
大家好,我是风云,欢迎大家关注我的博客 或者 微信公众号【笑看风云路】,在未来的日子里我们一起来学习大数据相关的技术,一起努力奋斗,遇见更好的自己!
HDFS基本概念
- 块(Block)
- 名称节点(NameNode)
- 数据节点(DataNode)
1. 块
HDFS的文件被分成块进行存储,块是文件存储处理的逻辑单元
- 支持大规模文件存储:大规模文件可拆分若干块,不同文件块可分发到不同的节点上
- 简化系统设计:简化了存储管理、方便元数据的管理
- 适合数据备份:每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可用性
2. 节点
- NameNode
- 存储元数据
- 元数据保存在内存中
- 保存文件,block,datanode之间的映射关系
- DataNode
- 存储文件内容
- 文件内容保存在磁盘
- 维护了block id到datanode本地文件的映射关系
NameNode
NameNode:负责管理分布式文件系统的命名空间(NameSpace),保存了两个核心的数据结构,即FsImage和EditLog。
- FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
- EditLog操作日志文件记录了所有针对文件的创建、删除、重命名等操作
名称节点记录了每个文件中各个块所在的数据节点的位置信息。
名称节点运行期间EditLog不断变大的问题:
运行时,所有对HDFS的更新操作,都会记录到EditLog,导致EditLog不断变大。当重启HDFS时,FsImage的所有内容会首先加载到内存中,之后再执行EditLog。由于EditLog十分庞大,会导致整个重启过程十分缓慢。
解决方案:SecondaryNameNode第二名称节点
SecondaryNameNode
SecondaryNameNode第二名称节点是HDFS架构中的一个组成部分,用来保存名称节点对HDFS元数据信息的备份,并减少名称节点重启的时间。
SecondaryNameNode一般单独运行在一台机器上。
工作流程如下:
- SecondaryNameNode节点通知NameNode节点生成新的日志文件,以后的日志都写到新的日志文件中。
- SecondaryNameNode节点用http get从NameNode节点获得fsimage文件及旧的日志文件。
- SecondaryNameNode节点将fsimage文件加载到内存中,并执行日志文件中的操作,然后生成新的fsimage文件。
- SecondaryNameNode节点将新的fsimage文件用http post传回NameNode节点上。
- NameNode节点可以将旧的fsimage文件及旧的日志文件,换为新的fsimage文件和新的日志文件(第一步生成的),然后更新fstime文件,写入此次checkpoint的时间。
- 这样NameNode节点中的fsimage文件保存了最新的checkpoint的元数据信息,日志文件也重新开始,不会变的很大了。
流程图如下所示:

DataNode
DataNode是HDFS的工作节点,存放数据块
数据节点(DataNode)
- 数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
- 每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中
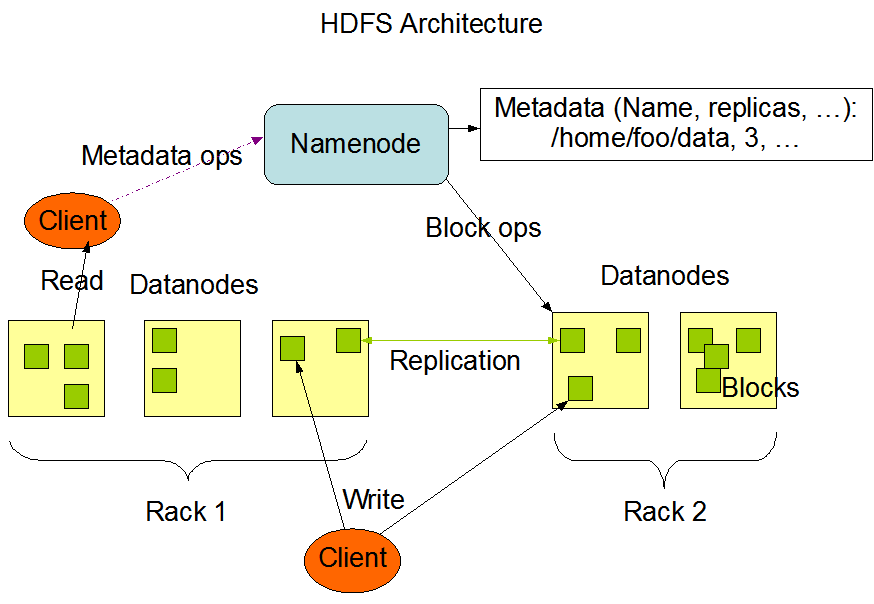
HDFS体系结构
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。
HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。
- Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。
- Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
好了,这次的分享就到此结束了,咱们下次见~~~
