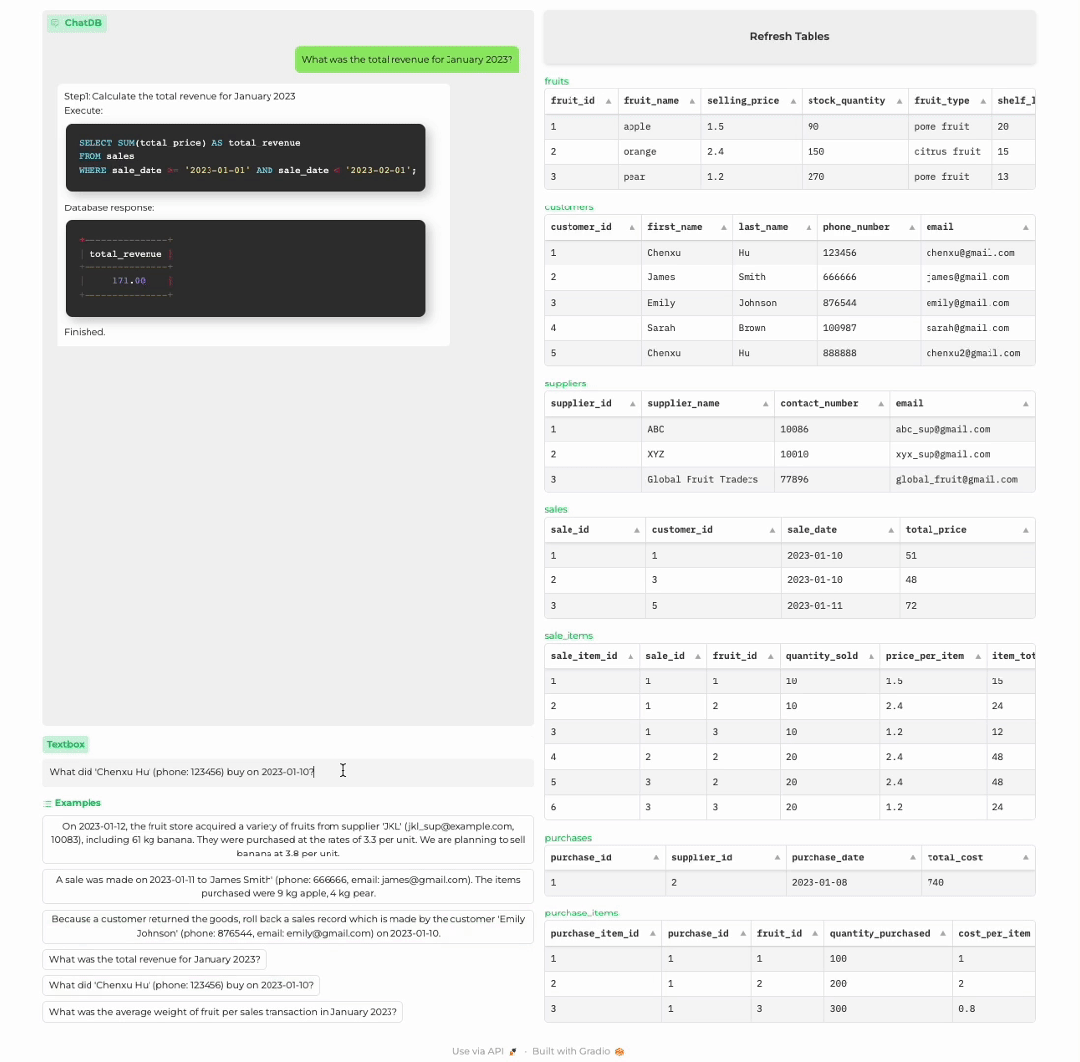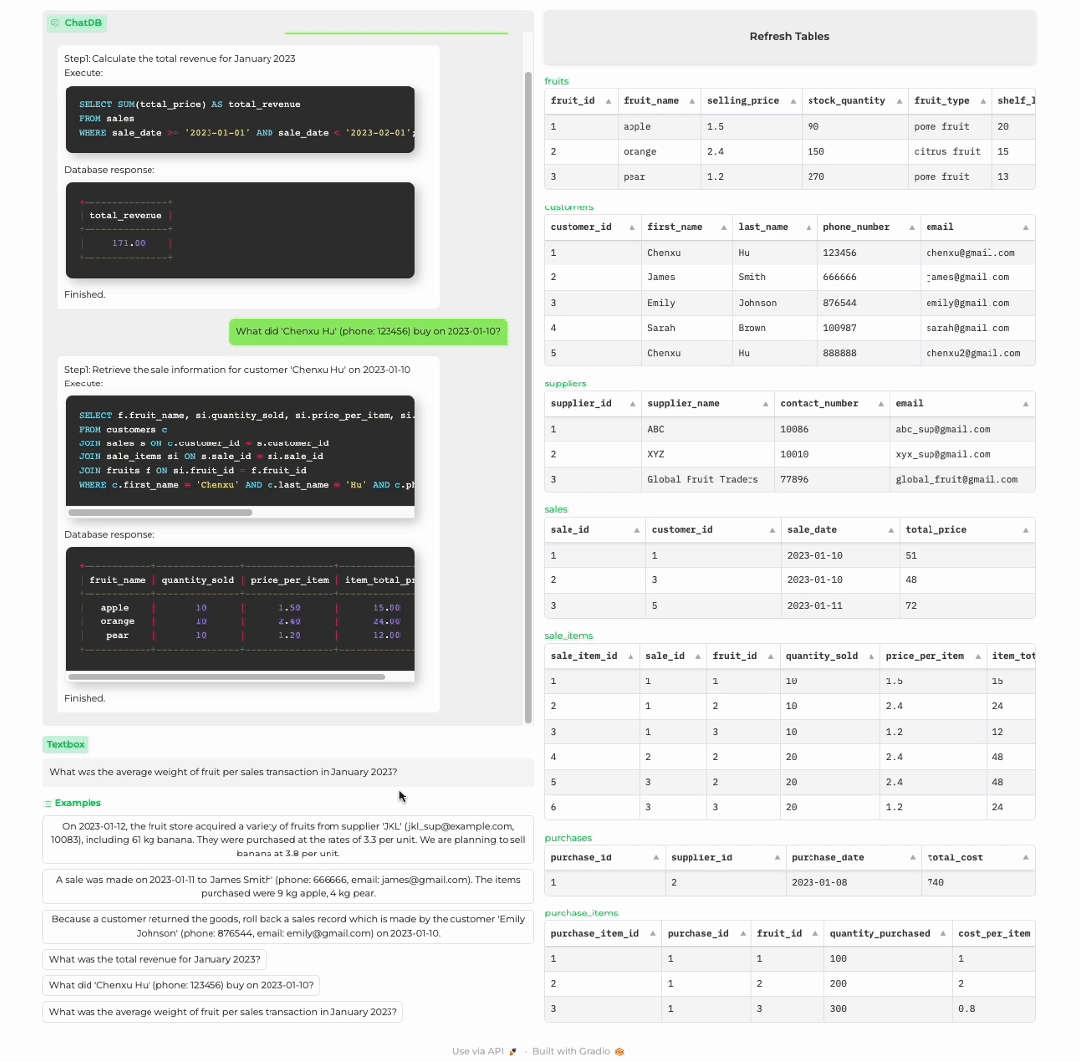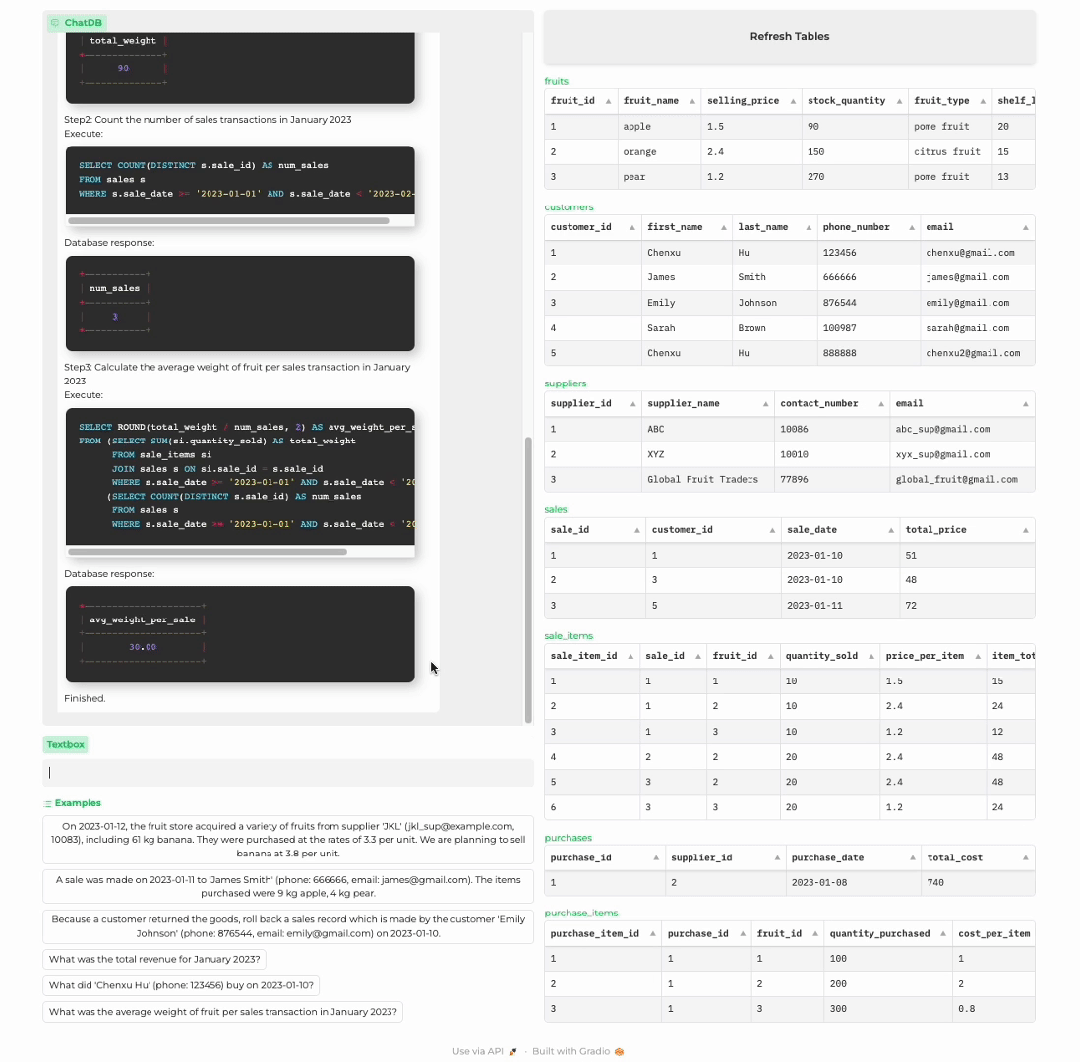
分析商店历史记录
ChatDB 交互示例:
ChatDB对水果商店数据集中四种常见操作的回应:

ChatDB和ChatGPT回答问题的示例:
这三个例子中,ChatGPT无法正确回答任何问题,但ChatDB成功回答了所有问题。

团队介绍
该论文来自于清华大学 MARS Lab和北京智源研究院,论文的作者为清华大学博士生胡晨旭,杜晨壮,骆思勉,指导老师为付杰,赵行,赵俊博。
清华大学MARS Lab,是清华大学交叉信息院下的人工智能实验室,由赵行教授组建和指导。我们尝试解决一系列探索性的AI问题,并且一直在寻找新的挑战。当前我们特别感兴趣如何让机器像人一样的能够通过多种感知输入进行学习、推理和交互。我们的研究涵盖了许多基础AI问题及其应用:(1)多媒体计算, (2)自动驾驶, (3)机器人。
了解详情,请点击阅读原文查看项目主页。

