

深度学习:手写反向传播算法(BackPropagation)
前置知识回顾
损失函数:交叉熵
优化方法:SGD与GD
网络结构:多层感知机是如何运作的
链式法则:
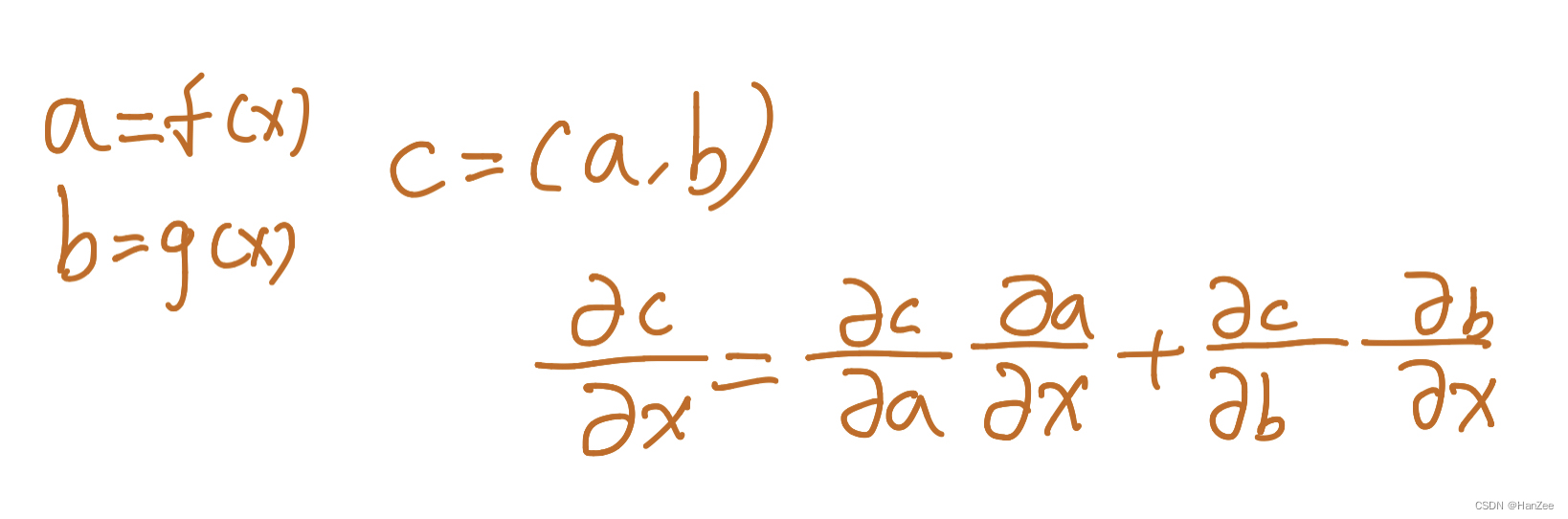
前向传播
首先定义一个简单的三层全连接神经网络,其中为了方便运算,我们省略了激活函数与偏置系数b,网络结构如图所示:
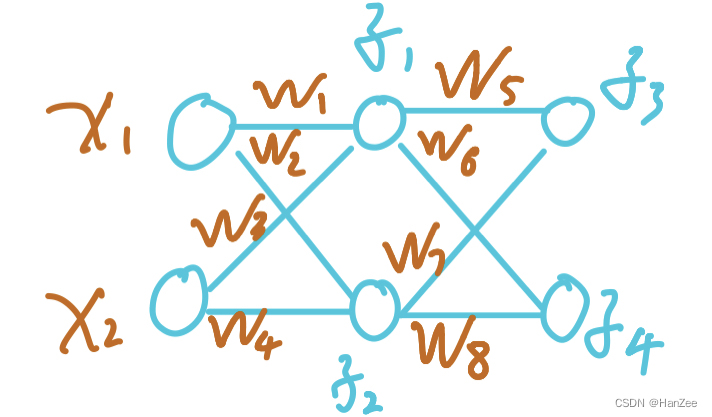
下面我们开始前向计算: 

1.在这里我们发现,其中计算的结果也就是隐藏层神经元的数值z1与z2,那么不难看出,我们把这次计算的输出当作下次计算的输入,就可以计算出z3与z4,这样逐层传播,就是上述网络的前想传播过程。
2.当我们得到网络的结果矩阵z3与z4,下面我们要通过代价函数计算损失
为了方便运算,我们采用均方误差(MSE)来计算损失计算过程如下:
其中y假设为真实值。
上述过程就是前向计算的过程。
反向传播
计算完代价函数,我们就需要更新我们的参数,之前我们学习的梯度梯度下降法只能更新一层神经网络的参数,而在多层网络中,我们需要用到链式法则的知识来得到其他层参数的偏导数,就可以逐层更新参数。具体过程如下:
我们从后往前更新参数:
首先计算损失函数对第二层网络参数的偏导数
$$\begin{vmatrix} \dfrac{\partial l_1}{\partial w_5} & \dfrac{\partial l_{1}}{\partial w_7} \\ \dfrac{\partial l_{2}}{\partial w_6} & \dfrac{\partial l_{2}}{\partial w_8} \end{vmatrix}=\begin{vmatrix}
\dfrac{\partial l_{1}}{\partial z_{3}}\dfrac{\partial z_3,}{\partial w_5} & \dfrac{\partial l_{4}}{\partial z_{3}}\dfrac{\partial z_{3}}{\partial w_7} \
\dfrac{\partial l_{2}}{\partial z_{4}}\dfrac{\partial z_4}{\partial W_6} & \dfrac{\partial l_{2}}{\partial z_{4}}\dfrac{\partial z_4}{\partial W_{8}}
\end{vmatrix}$$
计算偏导数后,我们可以通过梯度下降法更新参数(这里假设a为学习率):
$$ \begin{vmatrix} w_{5}-a\dfrac{ \partial l_{1}}{\partial w_5} & w_{7}-a\dfrac{\partial l_1}{\partial w_1}, \\ w_{6}-a\dfrac{\partial l_{2}}{\partial w_6} & w_{8}-a\dfrac{\partial l_{2}}{\partial w_8} \end{vmatrix}=\begin{vmatrix} w_{5*} & w_{7*}\\ w_{6*}& w_{8*} \end{vmatrix} $$
接着,我们就继续向前跟新,这里损失函数对参数的偏导数为:
$$ \dfrac{\partial l_{1}}{\partial w_{1}}=\dfrac{\partial l_{1}}{\partial z_{1}}\dfrac{\partial z_{1}}{\partial w_1}=\dfrac{\partial l_{1}}{\partial z_{3}}\dfrac{\partial z_3}{\partial z_{1}}\dfrac{\partial z_{1}}{\partial w_{1}} $$
有了偏导数,我们就可以重复上述操作,直至更新完所有参数。
代码实现
import torch.nn as nn
import torch.nn.functional as F
x = torch.tensor([2.0,2.0],requires_grad=True)
class model(nn.Module):
def __init__(self,x):
super(model, self).__init__()
self.x = x
self.fc1 = nn.Linear(2, 2)
self.fc2 = nn.Linear(2, 2)
def forward(self):
x = self.fc1(self.x)
x = self.fc2(x)
return x
x = model(x).forward()
x = x.sum().backward()



